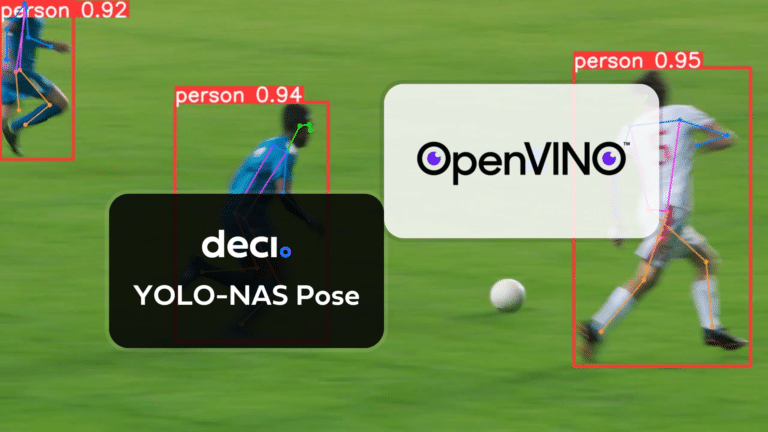
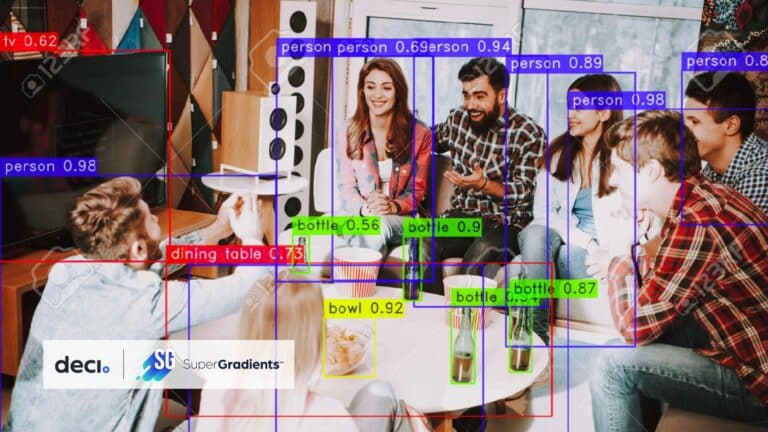
In recent years, the size of machine learning models has increased by astronomical proportions. In 2021, the largest pre-trained language model was released, the M6-10T, with 10 trillion parameters.
As ML models have become larger, significant challenges have arisen regarding their deployment, especially on edge devices. These large models cannot be deployed on devices with limited resources, such as mobile phones and IoT devices.
Additionally, the majority of data science modeling work focuses on training a single large model (or several different models) to perform well on a validation set which is often not representative of the real-world data.
This tension between training and deployment objectives leads to the development of models that may be highly accurate, but often fail to meet performance, latency, and throughput benchmarks at the time of inference on real-world test data.
Knowledge distillation is a training technique that seeks to address some of these issues. By capturing and “distilling” knowledge in a complex model and transferring it to a smaller model.
In this article, we will take a deep dive into knowledge distillation and discuss its training process and the problems this process helps solve. Moreover, we’ll discuss how you can easily leverage knowledge distillation technique with SuperGradients – Deci’s open source, “All-in-one” computer vision training library.
What is Knowledge Distillation?
Knowledge distillation is a training technique that trains small models to be as accurate as larger models by transferring knowledge. In the domain of knowledge distillation, the larger model is referred to as the “teacher network,” while the smaller network is known as the “student network.”
The teacher model can be a single large model or an ensemble of separate models, usually trained on complex data sources, including low-resolution data, multi-domain and multi-task data, or cross-modality data. After the teacher model is trained, the distillation process can capture and transfer the trained knowledge to the smaller student model, and then train the student network.
How Does the Teacher-Student Architecture Work in Knowledge Distillation?
Deep learning models are only useful if they are applicable in real-world environments. They must produce results based on immediate real-world data, which is often accessible via mobile phones and edge devices. However, large models cannot be deployed on such devices due to limited memory and storage capacity.
In knowledge distillation, the small student model learns to mimic the large model to achieve similar or even superior performance accuracy. Once the large deep neural network is appropriately compressed, it can be deployed on low-grade hardware devices to run real-world inferences.
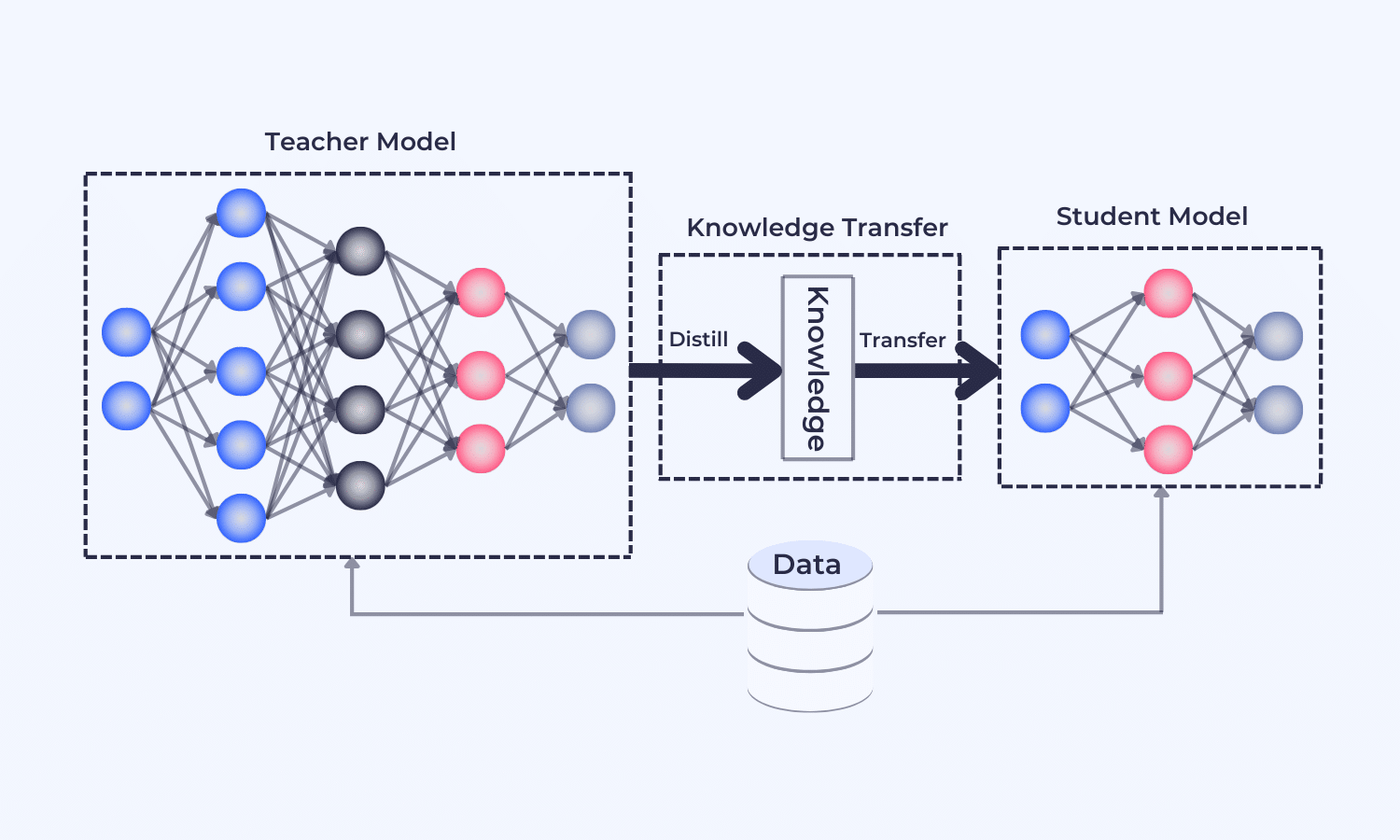
A generic knowledge distillation teacher-student architecture. Image source.
There are three types of knowledge distillation techniques, based on how the knowledge is transferred across the teacher-student network.
Let’s discuss them below.
Types of Knowledge Distillation
- Response-based knowledge distillation
Response-based knowledge distillation captures and transfers information from the output layer (predictions) of the teacher network, and the student network directly mimics these final predictions by minimizing the distillation loss. For instance, in image classification tasks, the teacher networks’ output layer generates soft targets. These are input class probabilities that contain valuable information about the teacher network, used to optimize the student network.
- Feature-based knowledge distillation
Feature-based knowledge distillation captures the information of intermediate and output layers of the teacher network. The intermediate layers contain feature activations that are directly mimicked in the student network to compress it more efficiently without losing valuable information.
- Relation-based knowledge distillation
Relation-based knowledge distillation goes beyond the intermediate and output layers of the teacher network. It explores relationships between different data samples and layers. There are three possible training schemes: offline distillation, online distillation, and self-distillation.
In offline distillation, the student network distills information from the teacher network after the teacher network has been trained completely. In online distillation, teacher and student networks are trained and updated simultaneously using parallel computing. Finally, in self-distillation, the student network learns knowledge by itself using the same network as the teacher network.
Useful Applications of Knowledge Distillation
The knowledge distillation model compression technique is widely applicable in various AI domains, including natural language processing, speech recognition, visual recognition, and recommendation systems. Moreover, knowledge distillation offers privacy-enabled model compression networks to ensure data privacy.
In each of these applications, the teacher-student architecture uses different knowledge distillation algorithms to transfer knowledge. These algorithms include adversarial distillation, multi-teacher distillation, cross-modal distillation, graph-based distillation, attention-based distillation, data-free distillation, quantized distillation, and more.
A classic example of model compression can be seen in various BERT models that employ knowledge distillation to compress their large deep models into lightweight versions of BERT. For instance, BERT-PKD, TinyBERT, DistilBERT, and BERT-BiLSTM-based model compression techniques solve multilingual tasks using lightweight language models.
Let’s discuss some technical aspects of implementing knowledge distillation using teacher-student architecture.
Some Knowledge Distillation Technicalities
A knowledge distillation mechanism has three main components: knowledge, the distillation algorithm, and the teacher-student architecture. The teacher-student architecture design determines the quality of knowledge transfer between teacher and student models. Based on this design, the teacher-student framework can observe a model capacity gap between the large and wide teacher neural network and the small and shallow student neural network.
The teacher and student models share a relationship between their network structures that enable knowledge sharing. The student network can be one of the following:
- A simplified version of the teacher network
- A quantized version that preserves the structure of the teacher network
- A similar network as the teacher model
- A network with basic operations
- A network with an optimized and condensed structure
To minimize the model capacity gap, it is best to minimize the difference between the teacher-student models using various distillations algorithms and optimization techniques. In simple knowledge distillation, the distilled model (student) is trained on the subset (transfer set) of data on which the teacher network is trained.
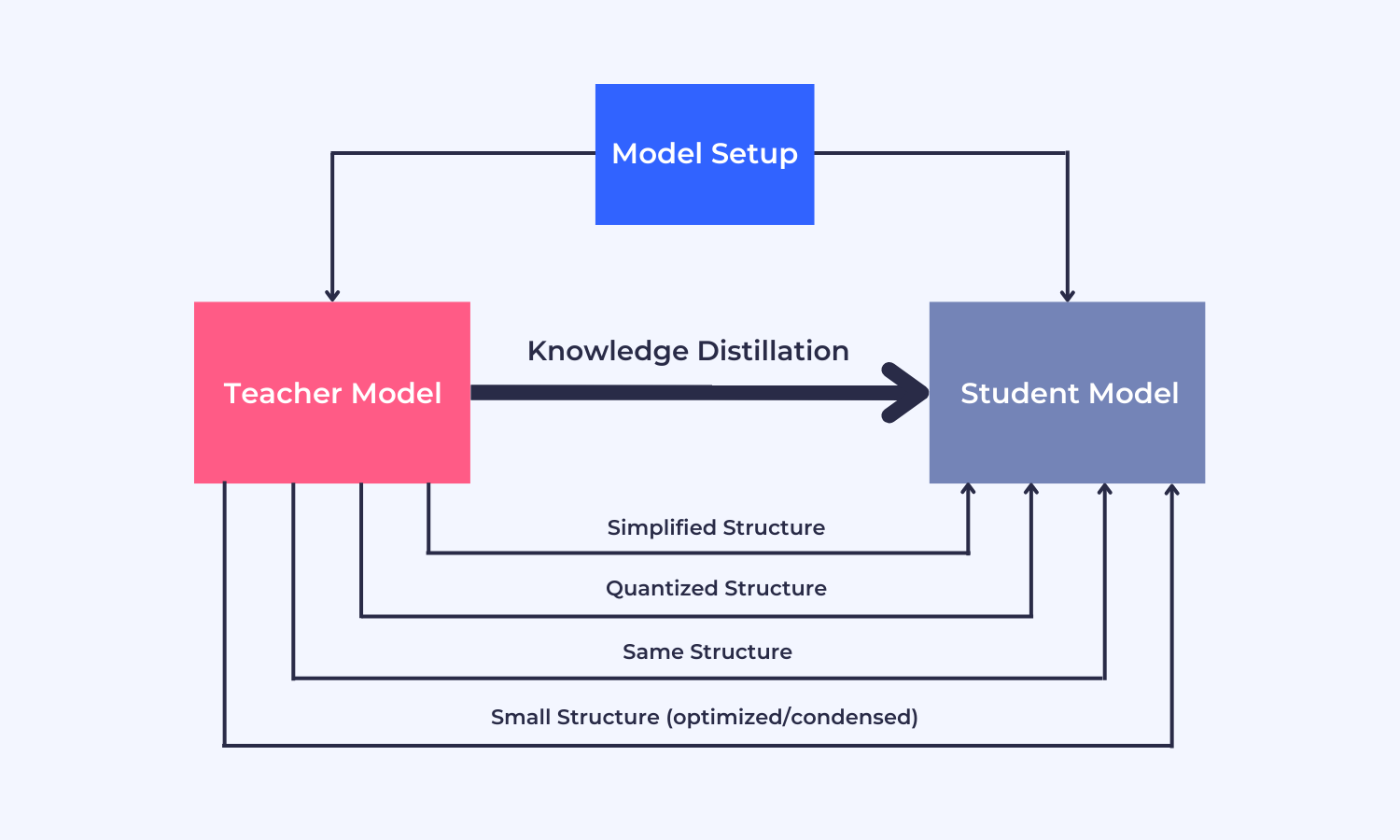
Various relationships among teacher-student networks. Image source.
Knowledge is transferred using the soft targets of the final layer of the teacher model. The student model is fine-tuned by modifying these soft targets using correct ground-truth labels. The framework uses two loss functions to make this adjustment.
Let’s discuss them below.
Optimizing Knowledge Distillation Using Distillation Loss
Typically, a knowledge distillation network used for solving classification tasks leverages the weighted average of two loss functions to optimize knowledge transfer between student and teacher models. Both loss functions are based on cross-entropy that minimizes the difference between actual and predicted values.
The first distillation loss function uses soft targets from the teacher network to optimize the output labels of the student network. The second cross-entropy-based loss (or student loss function) uses ground-truth labels and compares them with student predictions.
The final loss is calculated by averaging the two losses with considerable weight (alpha) given to the distillation loss to achieve optimal performance. The student network can be optimized effectively by giving more importance to soft targets. These targets pack important knowledge about the teacher network.
Let’s have a look at how knowledge distillation can be easily implemented using Deci’s open source training library called SuperGradients.
Knowledge Distillation Using SuperGradients Library for Image Classification
The SuperGradients open source training library offers knowledge distillation model training with a few lines of code. The following steps build a Knowledge Distillation (KD) model with a pre-trained BEiT (Bidirectional Encoder representation from Image Transformers) teacher architecture and a resnet student architecture to perform image classification. Here is a step-by-step guide for using Knowledge Distillation models with SuperGradients.
We also created a Colab Notebook for your convenience.
Step 1: Import Libraries
You will import the following components from SuperGradients to set up this experiment.
from super_gradients.training.kd_model.kd_model import KDModel from super_gradients.training.metrics import Accuracy from super_gradients.training.losses.kd_losses import KDLogitsLoss from super_gradients.training.losses import LabelSmoothingCrossEntropyLoss from super_gradients.training.datasets.dataset_interfaces.dataset_interface import ImageNetDatasetInterface from super_gradients.training import MultiGPUMode import super_gradients import torch from torchvision.transforms import Resize super_gradients.init_trainer()
Step 2: Setup Training Parameters
You have to define an optimal training parameters list to start the training process. We are using KDLogitsLoss for tuning the network and the accuracy metric to evaluate the results. You can change these parameters as per requirements.
train_params = {"max_epochs": 310,
"lr_mode": "cosine",
"lr_warmup_epochs": 5,
"lr_cooldown_epochs": 10,
"initial_lr": 5e-3,
"ema": True,
"mixed_precision": True,
"loss": KDLogitsLoss(LabelSmoothingCrossEntropyLoss(), distillation_loss_coeff=0.8),
"optimizer": "Lamb",
"optimizer_params": {
"weight_decay": 0.02
},
"train_metrics_list": [Accuracy()],
"valid_metrics_list": [Accuracy()],
"metric_to_watch": "Accuracy",
"greater_metric_to_watch_is_better": True,
"loss_logging_items_names": ["Loss", "Task Loss", "Distillation Loss"],
"average_best_models": True,
"zero_weight_decay_on_bias_and_bn": True,
"batch_accumulate": 1
}
Step 3: Setup Dataset Parameters
We are using the ImageNet dataset for this experiment which includes setting up various parameters as shown below.
dataset_params = {"resize_size": 256,
"batch_size": 192,
"val_batch_size": 256,
"random_erase_prob": 0,
"random_erase_value": "random",
"train_interpolation": "random",
"rand_augment_config_string": "rand-m7-mstd0.5",
"cutmix": True,
"cutmix_params": {"mixup_alpha": 0.2,
"cutmix_alpha": 1.0,
"label_smoothing": 0.0
},
"aug_repeat_count": 3
}
Step 4: Initialize the Knowledge Distillation Model
Define the KDModel available in the SuperGradients library. We are also enabling GPU support using the MultiGPUMode component from the SG library.
kd_model = KDModel(experiment_name="resnet50_beit_imagenet",
multi_gpu=MultiGPUMode.DISTRIBUTED_DATA_PARALLEL,
device='cuda')
Step 5: Connect Dataset Interface
Use the following code snippet to connect with ImageNet dataset interface provided by the SuperGradients library:
dataset = ImageNetDatasetInterface(dataset_params=dataset_params) kd_model.connect_dataset_interface(dataset, data_loader_num_workers=8)
Step 6: Build Knowledge Distillation Model
To build the knowledge distillation model, we are using resnet50 as the student architecture and pre-trained BEiT as a teacher architecture. We define the number of classes for student and teacher along with the image size and patch size of each image. Moreover, we are using a custom NormalizationAdapter (code shared below) to manage the range of our data.
kd_model.build_model(student_architecture='resnet50',
teacher_architecture='beit_base_patch16_224',
student_arch_params={'num_classes': 1000},
teacher_arch_params={'num_classes': 1000, "image_size": [224, 224],
"patch_size": [16, 16]},
checkpoint_params={'teacher_pretrained_weights': "imagenet"},
run_teacher_on_eval=True,
arch_params={"teacher_input_adapter": NormalizationAdapter(mean_original=[0.485, 0.456, 0.406],
std_original=[0.229, 0.224, 0.225],
mean_required=[0.5, 0.5, 0.5],
std_required=[0.5, 0.5, 0.5])})
The NormalizationAdapter used to build the knowledge distillation model is defined in the code snippet below:
class NormalizationAdapter(torch.nn.Module):
def __init__(self, mean_original, std_original, mean_required, std_required):
super(NormalizationAdapter, self).__init__()
mean_original = torch.tensor(mean_original).unsqueeze(-1).unsqueeze(-1)
std_original = torch.tensor(std_original).unsqueeze(-1).unsqueeze(-1)
mean_required = torch.tensor(mean_required).unsqueeze(-1).unsqueeze(-1)
std_required = torch.tensor(std_required).unsqueeze(-1).unsqueeze(-1)
self.additive = torch.nn.Parameter((mean_original - mean_required) / std_original)
self.multiplier = torch.nn.Parameter(std_original / std_required)
def forward(self, x):
x = (x + self.additive) * self.multiplier
return x
Step 7: Train Knowledge Distillation Model
SG performs knowledge distillation training in a single line of code, as given below. After training, the student network can perform accurate image classification on real-world data.
kd_model.train(training_params=train_params)
The Future of Knowledge Distillation
Knowledge distillation has proven useful in compressing models for different machine learning tasks. However, it has the potential to improve by trying out different combinations of compression techniques and algorithms. The combination and relationships between the structure of the teacher-student architecture determine the quality of knowledge transferred among the models.
It is also possible to distill large datasets into a small-scale synthetic dataset. In 2021, Google experimented with this approach and found promising results. They introduced two dataset distillation algorithms, namely Kernel Inducing Points (KIP) and Label Solve (LS), to reduce the size of the distilled dataset while retaining important information to generate state-of-the-art results.
Over the course of this blog you’ve learned about knowledge distillation, what it is, how it works, and its various applications. You are now ready to get started performing distillation yourself.
Head on over to Deci’s SuperGradients computer vision library to get started. SuperGradients offers full support for knowledge distillation. Try out our open-source library, or contact us to walk you through the process.