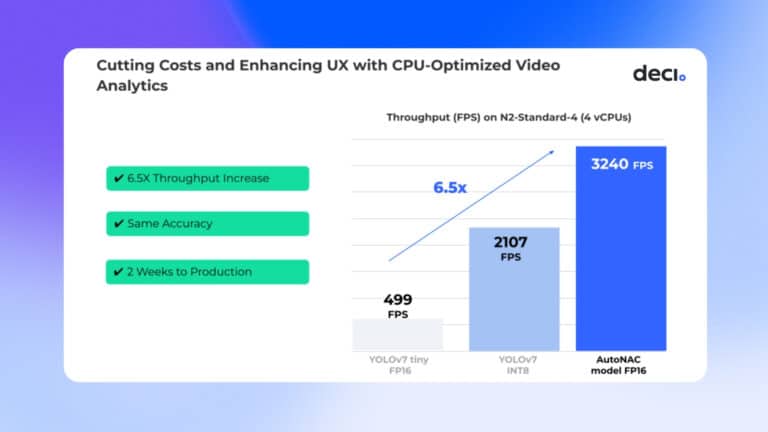
Building machine learning is expensive, and the rising inflation and looming recession are pushing many companies with ML applications to reevaluate processes and find ways to better control costs.
Which phases of your end-to-end AI process cost the most and what can you optimize? How can you save money and make the most of the budget that you already have?
There are two phases in a typical machine learning development lifecycle that generate a huge amount of cost: training and inference. In this blog, we’re focusing on inference, and how you can optimize it to reduce cloud cost.
The Cost of Machine Learning Inference
When companies get to a mature product and start to run inference workloads, there would be an inflection point where inference workloads grow and grow, and the cost starts to accumulate around them. By the time products start to scale, there would be multiple models running in the cloud, prompting companies to find ways to reduce cloud costs.
For example, a relatively early-stage startup can have a product that’s running with 24/7 clusters of about 10 to 20 GPU instances. The cost of this workload is very significant for the size of that startup, so they would have to think about optimization for cost reduction.
What are the Top 3 Cost Drivers and Optimization Opportunities When It Comes to Inference?
There are multiple layers that you can touch when it comes to the cost optimization of inference performance. Each of them is independent of the other and they all together contribute to the overall performance or the overall cost of the inference workload.
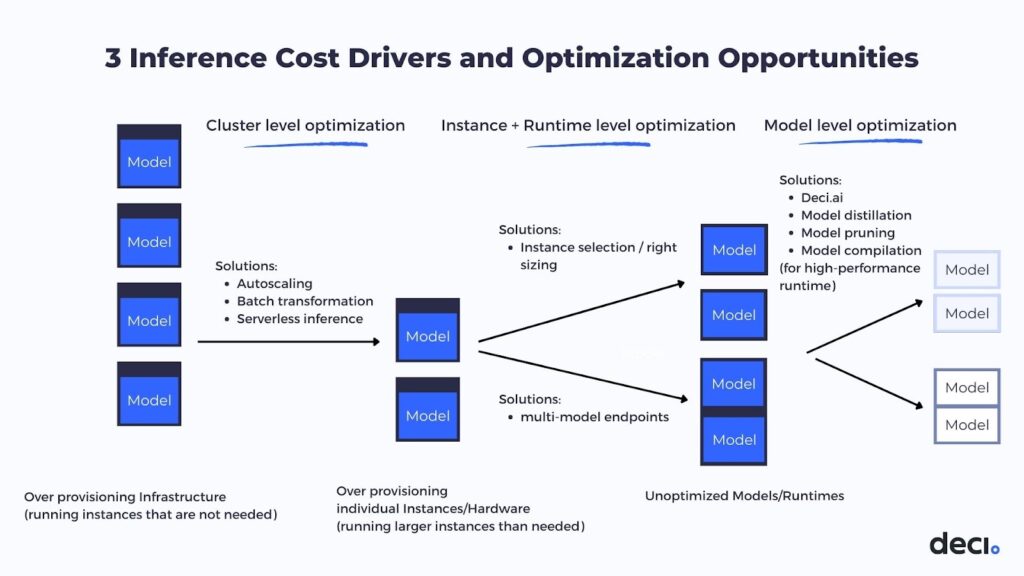
1. Cluster-level Optimization
Let’s begin with cluster-level optimization. This is where you set the settings of how you do auto-scaling, how you work with the largest batches possible either by doing automatic batching or setting the batching in advance, and what to consider when running serverless inference instead of running standard virtual machines (VMs). All these settings on the cluster level can reduce the number of machines or the amount of compute resources that you are running at a time.
2. Instance and Runtime Level Optimization
The next layer is the instance and runtime level optimization. Here you consider the following questions:
- What is the type of instance that you are selecting?
- What is the type of underlying hardware that you can use—GPUs, CPUs, or other machine learning inference hardware that’s available in the cloud like the AWS hardware?
- What is the runtime optimization that you are using?
- How do you leverage methods like graph compilation and quantization to get better performance for the model running on a given hardware?
Let’s take a look at quantization. It reduces the model size that’s running and enables you to use multiple models on the same GPU. Multi-model runtime inference workloads, for example, use one GPU for running two, three, or four models in parallel and share the compute resources of the GPU over those models. This enables you to run all of them on the same node, reducing the amount of hardware that you need to provision to enable that workload to run.
3. Model-Level Optimization
The last layer is the model-level optimization where you want to improve the runtime performance or the memory footprint of the model to be able to get more queries per second or get more throughput from the available hardware that you have.
For that, you can use distillation to use a smaller model with the same accuracy. You can do model pruning, especially channel pruning. Using Deci as a solution to model optimization can also help you improve the runtime performance and optimize the model size by automatically designing better neural architectures. All of these methods can enable you to leverage the same hardware, run more inference per second, boost the throughput of the machine, and improve the cost associated with inference.
Combining the three layers, starting from the cluster running to the instance and the runtime and ending up with the model level optimization, you now have an end-to-end optimization that can significantly improve the cost and the performance of your inference workload.
What are the Expected Cost Savings When You Focus on Inference Efficiency?
As mentioned earlier, the three layers are independent of each other in some instances. So, every saving that you can have in one layer is multiplied by the savings that you can generate in another layer.
If you start from the cluster level optimization, it’s mostly a tradeoff between the availability of compute power to run, inference in low latency, and the over-provisioning or idle time of the computer reprovision and the spending cost on that. By establishing the settings for the auto-scaling, for example, and running in batches, you can get an improvement of about 2X in the cost of this cluster without losing anything in terms of latency or availability of compute for running inference.
On the instance runtime, you can get 2X to 4X based on the techniques and methods you leverage from graph compilation to model quantization. You can also save on the cost by selecting the right hardware that would be best utilized by the model type that you are using.
Lastly, on the model level optimization, you can expect something between 2X to 4X by improving the model, and selecting or designing better neural architectures. Therefore, if you multiply all these together, you can get more than 10X inference performance improvement which sums up to a more than 90% reduction in cost. Obviously, you can’t do everything on day one, so you need to decide where to start, and go from there.
Final Thoughts and Tips on Addressing High Machine Learning Costs
There are many moving parts involved in running machine learning inference, providing you with more than one way to optimize it and save on cost.
Here’s an additional tip: have an idea of the average utilization of the hardware that you are using. If the utilization is relatively low, then you can think of how you can provision more efficiently and improve the utilization of the hardware that you are already paying for. On the other hand, if the utilization is high, you need to think about other techniques to improve what you can get from that hardware, like generating better throughput or better utilization in terms of queries per second of inference workload.
You can also make cost optimization a team effort and encourage everyone in the organization to contribute to it. From building efficient models to getting the most out of your hardware or using one that works best for your use case, here are other resources that you can check out: