Deep neural networks have become common practice in many machine learning applications. Their ability to achieve human-like, and even super-human, accuracy have made them a milestone in the history of AI. However, achieving such levels of accuracy is prohibitively costly in terms of compute power. Modern architectures perform billions of floating point operations (FLOPs), which pose a significant challenge to use them in practice. For this reason, many optimization techniques have been developed at the hardware level to process these models with high performance and power/energy efficiency — without affecting their accuracy. It is no wonder that the market for deep learning accelerators is on fire. Intel recently acquired Habana labs for $2 billion and AMD is set to acquire Xilinx for $35 billion.
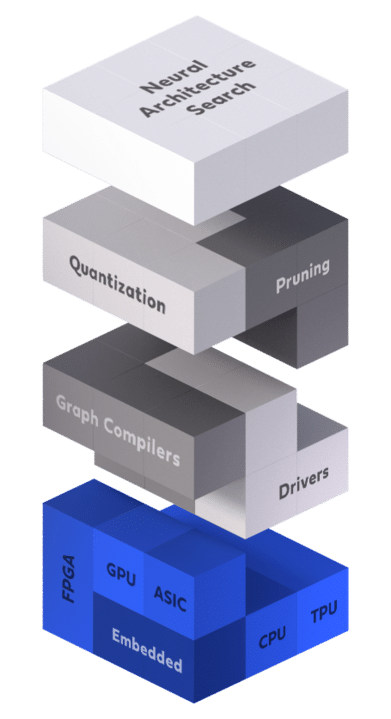
In this post, we continue our deep learning inference acceleration series and dive into hardware acceleration, the first level in the inference acceleration stack (see Figure 1). We review several hardware platforms that are being used today for deep learning inference, describe each of them, and highlight their pros and cons.
Central Processing Unit (CPU)
CPUs are the ‘brains’ of computers that process instructions to perform a sequence of requested operations. We commonly divide the CPU into four building blocks: (1) Control Unit (CU) – The component that directs the operation of the processor. It tells the other components how to respond to the instructions that were sent to the processor. (2) Arithmetic logic unit (ALU) – The component that performs the integer arithmetic and bitwise logical operations. (3) Address generation unit (AGU) – The component inside the CPU that calculates addresses used to access the main memory. (4) Memory management unit (MMU) – This refers to any memory component that is used by the CPU to allocate memory.
Present day CPUs are heavy duty pieces of hardware, which contain billions of transistors, and are extremely costly to design and manufacture. They contain powerful cores that are able to handle vast amounts of operations and memory consumption. These CPUs support any kind of operations without the need to write custom programs. However, their extensive universality also means they contain superfluous operations and logic verifications. Moreover, they don’t fully exploit the parallelism opportunities available in deep learning.
- Pros – Cost effective, fit for general purpose, powerful cores, high memory capacity
- Cons – Don’t fully exploit parallelism, low throughput performance
Graphical Processing Units (GPU)
A GPU is a specialized hardware component designed to perform many simple operations simultaneously. Originally, GPUs were intended to accelerate graphics rendering for real-time computer graphics, especially gaming applications. The general structure of the GPU has some similarities to the structure of the CPU; they both belong to the family of spatial architectures. But, in contrast to CPUs, which are composed of a few ALUs optimized for sequential serial processing, the GPU comprises thousands of ALUs that enable the parallel execution of a massive amount of simple operations. This amazing property makes GPUs an ideal candidate for deep learning execution. For example, in the case of computer vision applications, the structure of the convolution operation, where a single filter is applied on every patch in the input image, enables effective exploitation of the parallelism of the GPU device.
Although GPUs are currently the gold standard for deep learning training, the picture is not that clear when it comes to inference. The energy consumption of GPUs makes them impossible to be used on various edge devices. For example, NVIDIA GeForce GTX 590 has a maximum power consumption of 365W. This amount of energy cannot possibly be supplied by smartphones, drones, and many other edge devices. Moreover, there is an IO latency for transferring from host to device, so if parallelization can’t be fully exploited the use of GPU becomes redundant.
- Pros – High throughput performance, a good fit for modern architectures (ConvNets)
- Cons – Expensive, energy-hungry, has IO latency, memory limitations
Field Programmable Gate Array (FPGA)
FPGA is another type of specialized hardware that is designed to be configured by the user after manufacturing. It contains an array of programmable logic blocks and a hierarchy of configurable interconnections that allow the blocks to be inter-wired in different configurations. In practice, the user writes code in a hardware description language (HDL), such as Verilog or VHDL. This program determines what connections are made and how they are implemented using digital components. In recent years, FPGAs have started supporting more and more multiply and accumulate operations, enabling them to implement highly parallel circuits. But on the other hand, using them in practice might be challenging. For example, data scientists train their models using Python libraries (TensorFlow, Pytorch, etc) on GPUs and use FPGAs only for inference. The thing is, the HDL is not inherently a programming language; it is a code written to define hardware components such as registers and counters. This means the conversion from the Python library to FPGA code is very difficult and must be done by experts.
- Pros – Chip, energy efficient, flexible
- Cons – Extremely difficult to use, not always better than CPU/GPU
Custom AI Chips (SoC and ASIC)
So far, we described hardware types that have been transformed to suit deep learning purposes. Custom AI chips have set in motion a fast growing industry that is building customized hardware for AI. Currently, more than 100 companies around the globe are developing Application Specific Integrated Circuits (ASICs) or Systems on Chip (SoCs) for deep learning applications. What’s more, the giant tech companies are also developing their own solutions such as Google’s TPU, Amazon’s Inferentia, NVIDIA’s NVDLA, Intel’s Habana Labs, etc. The sole purpose of these custom AI chips is to perform the deep learning operations faster than existing solutions (i.e., GPUs). Because different chips are designed for different purposes, there are chips for training and chips for inference. For example, Habana Labs are developing the Gaudi chip for training and the Goya chip for inference.
Making an AI chip (ASIC or SoC) is not a trivial task. It is a costly, difficult, and lengthy process that typically requires dozens of engineers. On the other hand, the advantages gained from custom AI chips can be enormous and there is no doubt that in the future we will see extensive usage of these chips.
- Pros – Potential to significantly boost inference performance
- Cons – Expensive and hard to develop
Which hardware should I use for my DL inference?
There are many online guides describing how to choose DL hardware for training, but fewer exist on what hardware to choose for inference. Inference and training might be very different tasks in terms of hardware. When confronting the dilemma of which hardware to choose for inference, you should ask yourself the following questions: How important is my inference performance (latency/throughput)? Do I want to maximize latency or throughput? Is my average batch size small or large? How much cost am I willing to trade for performance? Which network am I using?
Let’s look at an example to demonstrate how we select inference hardware. Say our goal is to perform object detection using YOLO v3, and we need to choose between four AWS instances: CPU-c5.4xlarge, Nvidia Tesla-K80-p2.xlarge, Nvidia Tesla-T4-g4dn.2xlarge, and Nvidia Tesla-V100- p3.2xlarge. We begin by evaluating the throughput performance. Figure 2 shows the throughput achieved by each of the hardware options. We see that the V100 absolutely dominates the throughput performance, especially when using a large batch size (8 images in this case). Moreover, since the potential for parallelization in the YOLO model is huge, the CPU underperforms the GPU in this metric.

If our only priority is to optimize the throughput, we are done here and should choose the V100 for our inference engine. However, in most cases, the cost is also a concern. To measure the cost-effectiveness of hardware, we take the throughput performance and divide it by the price of the AWS instance, as shown in Figure 3. Although the V100 achieves the best throughput performance, it is not the most cost-effective hardware. In our example, T4 appears to be the most cost-effective hardware, especially if we use a small batch size.
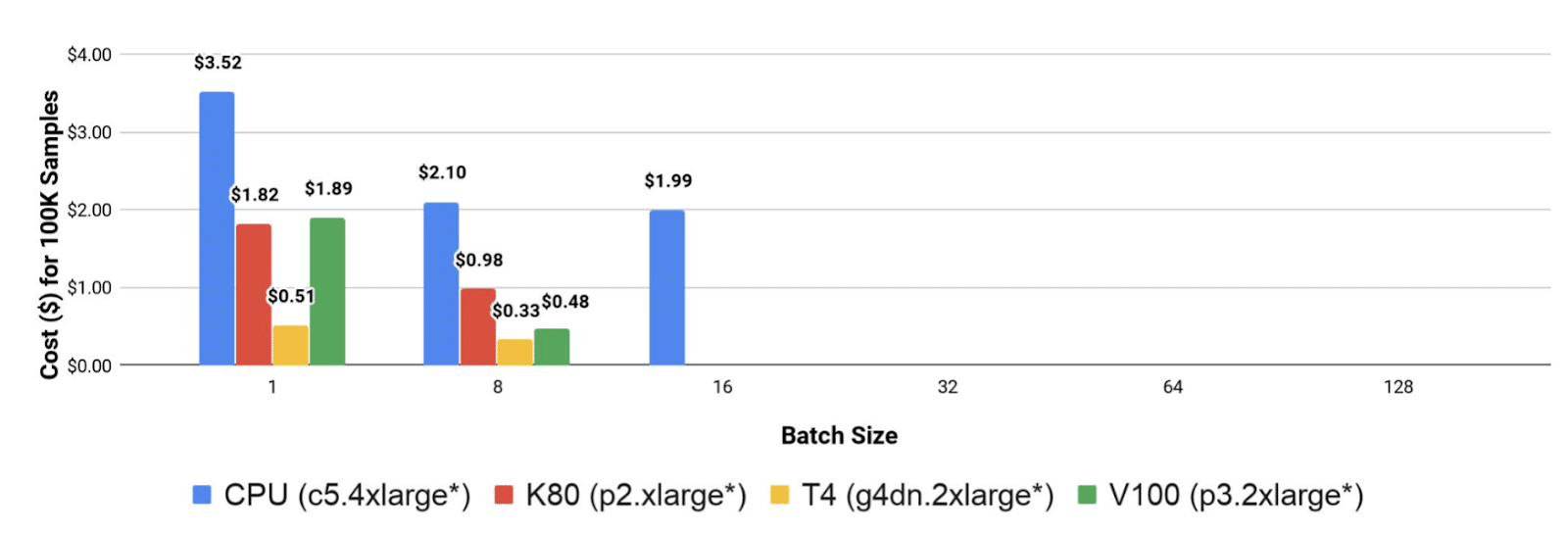
Clearly, we will get different results for different models. For example, for classification models that were designed for CPU (such as MobileNet, EfficientNet, etc.), CPU is the most cost effective hardware. At Deci, we can produce these benchmarks for you with the press of a button, for every model, even yours. You can find more details here.
Conclusion
In this second post of the deep learning acceleration series, we surveyed the different hardware solutions used to accelerate deep learning inference. We started by discussing the pros and cons of various hardware machines and then explained how to choose hardware for your inference scenario. There is no doubt that in the coming years we will see an upsurge in the deep learning hardware field, especially when it comes to custom AI chips.
As we saw in the previous post, the potential for improvement from algorithmic acceleration is independent from the potential for hardware acceleration. That’s why, at Deci, we decided to go algorithmic. Our solution can be used on any hardware and is hardware-aware, meaning it takes into account the different aspects of the target hardware. We invite you to read more about it in our white paper. Stay tuned for the next post.
You can find the rest of the series below:
- An Introduction to the Inference Stack and Inference Acceleration Techniques
- Hardware for Deep Learning Inference: How to Choose the Best One for Your Scenario – This!
- Graph Compilers for Deep Learning: Definition, Pros & Cons, and Popular Examples