Deep Learning methods have made numerous applications practically feasible. Their human-like accuracy has made them a cornerstone for most vision, language, and speech applications. Alongside growing accuracy, the capacity of these models has expanded. Today, we can even find models with billions of parameters and tens of billions of floating-point operations (FLOPs).
Graph compilers have emerged to help cope with this massive computational demand. Graph compilers take a deep neural network, compress it, and streamline its operation so it runs faster and consumes less memory. For many applications, graph compilers are an essential enabler when it comes to inference.
In previous posts of our deep learning inference acceleration series, we started off by introducing the different levels in the acceleration stack and then talked about hardware acceleration. We now dive further into deep learning inference acceleration by exploring graph compilers.
At the base of the stack, we have hardware devices performing the computation itself. At the next level, we find three software components: low-level libraries that can operate the hardware devices, computation graph compilers, and deep learning frameworks. The low-level libraries (e.g., cuDNN and MKL-DNN) are typically optimized for specific hardware devices; they provide highly-tuned implementations for standard neural layers such as convolution, pooling, and activation. On top of these libraries there are graph compilers, such as TVM, Tensor-RT, XLA, and Glow. The purpose of graph compilers is to optimize the processing of a forward, or backward pass over the computation graph. They perform optimization at several levels to help the model run faster, without changing the model itself.

Figure 1: DL Inference Acceleration Stack
Why doesn’t everyone use graph compilers?
Here’s the thing. Not everyone uses graph compilers – some do and some don’t. Graph compilers are a relatively new tool and are still complicated to use correctly in a way that allows data scientists and developers to enjoy its benefits. Why is it so difficult to use graph compilers? The biggest challenge in using graph compilers stems from the fact that the different frameworks (e.g., PyTorch, Tensorflow, and others) and the graph compilers themselves (e.g., TensorRT, OpenVino, TFLite, etc) are being developed independently and at different paces. One framework may implement a new operator such as Matrix NMS, which has not yet been implemented in the graph compiler. This means the model using it will not be traced correctly, or may not even be able to compile. The situation is further complicated by the fact that even some of the basic layers such as convolutions, are implemented differently (NCHW vs. NHWC). Another challenge is that some graph compilers only work with certain frameworks. For example, OpenVino only accepts TF and ONNX; if you want to compile a PyTorch model, it must first be compiled to ONNX and then to OpenVino. Finally, graph compilers work on intermediate representations, known as ‘frozen graphs,’ so basic conditional operators (such as “if”) are only traced once. Some compilers allow for dynamic input shapes, while others do not.
Let’s take deeper dive into how graph compilers work to better understand how, when used correctly, they can offer enormous amounts of acceleration.
Graph Compiler Basics
Most deep learning architecture can be described using a directed acyclic graph (DAG), in which each node represents a neuron. Two nodes share an edge if one node’s output is the input for the other node. This makes it natural to represent them using computational graphs. Similar to the DAG representation, the nodes in a computational graph represent tensor operators and their edges represent the data dependencies between them. When we define a neural network in Tensorflow or PyTorch, the network is converted to a computational graph, which is then executed on the desired hardware. Figure 2 shows a two-layer neural network with tanh activation and its corresponding computational graph.
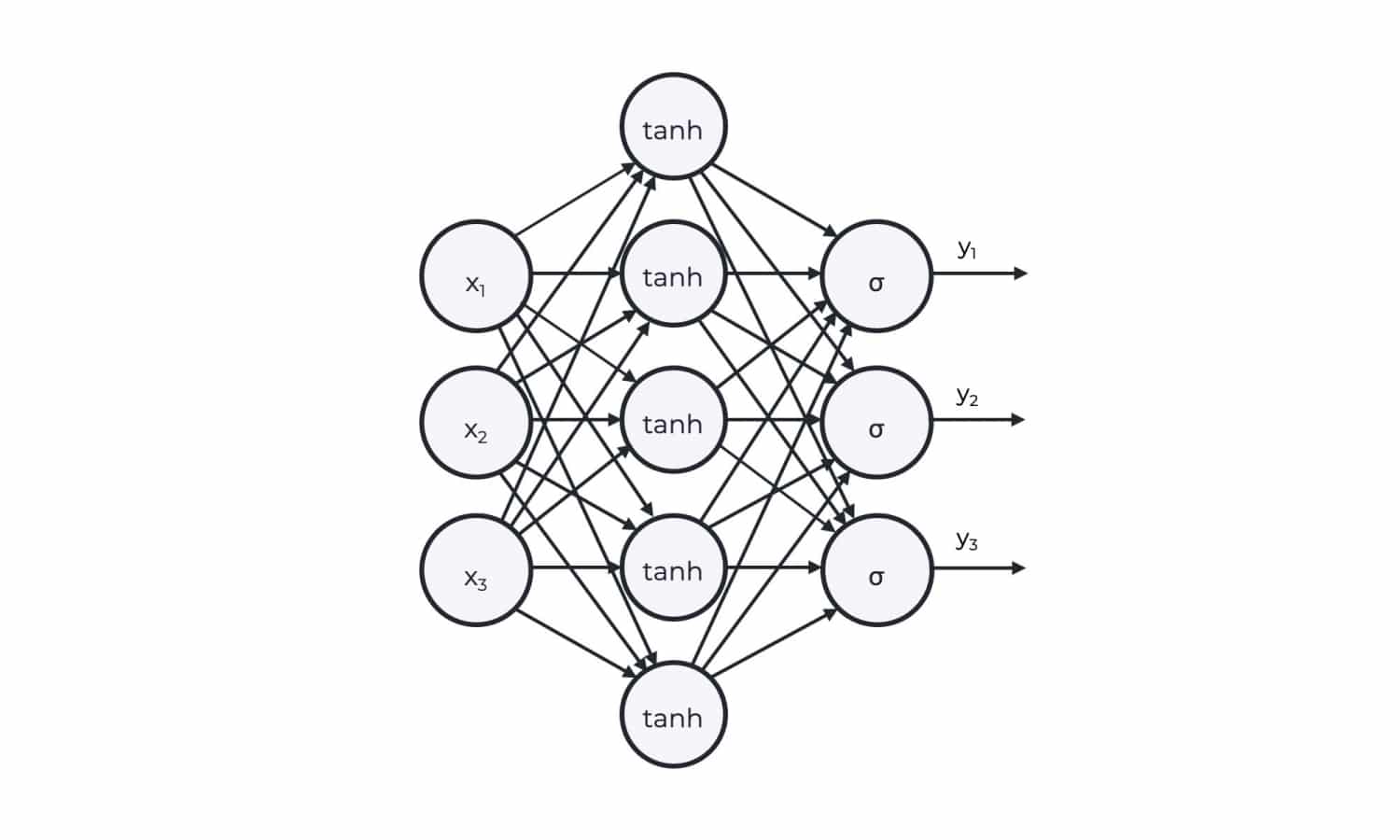
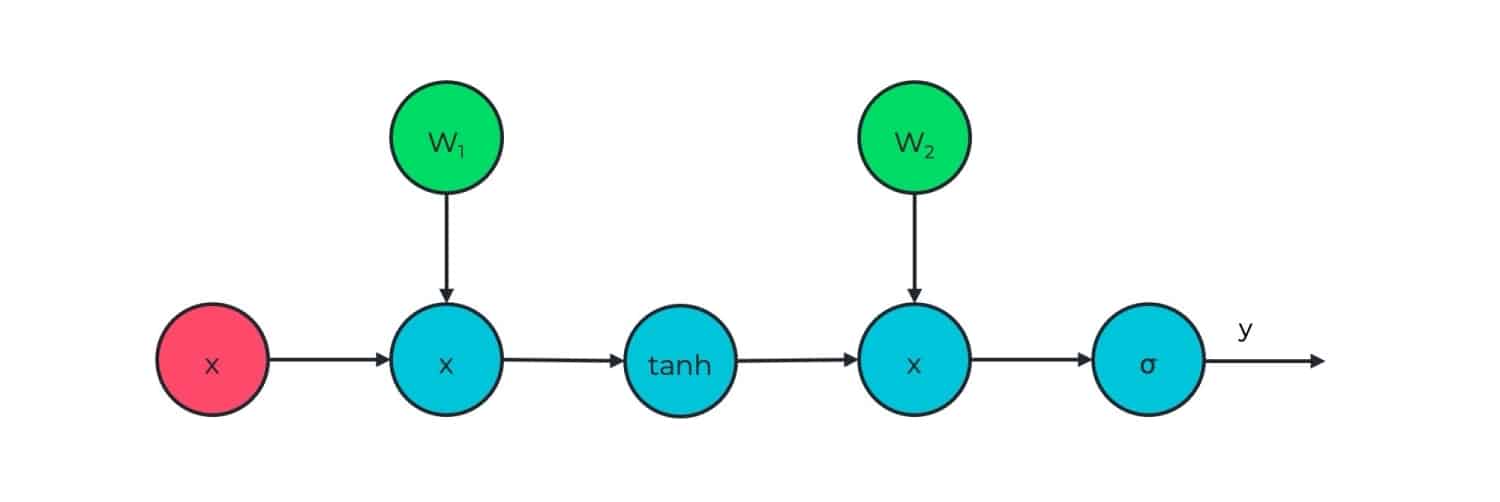
Figure 2: A two-layer neural network and the corresponding computational graph. W corresponds to the weights of the network, x is the intermediate layer input, and sigma is a general non-linearity.
The complexity of the computational graph grows linearly with the network size. This is where graph compilers come into play. Their goal is to optimize the generated computational graphs for inference on a particular target hardware.
Graph compilers map the high-level computational graph coming from DL frameworks to operations that are executable on a specific device. When compiling a computational graph or mapping it to a hardware target, graph compilers apply a number of optimizations to speed up inference on the target device. Typical graph compiler optimizations include graph rewriting, operation fusion, assignment of operations to hardware primitives, kernel synthesis, and more.
Graph Rewriting
The structure of the graph determines the order in which operations will be executed to compute the output. Job scheduling aims to determine the optimal order in which a sequence of operations needs to be executed. The graph rewriting aims to utilize the degrees of freedom in the graph to achieve better job scheduling when executing a forward pass in the network. It is usually possible to apply some elementary actions on graphs to achieve the same result with better operation scheduling. These actions can include: deleting/adding a node or edge, merging nodes, cloning or replacing a subgraph with another one. Another very simple optimization that graph compilers do is to remove layers with unused output.
Operation Fusion
The computational graphs often contain sequences of operations that are rather common, or for which specific hardware kernels exist. This fact is exploited by many graph compilers to fuse operations where possible and eliminate unnecessary trips to memory. Operation fusion can be seen in many cases such as when convolution, ReLU and batchnorm are usually fused into one operation, or when the bias is fused into the convolution operation.
Figure 3 illustrates the operation fusion. In the figure, we have two sequential operations, K1 and K2, where K2 operates on the output of K1. Fusing them into a single operation could eliminate the need to read and write transactions using global memory. Instead, the intermediate result from K1, locally stored in memory, is available for K2 to use.
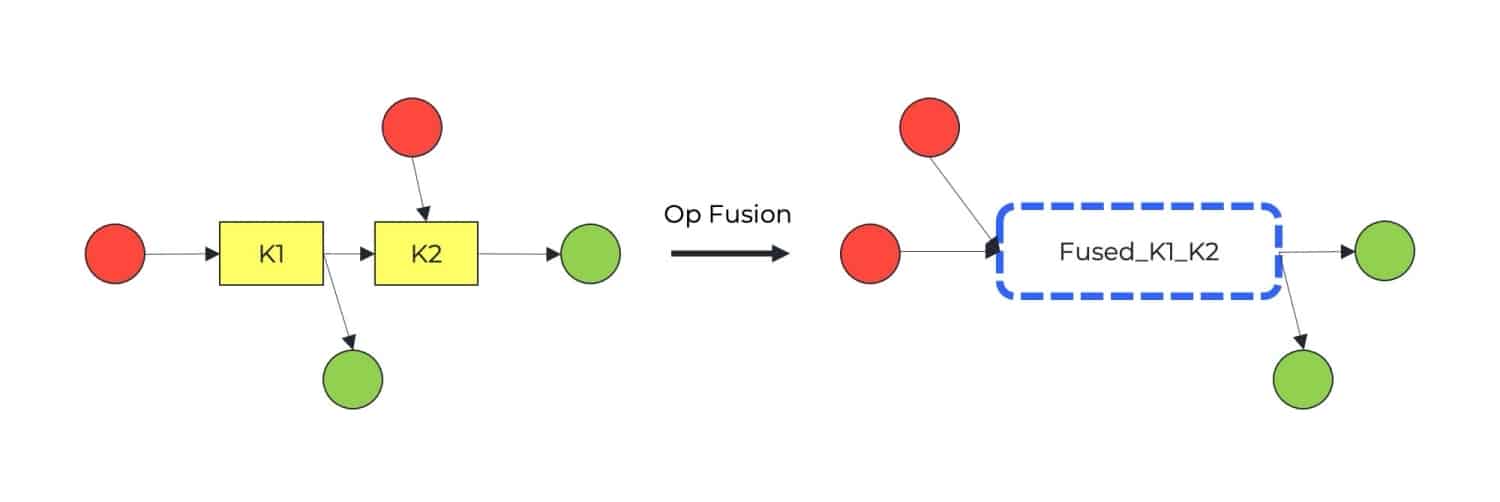
Figure 3: Operation fusion. Two sequential operations, K1 and K2, are fused into one operation.
Assignment of Operations / Operation Scheduling
Part of the job of optimization includes determining the best assignment of operations for the target hardware, especially when inference takes place on multiple devices. Graph compilers introduce an additional hardware abstraction layer, which often makes it possible to accelerate inference on very different hardware devices. To accomplish this, they introduce yet another optimization where operations are assigned to hardware based on the best policy for achieving fast inference. Operations are scheduled with different policies. In a multi-device setting, as part of the scheduling strategy, each device maintains a queue of operations ready to be executed. The scheduling can be optimized since the order affects the overall runtime. Graph compilers optimize this by determining the proper scheduling strategy required to assign priorities for different nodes in the graph, by taking into account cross-device dependencies.
Popular Graph Compilers
There exist many graph compilers, with each using a different technique to accelerate inference and/or training. The most popular graph compilers include: nGraph, TensorRT, XLA, ONNC, GLOW, TensorComprehensions(TC), and PlaidML.
Tensor RT
TensorRT is a graph compiler developed by NVIDIA and tailored for high-performance deep learning inference. This graph compiler is focusing solely on inference and does not support training optimizations. TensorRT is supported by the major DL frameworks such as PyTorch, Tensorflow, MXNet, and others. It was built to work on top of NVIDIA’s CUDA and enable high throughput. Some of the optimizations done by TensorRT involve layer tensor operations fusion, kernel auto-tuning (or optimized assignment of operations), dynamic tensor memory, and more.
Intel nGraph
Developed by Intel, nGraph is almost the only graph compiler that supports both training and inference acceleration for all three most popular DL frameworks: Tensorflow, PyTorch, and MXNet. This open-source graph compiler is able to look for patterns (subgraphs, sequences of specific operations, etc.) in the computational graph and exploit them to optimize the computational graph and compile optimized assembly code that can run on different hardware back-ends.
ONNC
ONNC is a graph compiler and a retargetable compilation framework developed as part of the Open Neural Network Exchange (ONNX). The ONNC graph compiler provides reusable compiler optimizations and supports compiling ONNX models. ONNC does only inference optimizations and it works by defining an intermediate representation (IR) of the computational graph, which is later used for both target-dependent and target-independent optimizations. ONNC compiled models can run on a variety of hardware such as CPU, GPU, FPGA, DSP, etc.
Apache TVM
TVM is another open-source graph compiler used to accelerate machine learning. It includes optimizations such as constant folding and dead-code elimination, layout transformation, and scaling factor folding. TVM works similarly to Intel’s nGraph and builds an intermediate representation (IR) first before applying graph transformations and optimizations. Like the other graph compilers we mentioned, TVM supports all major DL frameworks and can compile for different hardware targets, including CPU, GPU, FPGA, and microcontrollers.
How do you choose the correct graph compiler?
So far, we have seen what graph compilers can do and mentioned some of the more popular ones. The question is: How do you decide which graph compiler to use for your particular model? If your model was built using a specific framework, the first thing to check is which compilers are supported. The second thing, obviously, is the target hardware. Not all graph compilers support all different hardware devices, so the choice can be further narrowed down by the desired deployment platform. Finally, if your model is supported, and so is the target hardware, you want to choose the graph compiler that will give you the best optimizations and improvements in terms of inference speed. This, of course, depends on the architecture and needs to be determined by trial and error.
At Deci, based on extensive knowledge of what goes on behind the scenes in deep neural networks, we automatically incorporate these considerations. Our platform compiles any model with state-of-the-art graph compilers within the platform to make the most of all their strengths. You can read more about the Deci platform here or request a demo.
Summary
In this third post in the series of deep learning inference acceleration, we discussed graph compilers. These are specifically designed to optimize deep neural networks by providing an abstraction layer between the computational graph and the target hardware.
The optimizations achieved by these compilers can speed up inference by a significant factor. Graph compilers are an important part of deep learning inference acceleration and we anticipate that their adoption by the industry will grow, enabling many practical deep learning applications to benefit from their advantages.
You can find the rest of the series below: