Editor’s note: This post was originally published in February 2022 and has been updated for accuracy and comprehensiveness.
GPUs are often seen as the go-to tools for handling large and complex deep-learning models. Yet, with the right tweaks, CPUs can deliver robust performance, and at a significantly lower cost. This blog explores various strategies to optimize CPU performance for deep learning inference, aiming to narrow the CPU vs GPU gap. From optimizing runtime performance to exploring efficient neural architectures that excel on CPUs, this post is your guide to getting the most out of what CPUs have to offer for deep learning.
The Growing Computational Hunger of Neural Networks in Production
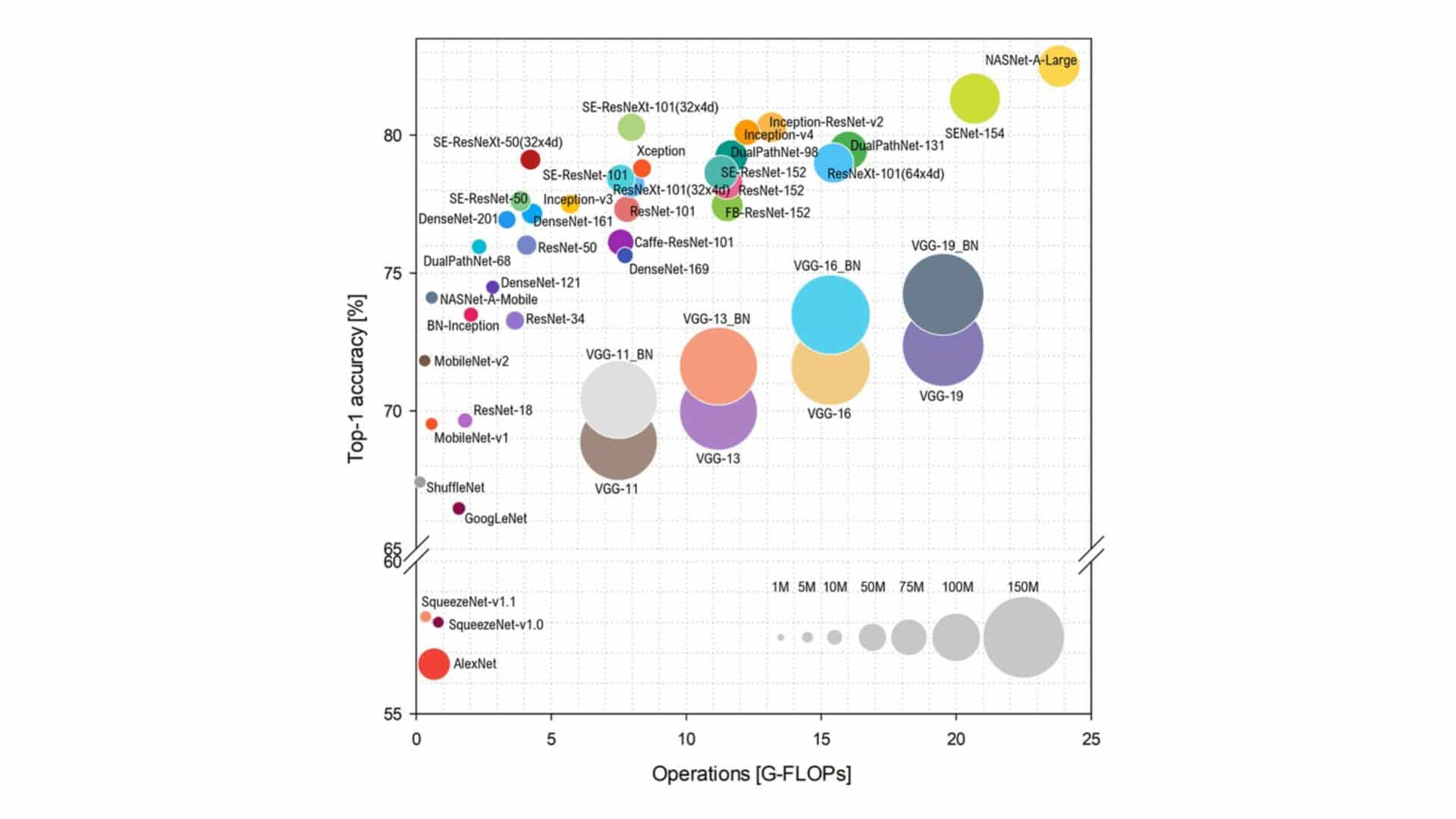
Since 2014, deep learning models have become both incredibly accurate and, simultaneously, significantly larger. This growth in size and capability means they demand more computing power, leading to potential slowdowns. This trend is driven by the fact that hardware development hasn’t kept pace with the rapid increase in model size and complexity. A look at the progression of ImageNet models from AlexNet onwards vividly highlights this shift.
Source: ResearchGate
The above graph presents a compelling visualization: the Top-1 accuracy of models is plotted on the y-axis against the number of operations (measured in gigaFLOPs) on the x-axis. The circle sizes represent the number of parameters, indicating the complexity of each model. This graph underscores the direct correlation between improved accuracy and increased computational demands. Yet, this is merely the tip of the deep learning iceberg.
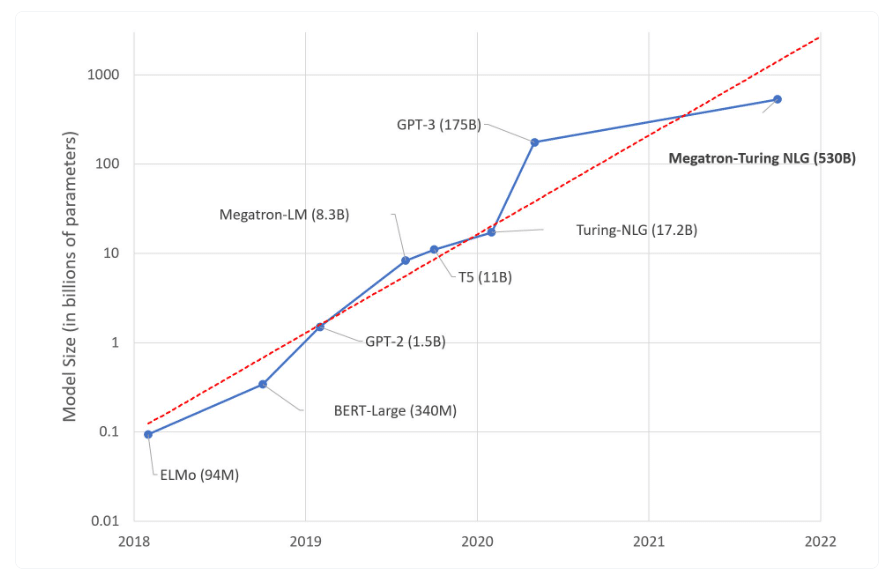
Looking at NLP models, we see that model size has increased by 10x every year since 2017. While a 1.5 Billion parameter model was considered a behemoth as recently as 2019, today’s top performers boast hundreds of billions of parameters, with GPT4 rumored to have over 1 trillion parameters. But it’s clear that accuracy is not the only consideration. As we push the boundaries of what’s possible with AI, finding resource-efficient models that maintain high performance in production becomes crucial. This balance is key to making deep learning more accessible, sustainable, and beneficial to more people.
CPU vs GPU for Deep Learning Inference
CPUs are ubiquitous and can serve as cost-effective options for running AI-based solutions compared to GPUs. However, finding models that are both accurate and can run efficiently on CPUs is not a simple task. The nature of deep learning inference, with its heavy reliance on parallel processing tasks such as matrix multiplication and batch processing, often tilts the scale in favor of GPUs. But why is this the case, and how can the CPU vs GPU gap be narrowed?
The Edge of GPUs in Deep Learning Inference
The core advantage of GPUs in deep learning inference lies in their architectural design, which is inherently suited to the parallel processing demands of AI computations. Here’s why GPUs often outperform CPUs in this arena:
- Parallel processing capabilities: GPUs are uniquely equipped with thousands of cores, enabling them to excel at parallel processing. This capability is crucial for efficiently performing matrix multiplications and other fundamental operations in deep learning algorithms.
- Batch processing capabilities: Additionally, GPUs’ ability to process multiple data points or batches simultaneously enhances both training and inference efficiency.
This dual capacity for parallel and batch processing significantly reduces computation time and increases throughput, making GPUs especially suited for real-time or near-real-time applications in deep learning.
How to Narrow the CPU vs GPU Deep Learning Performance Gap
To narrow the CPU vs GPU deep learning performance gap, we need to understand the different components that affect the runtime performance of the model: the architecture of the model, the target inference hardware, model compression methods such as quantization and pruning, and runtime compilers such as OpenVino, which can help optimize the connection between the software, network, and target hardware.
Selecting a Model that’s Optimal for Your Target CPU
Most of the time, the hardware is not a moving part and is predetermined by the end-use application and business needs. However, it is important to note that models may perform differently on different hardware. Look at the following graph.
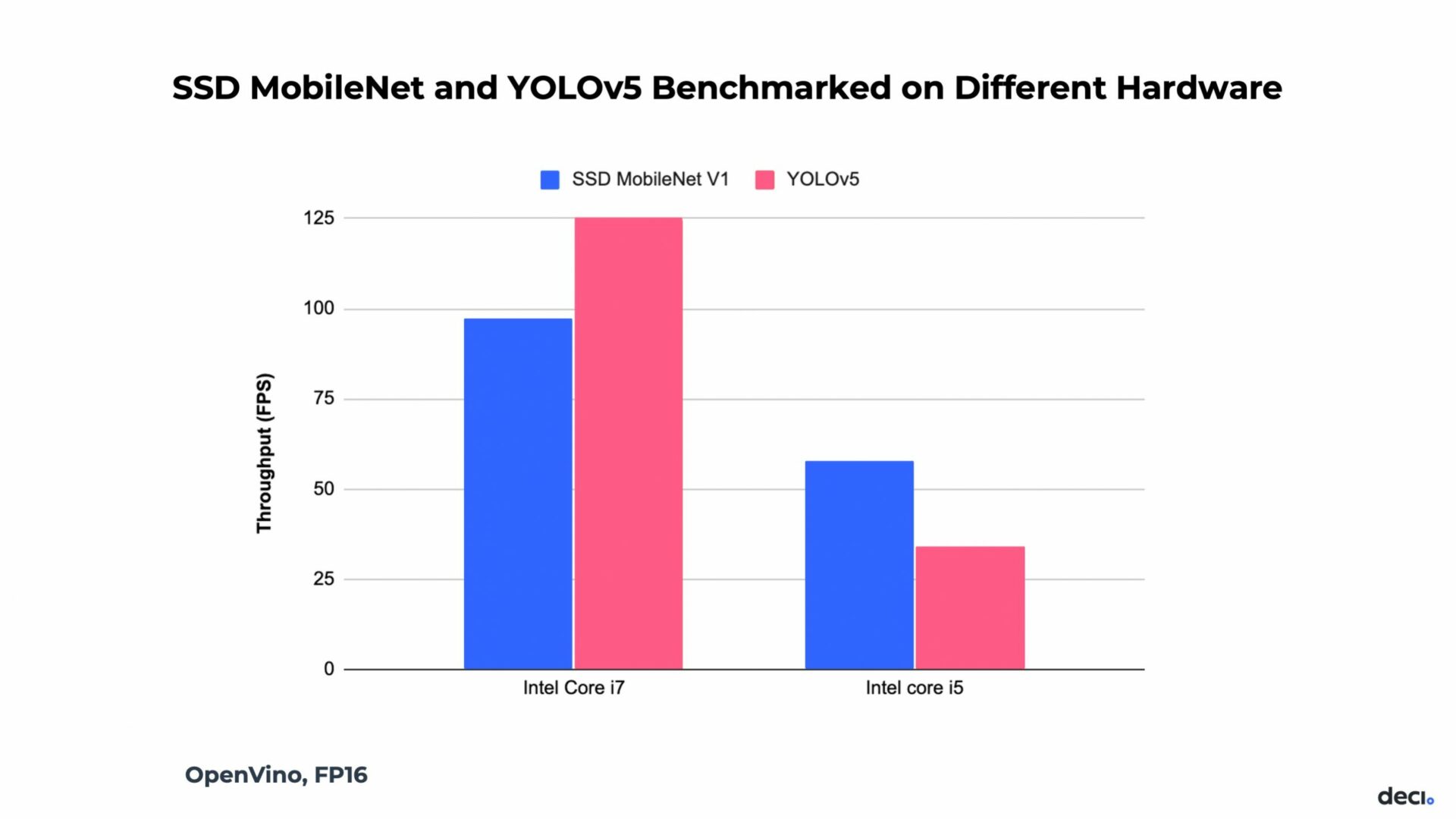
We benchmarked two detection models, the SSD MobileNet and YOLOv5 on two different CPUs. You can see that on an Intel Core I7, YOLOv5 is faster in terms of throughput. But on the Intel Core I5, the SSD is faster.
An important tip: In cases when the inference hardware is already known at the beginning of the project, you should measure the runtime of your candidate architecture before you begin with training. Doing so will help you save precious training time and resources because the runtime of the model usually doesn’t change after training.
Leveraging Compilation and Quantization
Compilation and quantization techniques can improve runtime, reduce memory footprint, and minimize model size, but they don’t work in a predictable manner across all models.
For instance, one would assume that compressing a model by half would make it twice more efficient. This is almost correct if you only consider the model size.
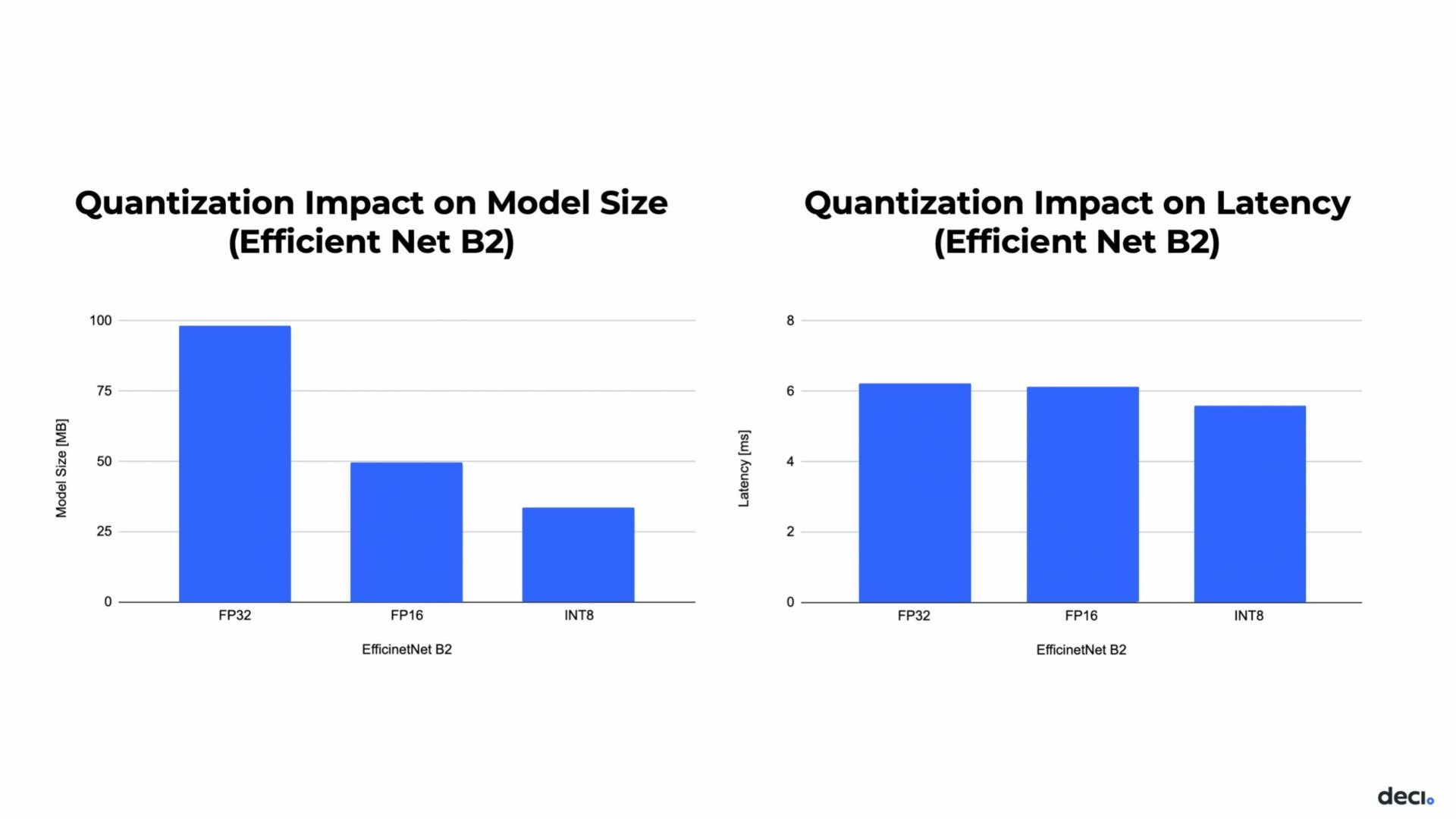
The graph on the left shows the model size for EfficientNet-B2 compiled on OpenVino with different quantization levels. The model size decreases by a major factor with each quantization. However, quantization doesn’t have the same effect on model latency. On the right graph, the latency of EfficientNet-B2 has negligible improvement when quantized to FP16, and even to INT8.
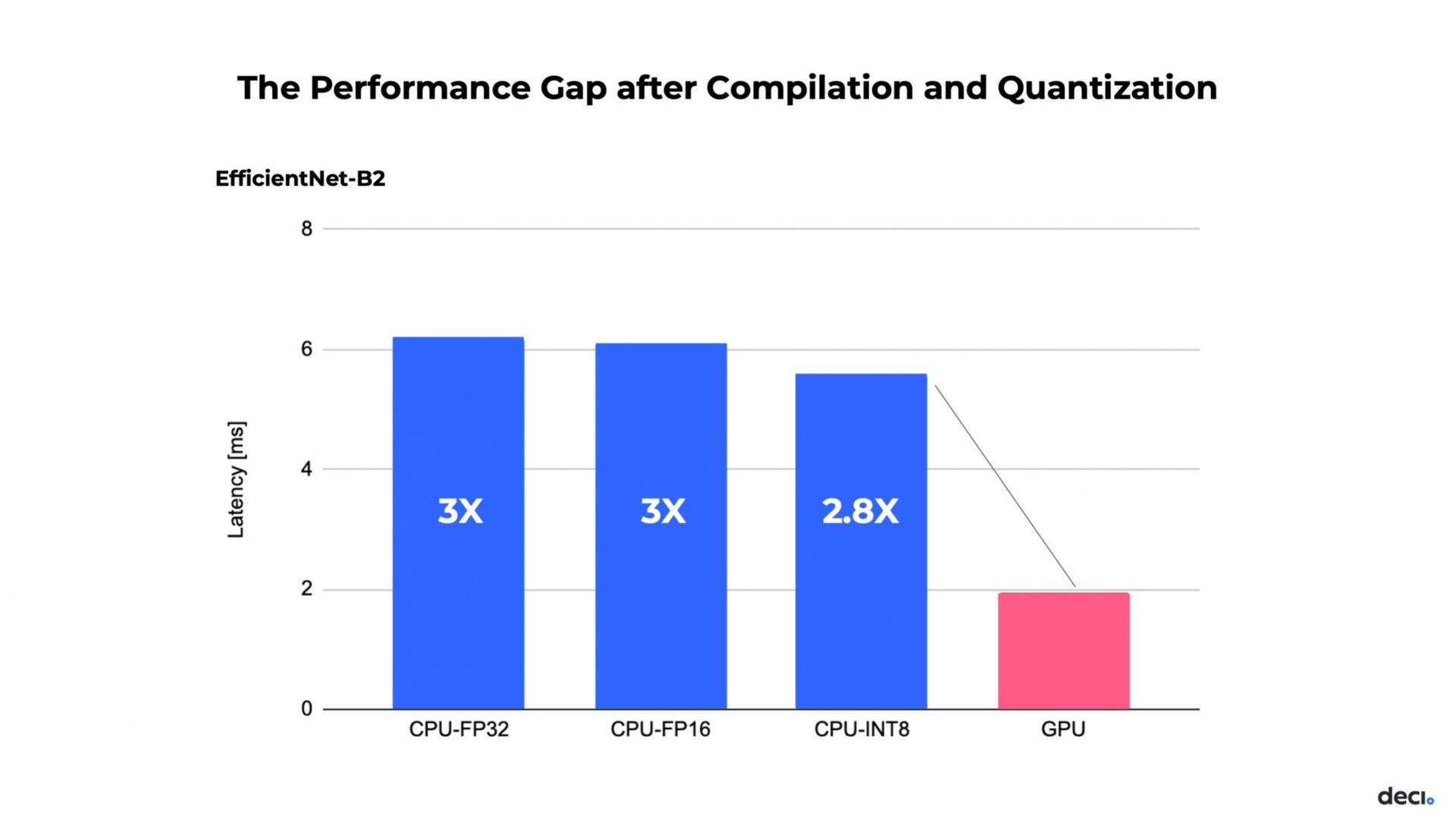
In other words, there is a limit to what hardware can do with quantized models. However, using compilation and quantization techniques can help narrow the CPU vs GPU performance gap for deep learning inference. As seen below, post-compilation and quantization, the performance gap, measured in latency is reduced to a 2.8X difference.
Many factors and parameters can have a dramatic impact on your inference performance. Each parameter has different needs that can pull the inference performance in different directions. Therefore, it is crucial to probe all the different parameters when you develop your model. You can do this manually, but there is a better way to do it.
Neural Architecture Search for Better Model Selection
Instead of manually probing all the above-mentioned factors that impact inference performance you can leverage Neural Architecture Search (NAS) for better model design. NAS is a class of algorithms that automatically generate neural networks under specific constraints of budget, latency, accuracy, and more. The common NAS approach uses reinforcement learning and is built around a controller that at each step decides on the optimal changes in each output. The MobileNet and EfficientNet models, for example, were found using a similar approach.
The problem is that this process is very expensive. MobileNet used 800 GPUs for 28 days straight, which amounts to 22,000 GPU hours. EfficientNet used twice as much, reaching 40,000 GPU hours.
Production-Aware Neural Architecture Search
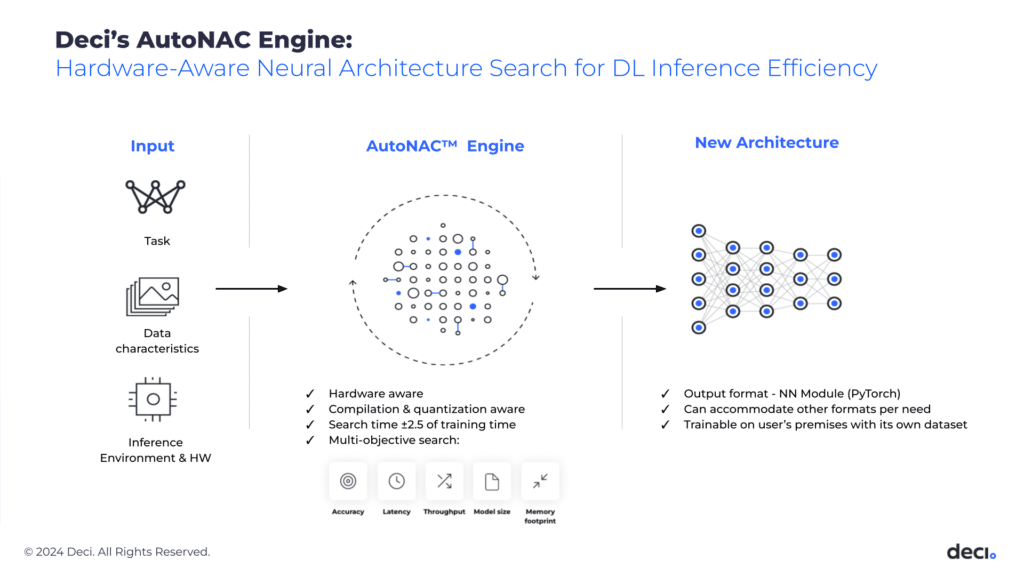
To address the cost and time constraints of NAS, you can consider the approach or solutions based on production-aware NAS. It takes as input the baseline model, data, and inference environment, and then optimizes the architecture to ensure that it meets the inference requirements in production.
Still, there is the challenge of model training, which can take up to two weeks for a single model. With production-aware NAS, specifically Deci’s NAS-based solution called AutoNAC, we can both generate a search space containing millions of architectures and estimate what would be the accuracy of the model after training.
AutoNAC is 100 times faster than the common NAS algorithms. It can run 3X to 4X faster for a single model training. Additionally, it allows the organization to have any performance objective and is applicable to a wide range of domains and tasks.

Enhancing CPU Performance with NAS-Generated Models
Having discussed different ways to improve performance using compilation, quantization, and NAS, now is the time to connect all the dots and see some examples of results that you can achieve.
CPU-Optimized Object Detection Model for a Video Analytics Application
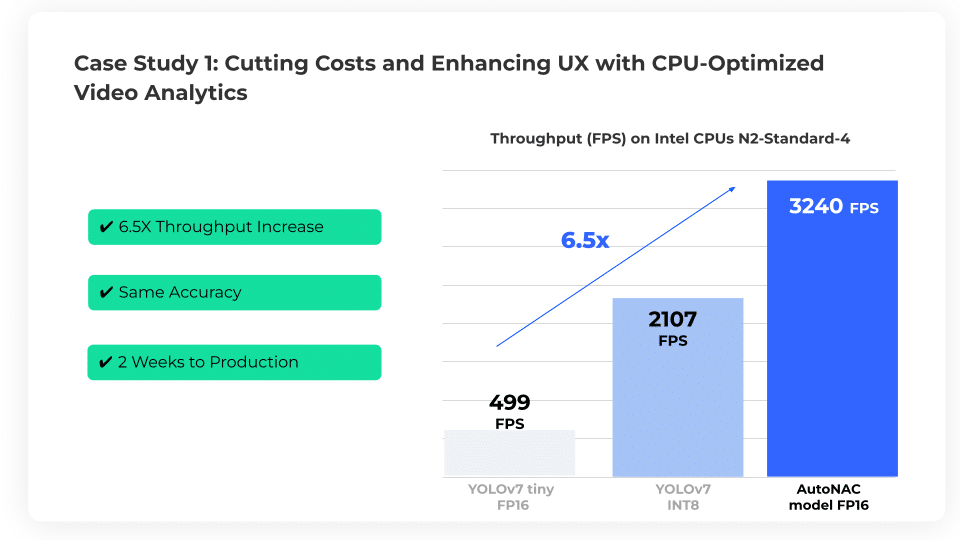
Irisity, a leading AI video analytics software provider aimed to boost the performance of their object detection model on Intel CPUs. Their objectives were to increase throughput while maintaining accuracy, benefiting their customers by:
- Reducing operational costs: Efficient scaling on existing CPU infrastructure lowers expenses
- Improving user experience: Real-time insights and alerts elevate service quality.
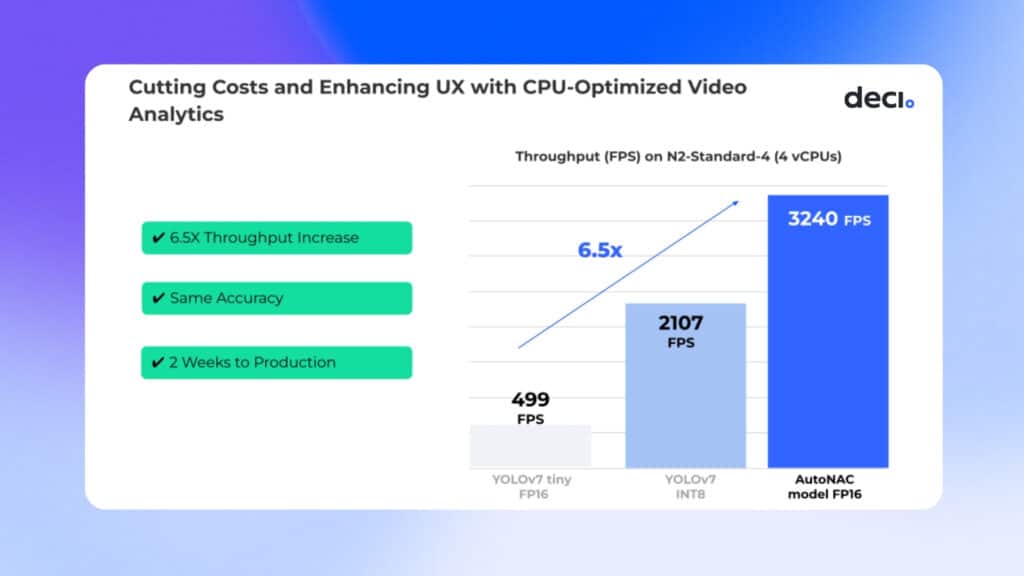
Using the AutoNAC engine, Irisity’s team developed a new model, which significantly outperformed YOLOv7 tiny in throughput without compromising accuracy. After optimizing the new model with Deci’s Infery SDK, Irisity was able to achieve a 6.5x increase in throughput over the original YOLOv7 model running on Google Compute Engine N2-Standard-4, using 4 virtual Intel Xeon CPUs.
As a result, their security application’s compatibility with various CPUs was expanded, making their product more scalable.
Using Deci’s platform reduced Irisity’s development time and minimized risks while ensuring data privacy.
State-of-the-art Pose Estimation Models on Intel’s Xeon 4th Generation CPUs
AutoNAC generated a family of pose estimation models called YOLO-NAS-Pose designed for peak performance on Intel CPUs at FP16.
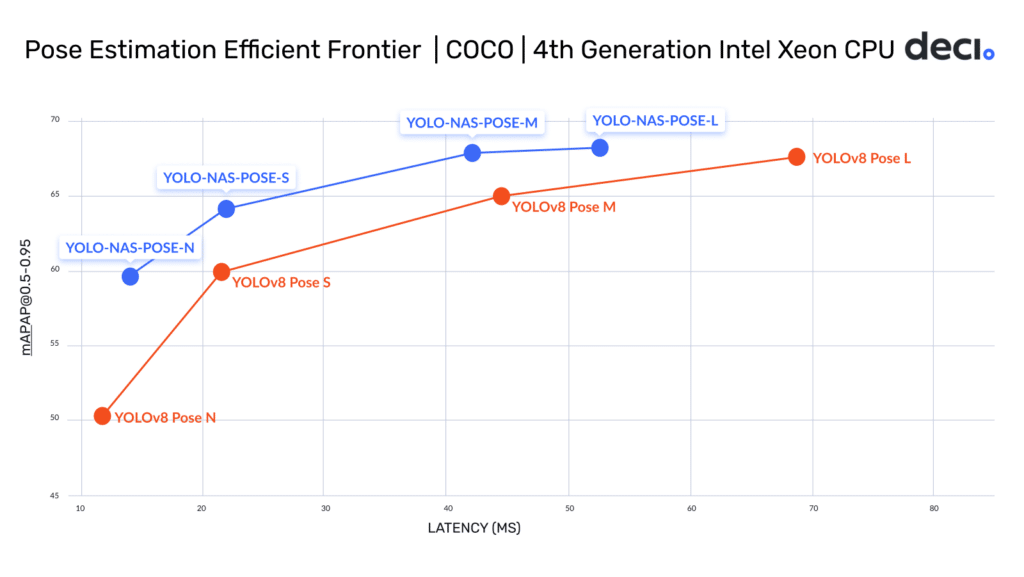
As you can see in the graph, each YOLO-NAS Pose model delivers better accuracy than the corresponding YOLOv8 Pose model and with either comparable or lower latency on the 4th generation Intel Xeon CPU.
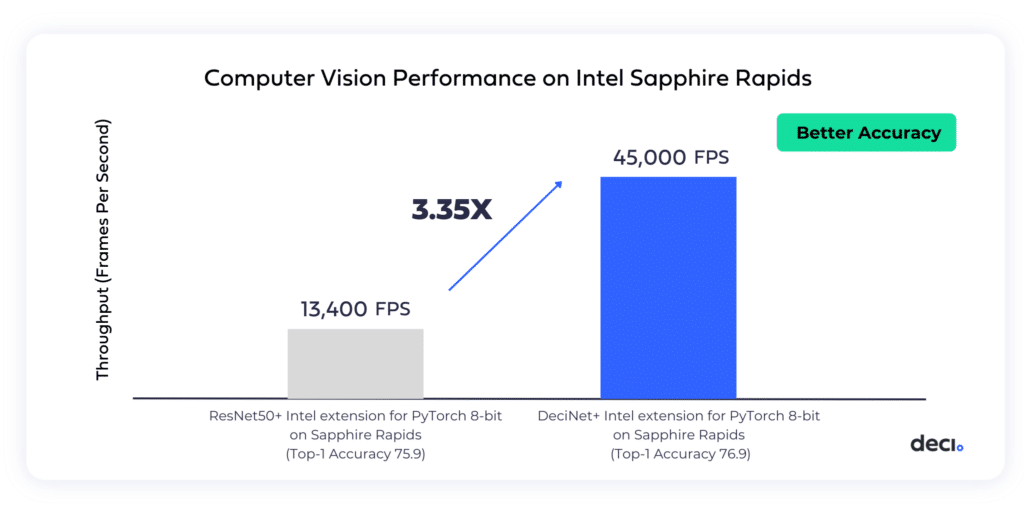
Achieving a 3.35x Throughput Increase with a CPU-Optimized Image Classification Model
We utilized the AutoNAC engine to generate an architecture optimized for image classification on the Intel Sapphire Rapids CPU. After training, the model was compiled and quantized to INT8 with Intel Advanced Matrix Extensions (AMX) and Intel extension for PyTorch. The resulting model, DeciNet, achieved a 3.35x throughput increas, as well as a 1% accuracy boost, when compared to an INT8 version of a ResNet50 running on Intel Sapphire Rapids.
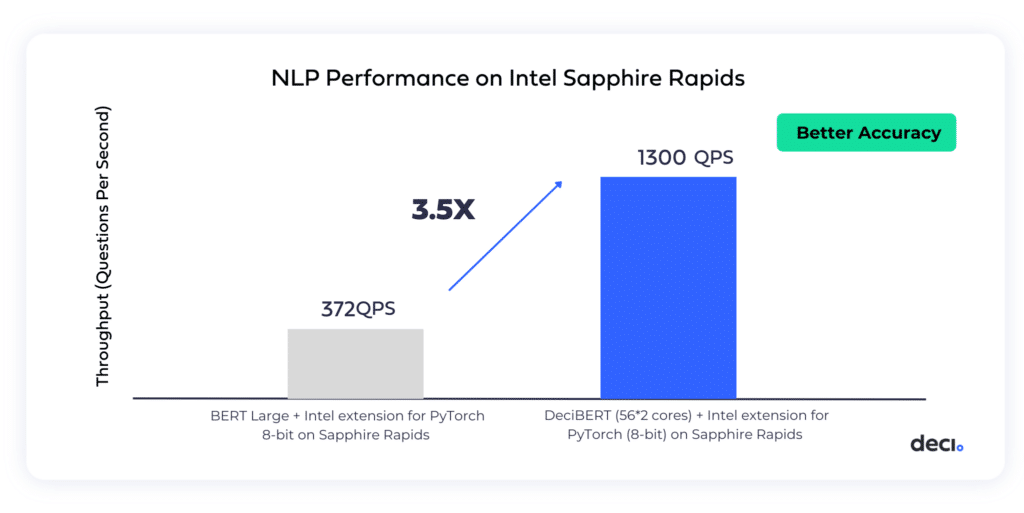
Achieving a 3.5x Throughput Increase with a CPU-Optimized Text Classification Model
For the NLP, AutoNAC generated DeciBERT. After training, the model was compiled and quantized to INT8 with Intel Advanced Matrix Extensions (AMX) and Intel extension for PyTorch. DeciBert achieved 3.5X acceleration compared to the INT8 version of the BERT model on Intel Sapphire Rapids, as well as a +0.1 increase in accuracy.
AutoNAC Can Help Narrow the CPU vs GPU Deep Learning Performance Gap
These examples show that by leveraging Deci’s AutoNAC technology and hardware-specific optimization, the gap between a model’s inference performance on a GPU versus a CPU can be reduced, without sacrificing the model’s accuracy.
How to Boost Your Deep Learning Models’ Performance on CPUs
To get the most out of your CPU for deep learning, it’s important to focus on the key factors that affect inference speed and work within your production limits. Starting with a clear understanding of hardware requirements early in the development phase can guide you toward the right model choices and optimization strategies.
Here’s how Deci can help streamline this process:
- Start with Deci’s ultra-performant, hardware-aware foundation models: Deci offers models like YOLO-NAS Pose, optimized for specific peak performance on specific hardware, including for CPUs.
- Use AutoNAC to build a custom model: If you have unique requirements, use Deci’s AutoNAC engine to create a model tailored to your needs and hardware. This custom approach ensures your model is both effective and efficient.
No matter your starting point, Deci provides a custom training recipe. With our SuperGradients training library, you can train or fine-tune your model for better performance.
After training, you can further enhance your model’s CPU efficiency using Infery, our inference optimization SDK. This tool helps your model run faster on CPUs.
For more guidance on developing CPU-optimized models, consider speaking with a Deci expert. They can offer advice and support as you navigate the process of making your deep learning model more CPU-efficient.









