The introduction of powerful low-energy devices has triggered a new era of advanced AI methods that can be run at the edge. But training and deploying deep learning models at the edge can be daunting due to the harsh restrictions associated with edge devices. How do you build a model that is not too complex or large to run on the edge device, but still makes the most of the available hardware?
NVIDIA Jetson is one of today’s most popular families of low-power edge hardware. It’s designed to accelerate deep learning models on edge hardware, whether for robotics, drones, IoT devices, or autonomous cars. In the blog “Make the Most of Your Jetson’s Computing Power for Machine Learning Inference,” we introduced the Jetson architecture, components, and utilities; we also pointed out those settings that most dramatically impact performance. This blog focuses on engineering best practices for model deployment, to help you get the most out of your models when they’re running on edge devices.
5 Best Practices for Deploying Your Model on Jetson
Based on our experience with AI model optimization, we’ve gathered the top five best practices that can help you more easily deploy your model on Jetson, while maximizing performance and minimizing costs.
#1: Optimize Your Model’s Runtime for Jetson
Our first tip is to make sure you optimize your model’s runtime using quantization, pruning, or any other method that will maximize your deep learning neural network’s performance. You can also use the Deci Lab to optimize your model specifically for Jetson. Once that’s done, it’s time to go ahead and configure your Jetson device for optimal performance.
- If you want to use the Deci Lab to optimize your model, simply upload your model and let the Lab return a Jetson Xavier/Nano model ready for production. The Deci Lab is a web platform that offers you a hub with pre-trained models and the option to optimize your own model for its target hardware–including quantization and graph compilers. You can also use the Lab to benchmark your model’s performance on different hardware and batch sizes .
- To optimize the model’s runtime for Jetson, make sure you’re carrying this out for your specific JetPack version. Keep in mind that JetPack versions are coupled with TensorRT versions. This means your TensorRT checkpoints can only be loaded on the same TensorRT version and JetPack version on which they were compiled. You can find additional information in the NVIDIA developer’s forum for Jetson.
#2: Find the Right Production Parameters for Your Inference Pipeline
Finding the right production parameters for inference, whether batch size, threads, or processes can also help make the most of your Jetson device.
- Batch size – Because Jetson has limited memory space, you’ll need a batch size that is smaller, but not so small that it adversely impacts latency. For example, if your application involves object detection, the ideal batch size should allow you to reach 30 FPS end-to-end. When working with a GPU, we strive to use a batch size higher than 1 but lower than 64; but, with the memory limitation and latency requirements for Jetson, it makes sense to keep the batch size lower than 64. Deci has automated solutions for this long and frustrating process.
- We recommend keeping the batch size small, especially if the output is large. Sometimes it’s better to use 4 replications of batch size of 2 than work with a single replication in a batch size of 8. Another option is to use the Deci Lab to find out how your model performs with different batch sizes on Jetson devices.
- Number of threads and processes – The optimal configuration or combination of these is usually achieved by trial and error. They have to live in harmony and work in concert so they don’t disrupt one another. Try to do what you can to automate this process since it’s crucial for optimal deployment on Jetson. Another option is to have Deci’s optimization find the sweet spot for the number of threads and processes on your model.
#3: Benchmark Your Application End-to-end Pipeline, not only for Inference Time
It’s easy to forget that inference is not the only thing that takes time. Jetson works differently from cloud machines. An application pipeline like the one used for edge devices is composed of operations such as pre/post-processing, data loading, data copies, aside from inference. These are all repetitive and take up time that is in addition to inference. When you do your benchmarking, remember to test your applications end-to-end, including inference time, data transfer to and from the CPU, along with pre-and post-processing.
Measuring the following metrics will help ensure a genuine and accurate benchmark time for real-world application flows and let you know where any bottlenecks are hiding:
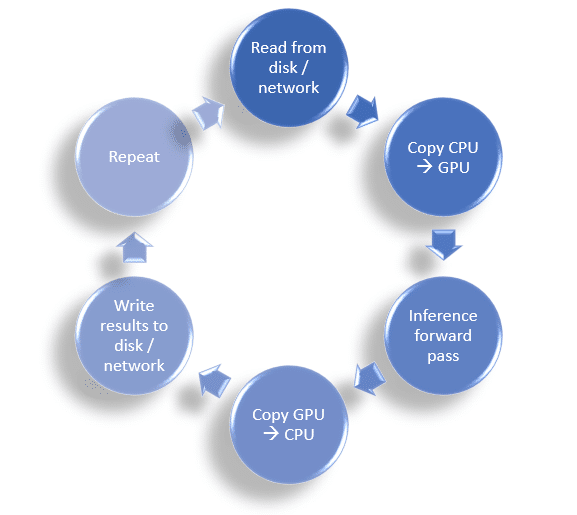
It’s also a good idea to use jtop to monitor the real-time status of your lifecycle efficiency during the application pipeline.
#4: Use Concurrent Code and Multiple Processes
One way to ramp up your code optimization is by using concurrent code and allowing multiple processes to run at the same time. This lets the application carry out analytics on more images at once, instead of just one at a time.
- Don’t be constrained by a Python-like mindset that runs line-by-line, and use an asynchronous approach whenever possible. Python is an interpreted language and we often use it to implement inference, but we rarely use it to implement a multi-process solution that uses multiple CPU cores at the same time.
- If you want better throughput, go for more parallelism. Your process can spawn multiple processes, in which each process loads the model to the GPU where each model runs inference independently.
- Don’t always go for higher batch size. One approach is to run multiple (smaller) concurrent batches by the same process, using threads. Dispatching multiple (smaller) inference requests at once might utilize the hardware better than using a single request with a higher batch size. Running multiple (smaller) concurrent batches can increase the overall throughput since it is using multiple threads and CPU cores, but the average latency for any given batch will increase.
- Take the time to find the optimal pipeline for your application in terms of the number of processes—i.e., loading data, inference, post-processing—and client threads. If you use Python (and you most probably are) you can leverage the Python Multiprocessing module to enable parallel / asynchronous code execution.
#5: Use Containers to Develop and Test Your Applications on Jetson
Because a reproducible environment can be hard to create, we found the best workaround is using containers when you develop and test your application on Jetson.
- Use a swap file. Although this may slightly compromise your ability to get an accurate reading for speed, it serves to increase the device’s fault tolerance. You can find more details on this approach in our previous blog on how to configure your Jetson device for optimal performance
- Remember to use the default Python interpreter for your version so you eliminate any risks associated with other Python versions. For example, using TensorRT in python!=3.6 will fail because TensorRT is compiled into a .so library that is only compatible with Python 3.6.
- Jetson is ARM-based and behaves differently from cloud machines. Most installations for deep learning libraries will not work out-of-the-box, because there are no pre-built binaries for them. Use containers to build and run development environments, so your original JetPack environment and operating system will not be affected by your work. This will make your daily work easier.
- It’s possible to run a new official docker image on a Jetson with an old JetPack installed. But you need to be careful with this. For instance, TensorRT (and the Jetson device drivers) will still use the bare-metal JetPack firmware. For that reason it’s important to double-check your JetPack version, even if docker is used throughout your environments.
And here’s an extra tip! Once you are done developing and testing, you can use Infery to more easily deploy your models on Jetson. The Infery Python runtime engine transforms running inference on optimized models into a light and easy process.
Easier Optimization for Better Performance
In short, deploying deep learning models on Jetson can get tricky. But once you have some best practices in hand, it becomes easier to optimize for better performance, find the parameters for production that are most cost-effective, and do your testing in a way that lets you find out what aspects of your environment are challenging. And, of course, you can always book a demo to use the Deci platform to automate your model optimization for Jetson, and then use Infery to deploy on Jetson – it’s free!