“The boost in inference speed of your Deep Learning model compared to your current runs can be as much as 8 times. By the end of this article you’ll know how to apply it to your use case with minimal effort.”
The NVIDIA Jetson family is a great choice when it comes to finding the optimal hardware in terms of computing power, price and physical weight. The platform is presented as a family of boards, such as Nano, TX2, Xavier NX and AGX Xavier, all of which enable users to meet their requirements for various edge use cases. You can buy an NVIDIA Jetson Nano for as little as $60, and its weight is a mere 250 g (~9 ounces).

Jetson Nano with a size reference
As for the supported software stack, a Nvidia GPU on board allows for ease of deployment as it opens access to CUDA backend which is familiar to many machine learning practitioners. And unlike with Coral TPU or Raspberry Pi, it supports Deep Learning frameworks without any limitations and includes the TensorRT graph compiler, built to speed up your inference.
Nevertheless, if you already had an opportunity to test your application on an NVIDIA Jetson device, the chances are you didn’t get the best performance out of it. In “The Correct Way to Measure Inference Time of Deep Neural Networks” we covered the general rules of benchmarking. However, in the case of Jetson it’s crucial to also understand its performance modes and components to uncover its full potential. When used correctly, they can boost your Deep Learning model’s inference speed by as much as 8 times compared to your current runs. By the end of this article you’ll know how to apply it to your use case with minimal effort.
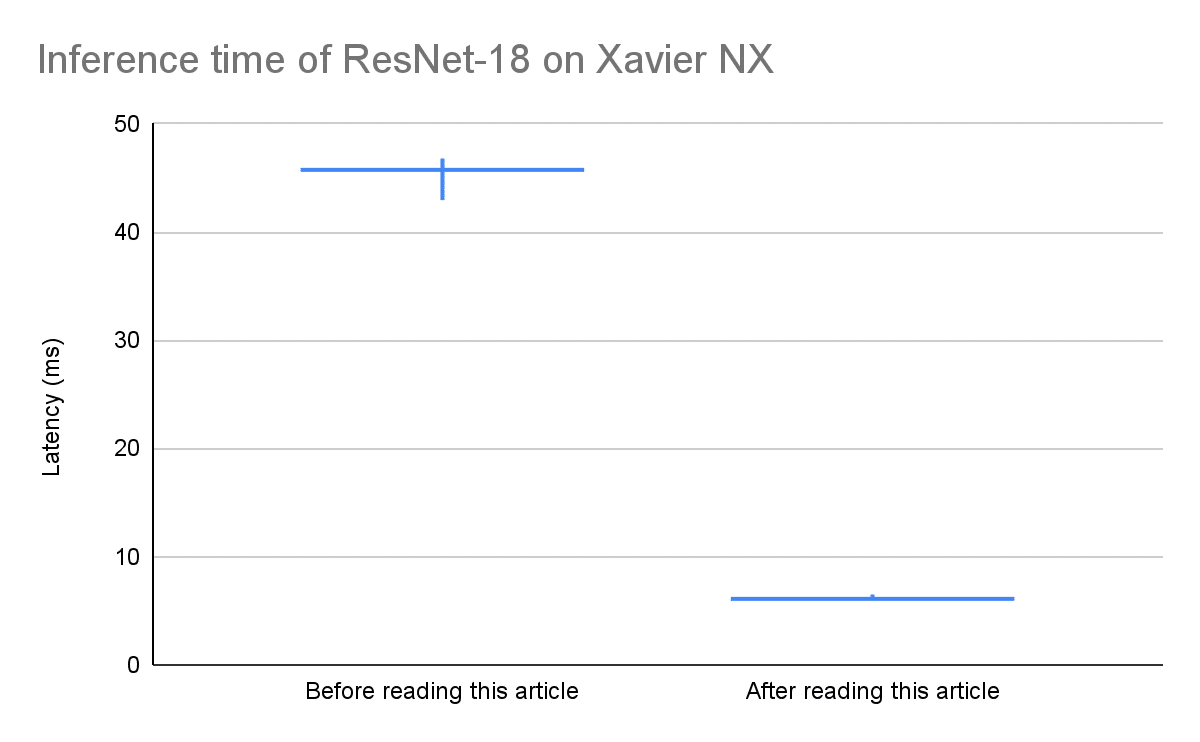
Figure 1:
Resolution: 224, Batch size: 1
Series of predictions done with a 10-second interval in two different states of Jetson Xavier NX
A candlestick chart depicting a min and max latencies with a vertical range
and an average latency with a horizontal line
Major Components of NVIDIA Jetson Boards
All NVIDIA Jetson boards feature processors that belong to the Tegra series which integrates the following components into one chip:
- An ARM architecture CPU;
- A GPU;
- A memory controller (EMC);
- Northbridge and southbridge (known as a chipset in modern motherboards);
- A DLA (Deep Learning Accelerator) on Xaviers.
These and other components of the board support a range of frequencies and states. Their dynamic scaling is essential for power management, thermal management and electrical management, and will substantially impact your user experience. There are many system governors working to take care of everything in an optimal and steady way. But similar to why sports cars use a manual gear, you too should take charge if you don’t want your app to run suboptimally.
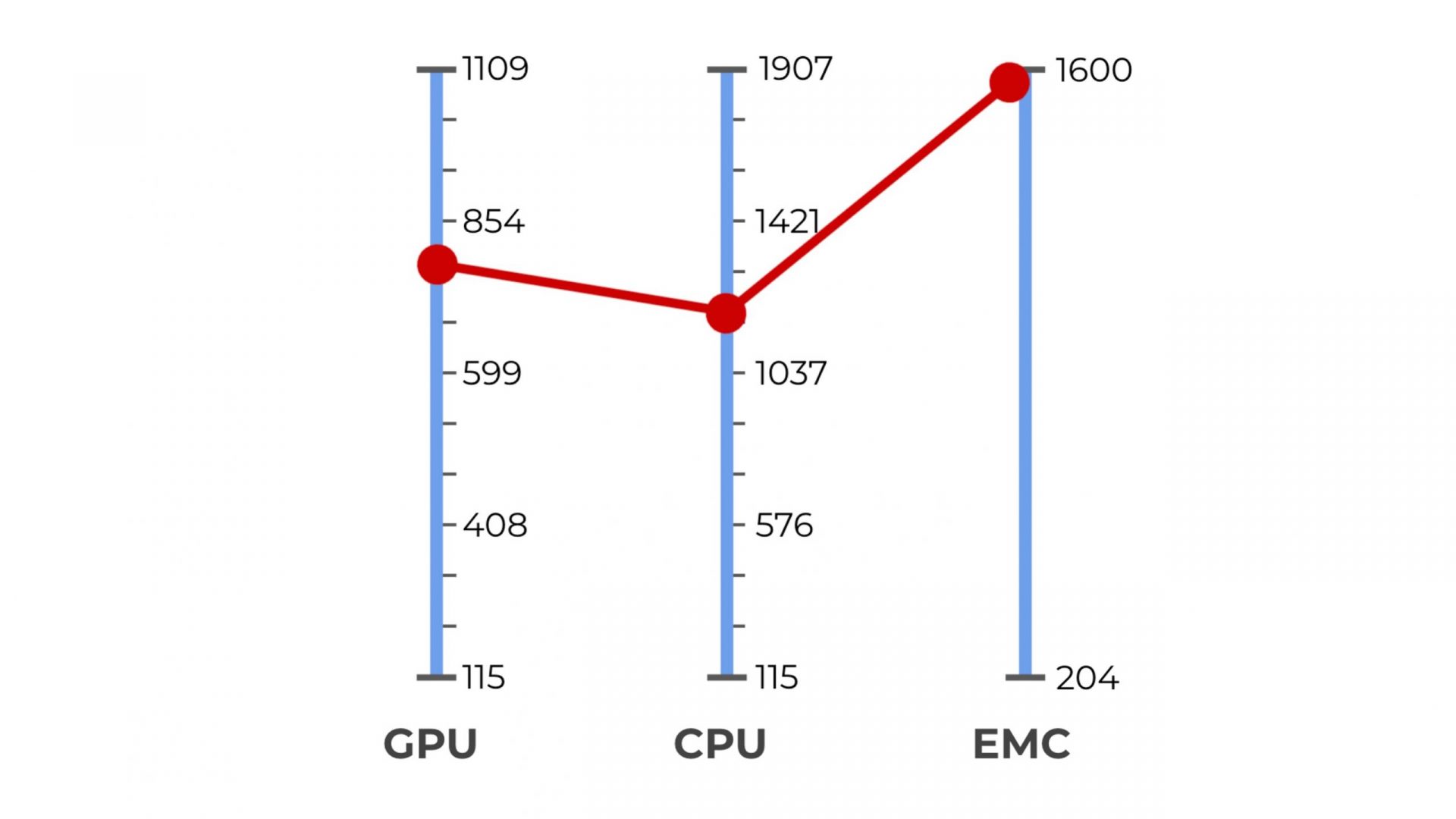
Figure 2:
Xavier NX, the supported and selected maximum frequencies of EMC, CPU and GPU
In addition, not all CPU cores are always online and visible to the OS. If you have a fan installed on your module, it also operates in a mode of which you aren’t necessarily aware. The mode is either “quiet” or “cool” and remains fixed until you change it.
Next we’ll share a few examples to demonstrate the impact of the aforementioned board’s states on the performance it will yield. We will also highlight some caveats to keep in mind when applying new settings.
Maximizing the Performance of Your NVIDIA Jetson
If it’s the first time that you hear about these details, I assume you don’t want to jump into adjusting frequencies on your own. The good news is that you don’t have to. Each NVIDIA Jetson device comes with a few optimized power budgets (e.g. for 5W, 10W, etc.) as well as with a tool called nvpmodel, which can be used either from a command line or through its GUI. It offers pre-defined power modes for each energy budget and is very easy to use. You can select a mode or even create a custom one depending on the expected workload of your application and the desired power consumption, energy source, etc.
Begin with running
$ sudo /usr/sbin/nvpmodel -q
to check the current settings on your device. You’ll see the name of the selected power mode, fan mode, etc. For example, here is a default output on NVIDIA Jetson Xavier NX:
NV Fan Mode:quiet
NV Power Mode: MODE_10W_2CORE
3
MODE_10W_2CORE doesn’t tell us everything. To learn what it incorporates either add
–verbose
to the command above or look for your Jetson series in the “Clock Frequency and Power Management Documentation”. All modes are defined in
/etc/nvpmodel.conf. Once you understand what your options are, try setting a different configuration from what you currently have with
$ sudo /usr/sbin/nvpmodel -m $ID
where ID is an index of the mode you want to select. Change the fan mode as well with
$ sudo /usr/sbin/nvpmodel -d $FAN_MODE
where FAN_MODE is either cool or quiet.
To squeeze the lemon even more, Jetson Board Support Package provides the /usr/bin/jetson_clocks.sh script that sets CPU, GPU and EMC clocks to maximum, and with a
–fan
flag makes the fan work at maximum speed as well. Run it with sudo as follows:
$ sudo /usr/bin/jetson_clocks –fan.
You might wonder how it is different from simply choosing something with nvpmodel. Well, it gives you a little something extra: each power mode defines a range of frequencies, and the current ones will be raised or lowered by the system within these ranges depending on the incoming workload. You can check these values by adding the
–show
flag to the command above. Instead, jetson_clocks.sh overrides this behavior and ensures that your application uses maximum frequencies from the given mode at all times.
Remember though that when you opt for the highest performance for your runs, you make your device work harder. It will lead to an increased power consumption and will raise the temperature of your device. To prevent throttling keep an eye on the degrees in the output of the command line utility
tegrastats
. Here is a sample output it gives:
$ tegrastats
RAM 738/3964MB (lfb 4x2MB) SWAP 253/4096MB (cached 7MB) CPU [60%@921,52%@921,off,off] EMC_FREQ 0% GR3D_FREQ 0% PLL@38C CPU@41C PMIC@100C GPU@39C [email protected] thermal@40C
In addition to the official utilities discussed here, there are also many unofficial tools (e.g. jetson_stats) that allow you to monitor the device state directly from Python.
The Impact of Using jetson_clocks.sh on Inference Performance
Let’s take a look at the latency that can be achieved on NVIDIA Jetson Xavier NX in two power modes by a few architectures compiled to TensorRT in FP32. We are going to compare the default and the maximum performance modes.
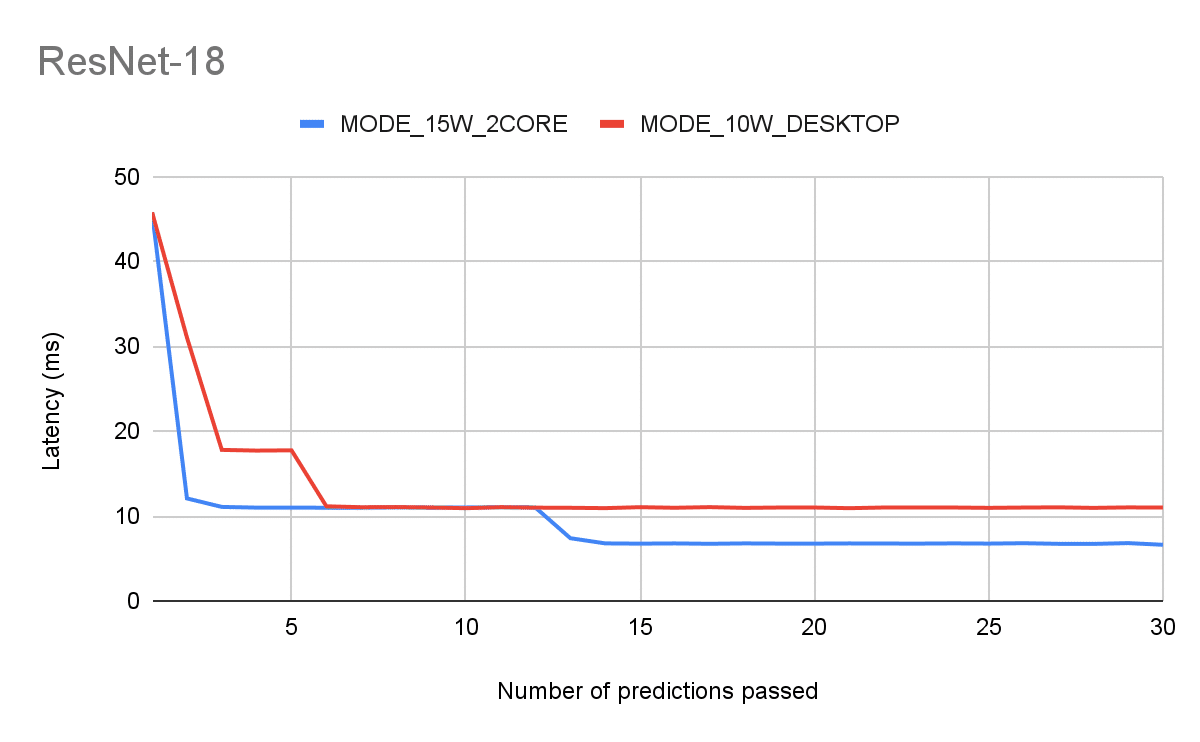
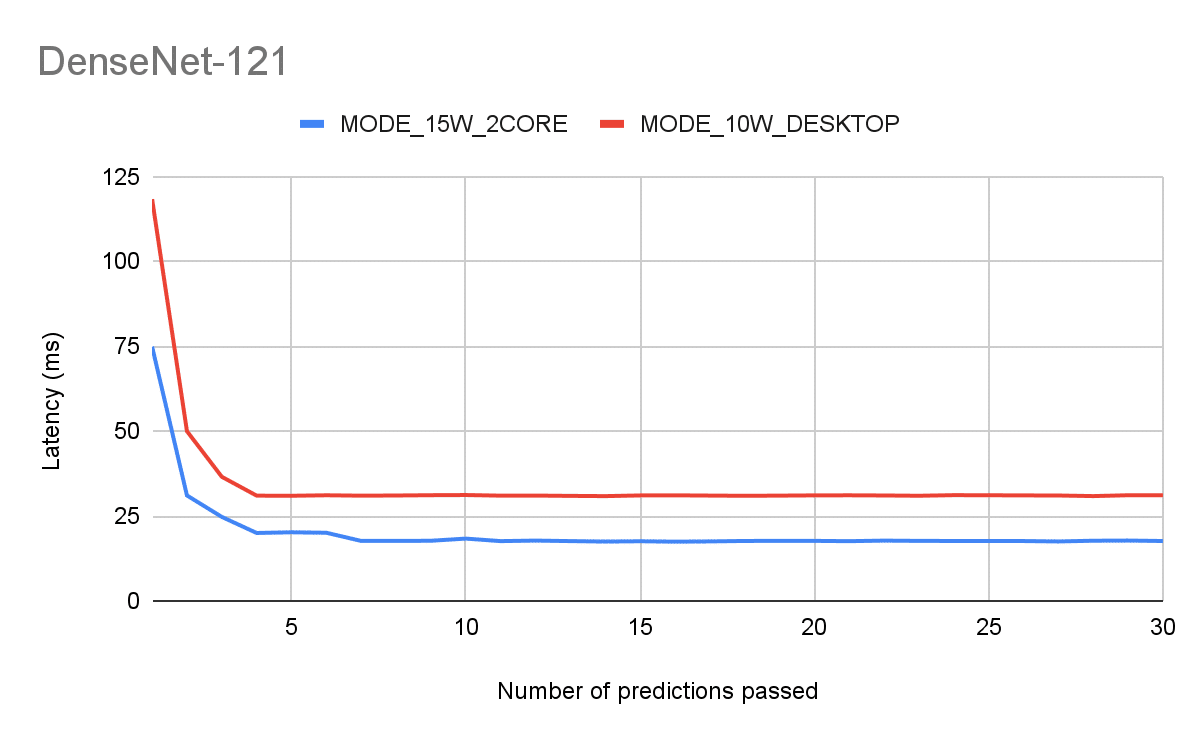
Figure 3:
Architectures: ResNet-18, DenseNet-121
Resolution: 224, Batch size: 1
Latency of N-th consequent inference
The important insights from these plots are:
- It takes a few back-to-back iterations to warm up the GPU before the latency settles on a certain number. Your app will start slow and remain slow if you don’t utilize the GPU consistently.
- Warmup aside, even after it’s done we can see that the default mode is quite inferior.
To address the first issue and reduce latency variance use jetson_clocks. Check out the results in the figures below.
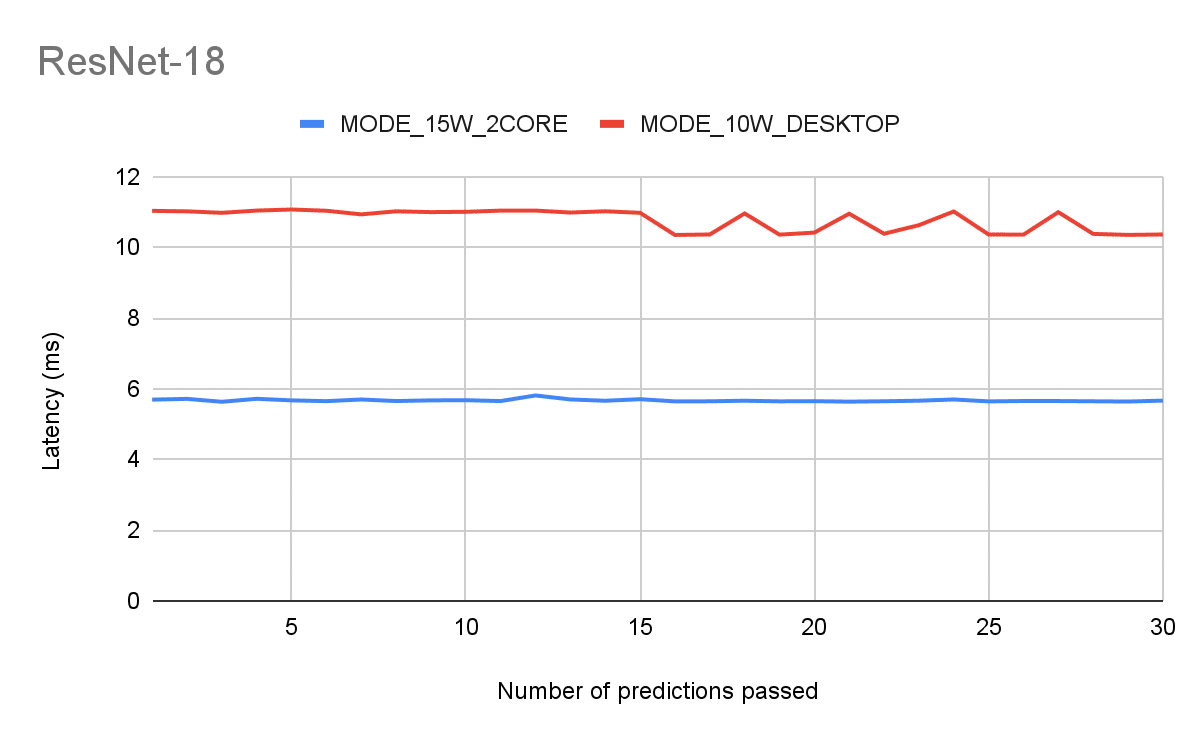

Figure 4:
Benchmarking setup equivalent to Fig 3., but after running jetson_clocks
Takeaways
To recap, in this article you got familiar with the NVIDIA Jetson architecture and learned which settings impact its performance drastically. You also saw how you can change and monitor your module’s state using the following Jetson utilities:
- nvpmodel;
- tegrastats;
- jetson_clocks.
If you’d like to learn about some of these topics in more depth, talk to one of our experts!