
Finding the right hardware for your model inference can be a daunting task, especially when you need to achieve optimal performance and at the same time ensure cost-effectiveness.
We know that inference performance directly influences the end user’s experience. That means it’s crucial to carefully analyse and gauge the various parameters that affect your application’s performance and ensure that the hardware selection is compatible with the application’s use case and performance targets.
Depending on what your performance goal is, you will want to consider different parameters for your hardware selection. The two examples of cloud-based applications below illustrate this relationship.
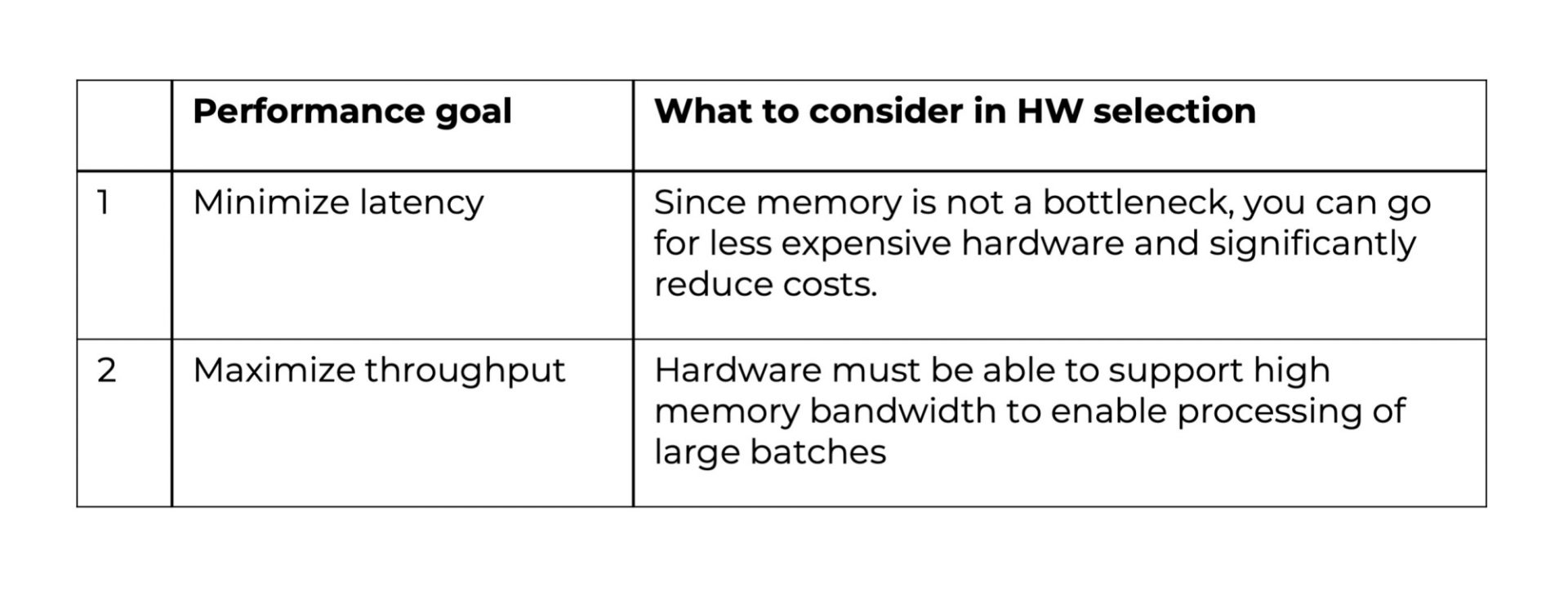
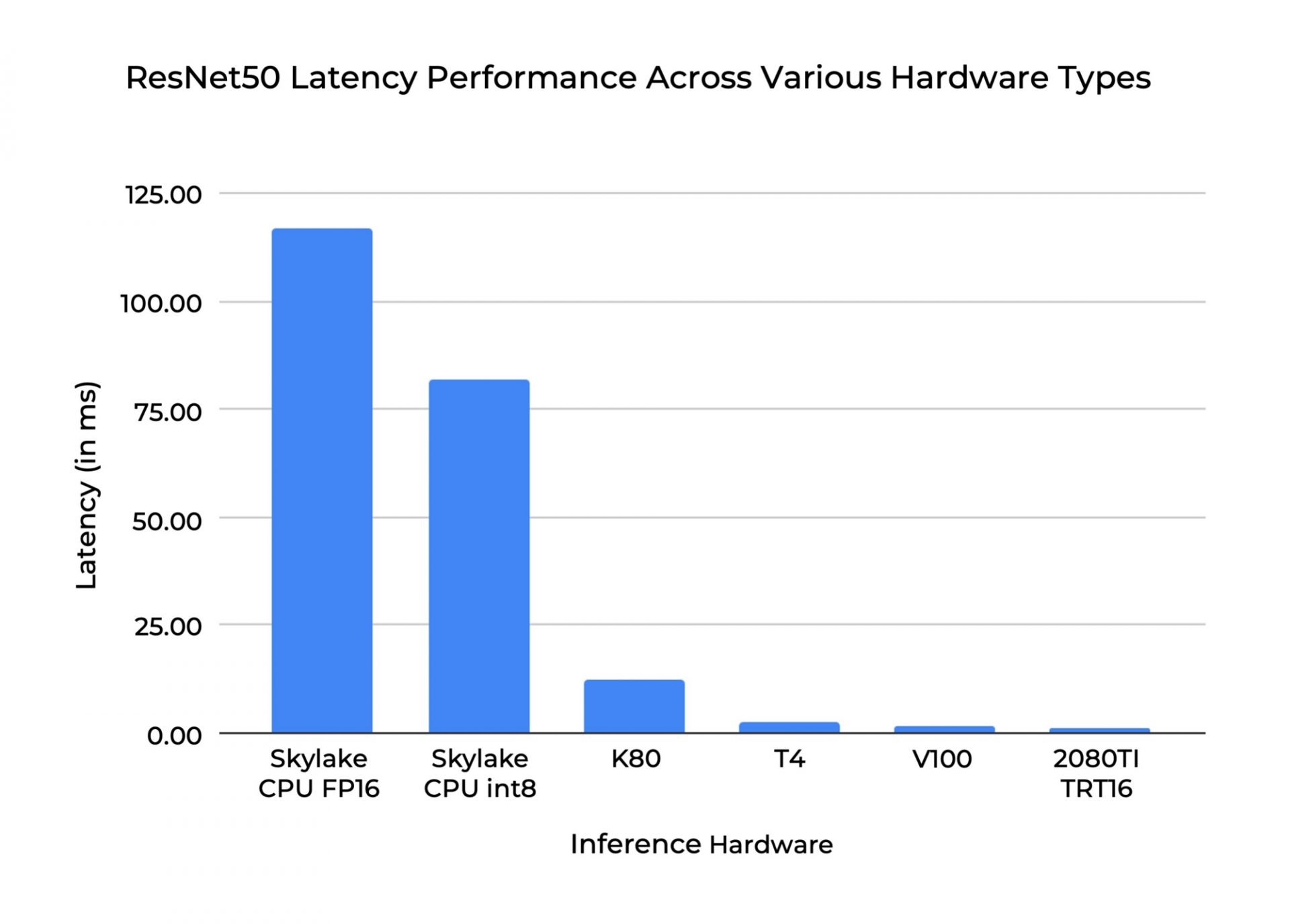
Given a model and the prices of the different hardware, you want to know which hardware can process your data within a given time and at the lowest price point. Take for example the latency performance of ResNet-50 across various hardware. When deployed on the Skylake int8 CPU, its latency is 116 ms, but when running on the 2080TI TRT16, the latency is 1.27ms! This is an enormous difference in terms of performance.
 Clearly, benchmarking your model’s performance across various types of hardware is a crucial step when it comes to choosing the best hardware for your performance targets. That said, manually experimenting with different inference hardware for your model and performing critical analysis against different criteria can be a tedious process, not to mention a costly one. This is where Deci’s platform can help by automatically comparing your model’s performance across different hardware, while taking into account parameters such as cost, latency, throughput, and model size.
Clearly, benchmarking your model’s performance across various types of hardware is a crucial step when it comes to choosing the best hardware for your performance targets. That said, manually experimenting with different inference hardware for your model and performing critical analysis against different criteria can be a tedious process, not to mention a costly one. This is where Deci’s platform can help by automatically comparing your model’s performance across different hardware, while taking into account parameters such as cost, latency, throughput, and model size.
4 key parameters to consider when you select hardware for inference
#1: Model throughput
In the context of deep learning models, throughput can be defined as the number of data units that can be processed in a single unit of time.
For instance, the throughput of a deep learning model that classifies images can be referred to as the number of images that the model can process in a unit of time. Typically, the unit of time is one second. Thus, frames per second (FPS) would be the unit of throughput for such a deep learning model. The Deci platform can compute and benchmark the model throughput in FPS, offering you a way to measure the efficiency of any deep learning model.
On a GPU or CPU device, the throughput potential of the model really depends on its ability to work with large batches. Because running the same model on different hardware will deliver a range of throughput performance, it’s essential to check that the inference hardware that you select can support your target throughput performance.
#2: Model latency
In the context of deep learning models, latency is the time it takes for inferencing and is a function of batch size. When it comes to computer vision, latency can be defined as the time it takes to process one image, and is measured in seconds or milliseconds. The Deci platform can compute and depict the latency of a deep learning model in milliseconds. This provides a vital indication of your deep learning model’s efficiency, especially when it comes to real-time applications where low latency is a must.
Different hardware devices have different rates of floating point operations per second (FLOPS), which affect the latency of the model. Choosing the correct hardware will have a significant impact on the latency performance of your model (as seen in the above chart). Setting a clear latency target and benchmarking it across various hardware before deployment will also help you make the right decision.
#3: Model memory usage
In the context of deep learning model performance, the model memory usage is defined as the ratio of the memory footprint occupied by the model to the actual memory capacity of the hardware. The model memory usage is a function of the batch size of a deep learning model among other factors such as model architecture. In short, a more efficient deep learning model will have a relatively low model memory usage.
When it comes to choosing the right hardware for your memory usage needs, there are several questions you should ask yourself:
- What is the size of my model in terms of memory?
- What is the typical batch size I would like to use?
- What is the limitation of my target hardware?
- Will memory become a bottleneck for my model in production?
#4: Model cloud cost
When deploying a deep learning model, the cost of using a cloud-based compute infrastructure is a significant component in the overall budget. The Deci platform computes and depicts the cost of the cloud-based compute infrastructure needed to process one million samples, with different batch sizes for each of the selected hardware.
Compare your model’s performance on different hardware in under 10 minutes
Now that we covered some of the key parameters that can help you select the optimal inference hardware for your model, let’s look at model-optimization in action using Deci’s platform. The following is a step-by-step tutorial that will show you how to easily compare your model’s performance on different hardware.
Step 1: Request free trial of Deci’s Platform (It’s free!)
Book a demo of Deci’s Deep Learning Platform.
Step 2: Choose the model that you would like to benchmark
After signing up and logging in to the Deci platform, you’ll see the Lab page of the Deci console.
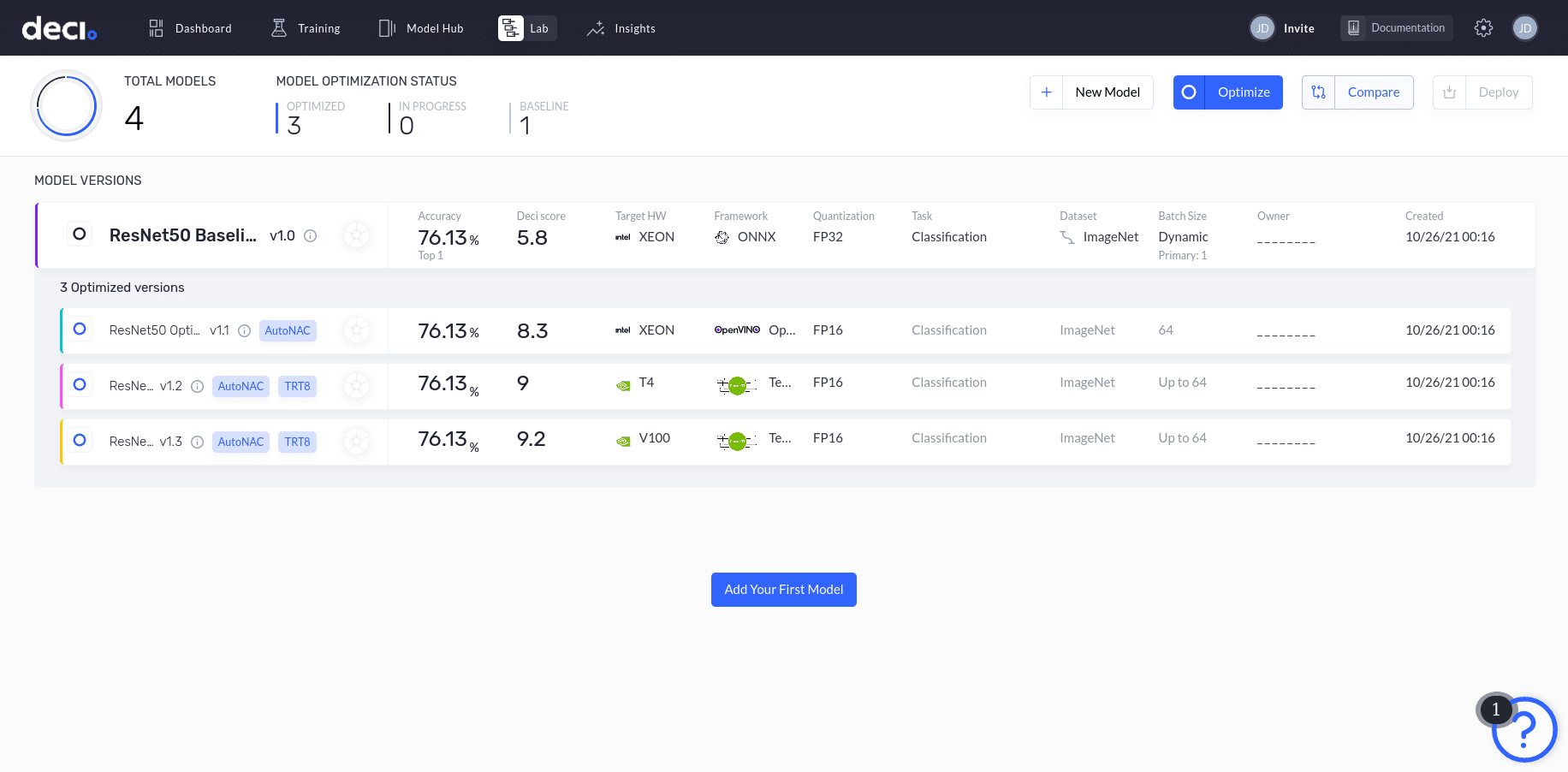
Deci has a Model Hub that includes many popular deep learning models. You can choose one of these models or upload your own. For this tutorial, let’s benchmark the popular object detection deep learning model YOLOv5 across different hardware.
You can clone a model from the Model Hub to the Lab and begin experimenting with it. Let’s clone the YOLO_V5_Large model to the Lab by clicking Clone to Lab.
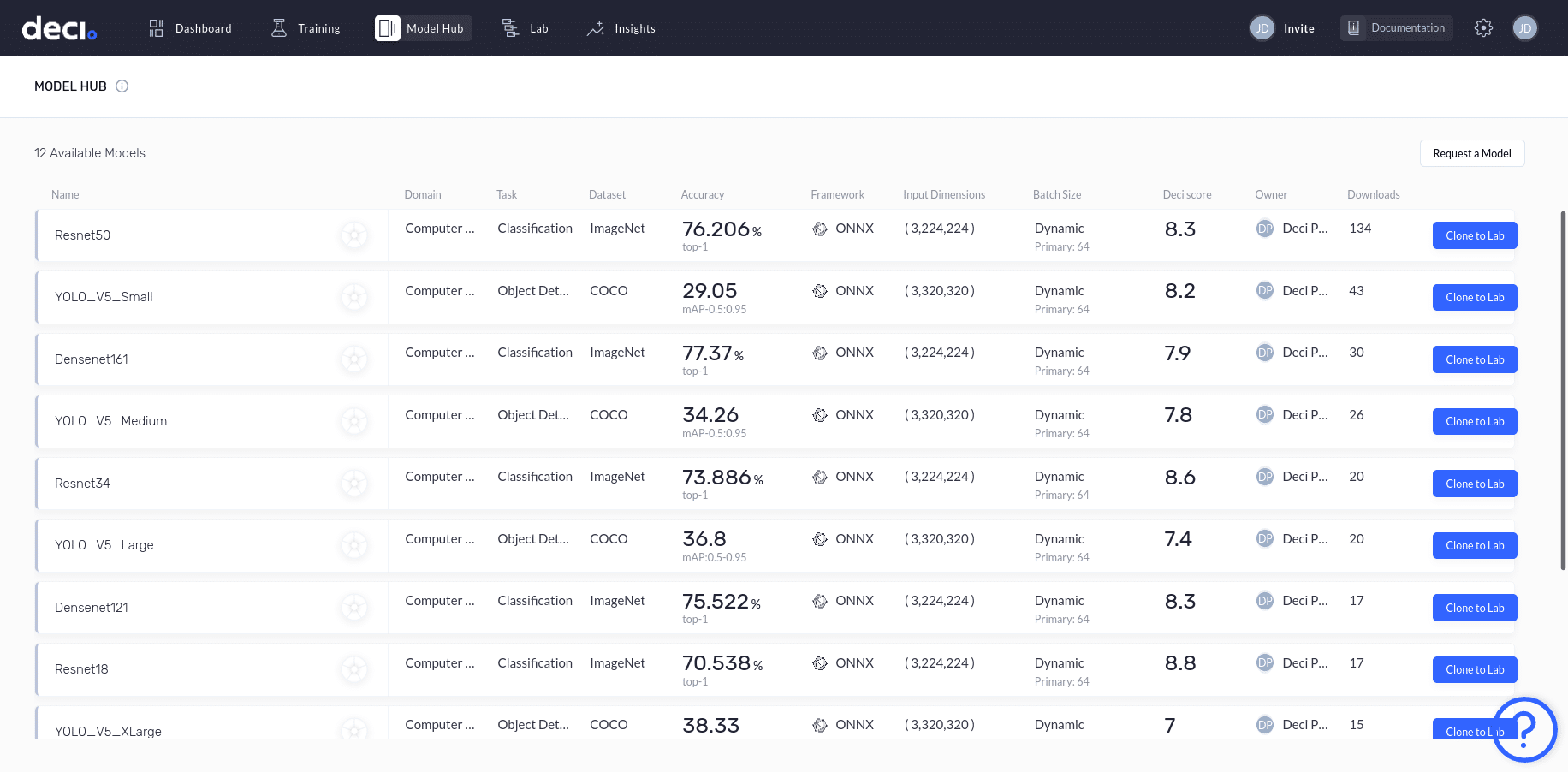
You should now see the YOLO_V5_Large model listed on the Lab page.
Clicking on the model will open the Insights for this model.
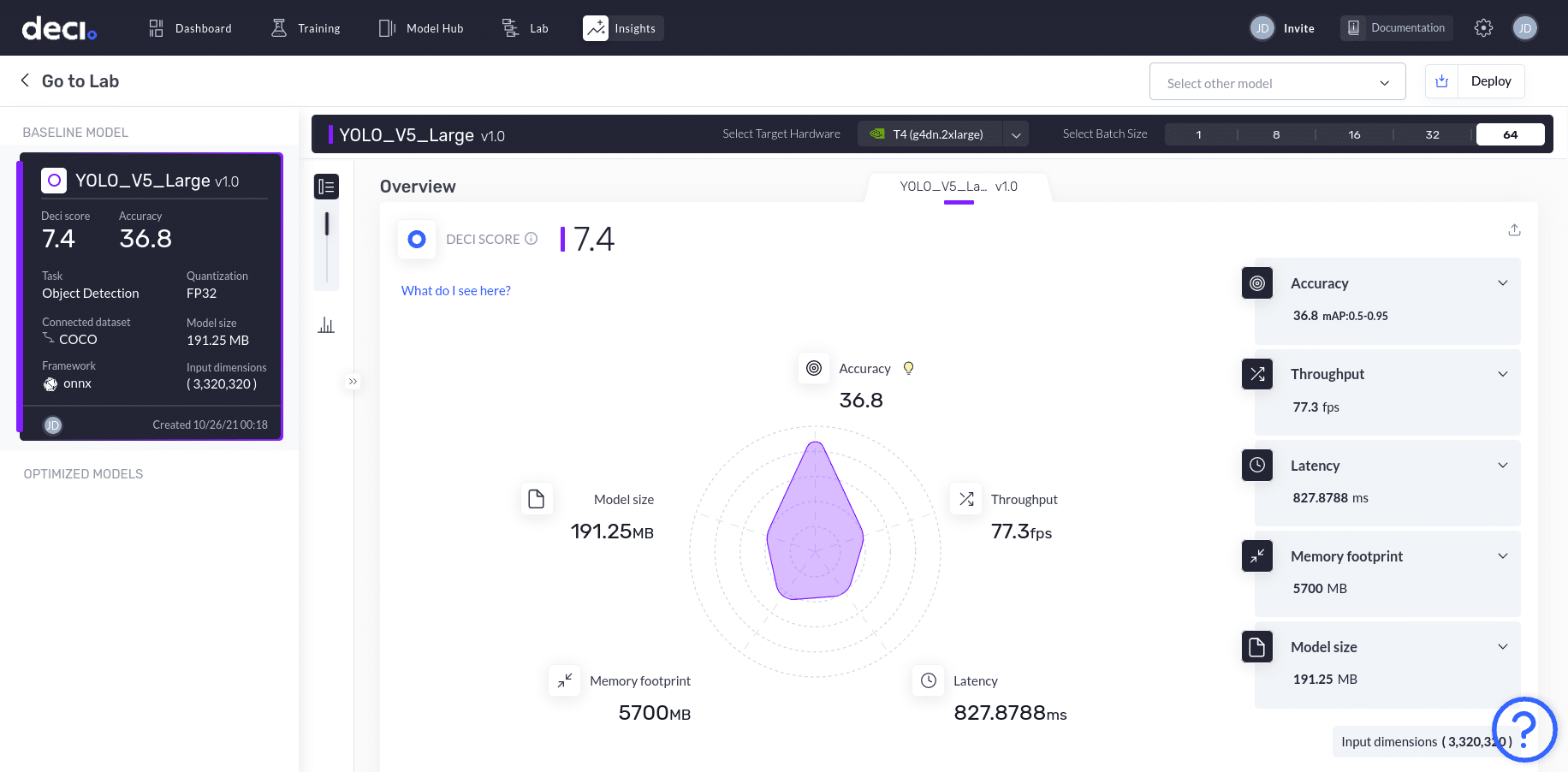
In the Overview section, a radial graph displays the model’s performance across 5 parameters: accuracy, model size, memory footprint, latency, and throughput. The radial graph visualized here for the YOLO_V5_Large, relates to the T4 (g4dn.2xlarge) hardware with a batch size of 64.
Hovering your mouse over the left side panel in the Overview tab will expand it to display the Benchmark HW button.
Step 3: Benchmark hardware
Go ahead and click Benchmark HW.
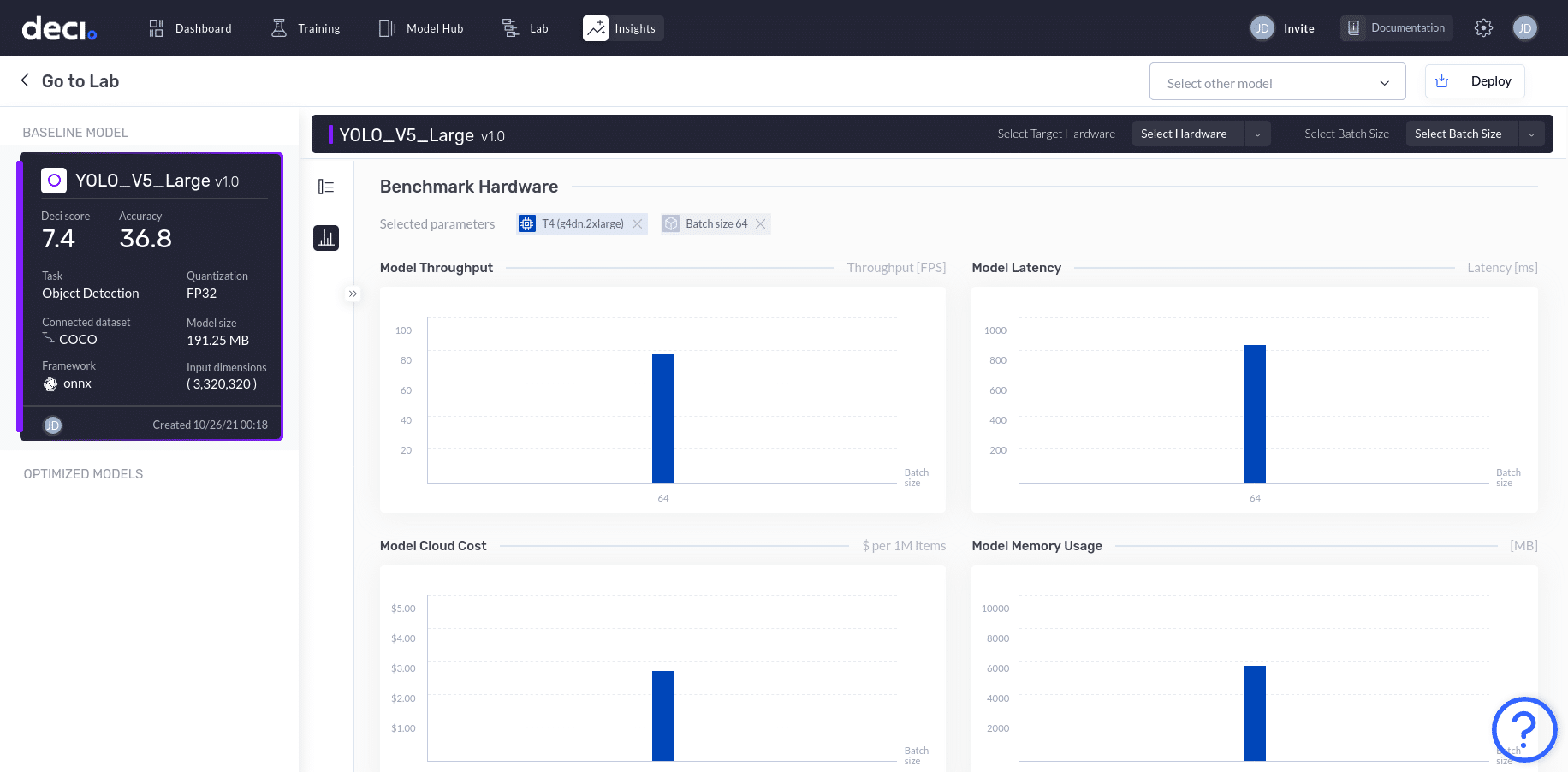
You should see the bar graph for the four parameters: model throughput, model latency, model cloud cost, and model memory usage. The selected hardware is the same T4 (g4dn.2xlarge) with a batch size of 64.
Let’s choose different hardware and benchmark the YOLO_V5_Large model for T4, K80, and V100. To do this, click on the Select Hardware drop down menu, choose the T4, K80, and V100 options, and click Apply. You’ll now see the graphs populated with bars corresponding to each of the selected hardware options.
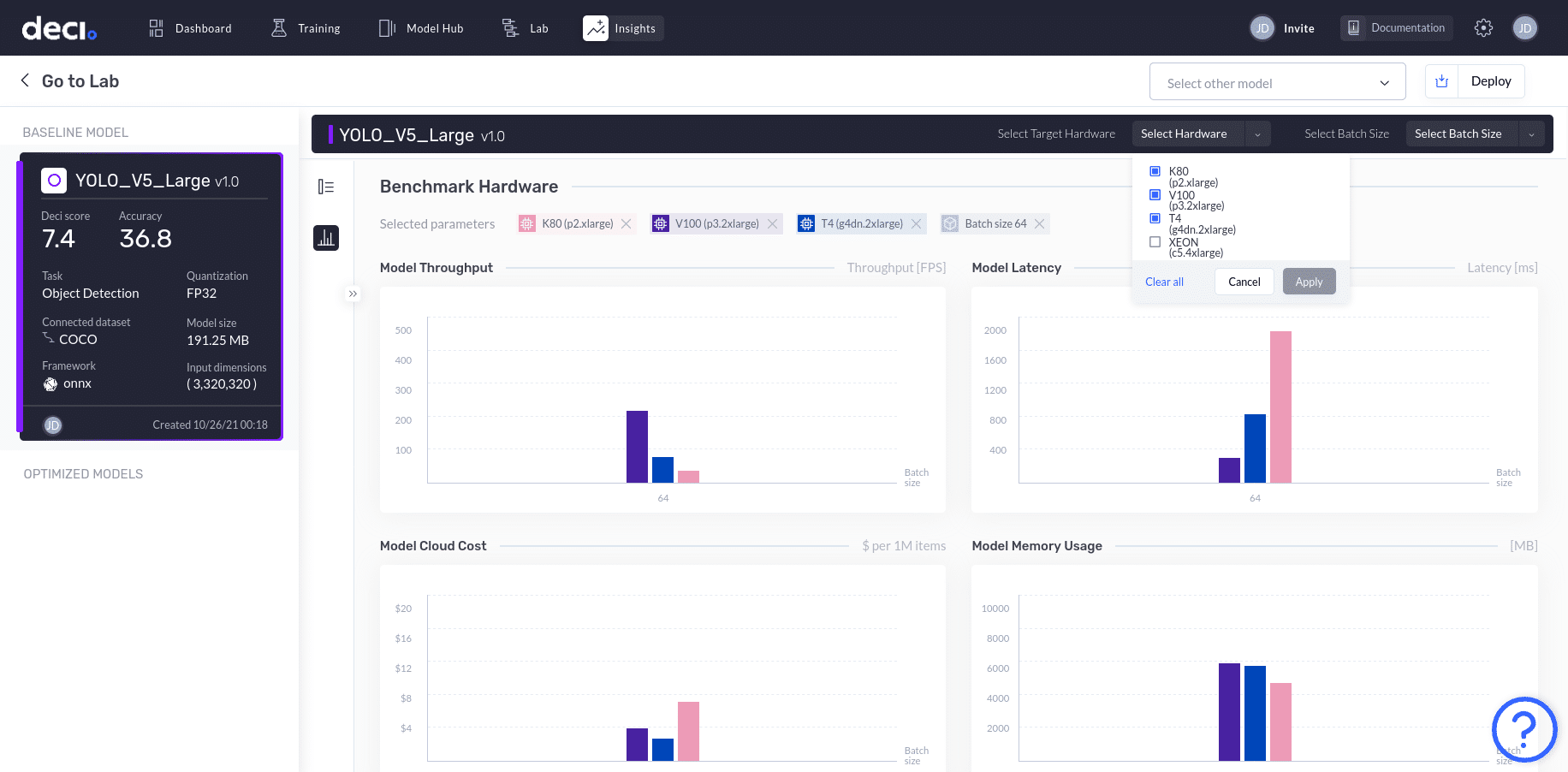
We can now benchmark the selected hardware for batch sizes of 1, 16, and 32. Click the Select Batch Size drop down menu and make sure the options for 1, 16, and 32 are selected. Go ahead and click Apply to see the results.
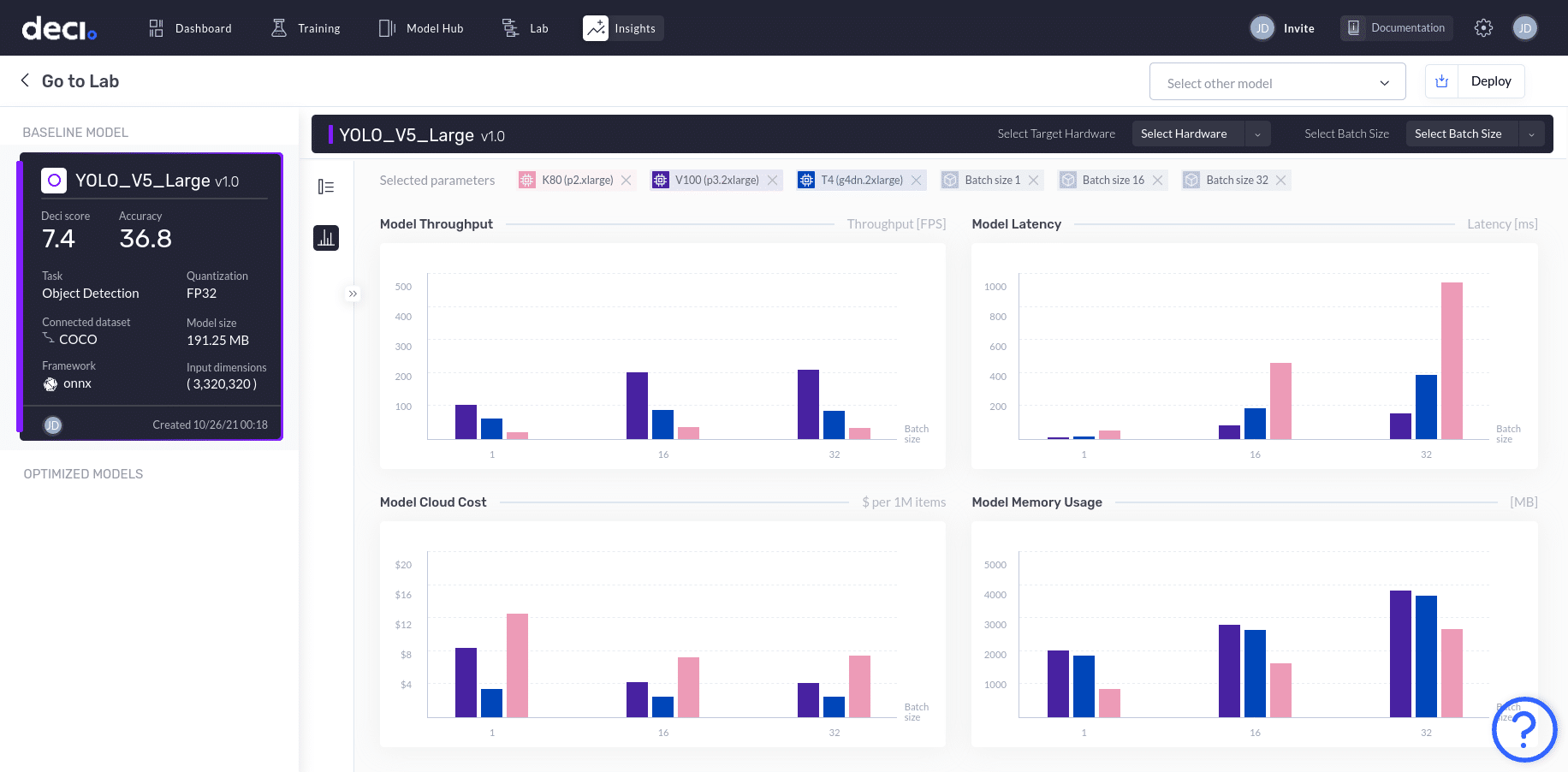
In the graphs displayed, each bar corresponds to a specific hardware and batch size combination. Hovering over a particular bar will highlight the X axis and Y axis values.
Let’s dig deeper and analyze the results offered by the Deci platform.
- Model throughput is the highest at 207.4 FPS on the V100 hardware with a batch size of 32.
- Model latency is a minimum of 9.8564 ms for the V100 hardware with a batch size of 1. The latency graph depicts that the model latency parameter is directly proportional to batch size, which makes perfect sense!
- Model cloud cost is lowest at $2.43 for the T4 hardware with batch size of 16.
- Model memory usage has the lowest value for a batch size of 1 on the K80 hardware.
It’s now much easier to make a decision when it comes to selecting the best hardware for specific goals and applications. For example, when it comes to the model in this tutorial, a deep learning application with a focus on real-time response, and minimal cloud-based compute infrastructure cost, would make the V100 hardware with a batch size of 16 the best choice.
Next time you need to select your inference hardware simply sign up for Deci’s free platform to discover the best inference hardware for your deep learning model without all the hassle and make an informed decision in no time.
Discover the best hardware for your model today.









