Modern machines are equipped with some of the world’s most powerful hardware devices, offering lightning-fast performance with power-efficient modules capable of processing tons of data in an instant.
Every year, hardware devices are surpassing their predecessors. Much of this hardware evolution is led by NVIDIA itself, with Jetson Orin modules being the latest in its long line of powerful computers.
In this article, we’ll discuss what the NVIDIA Jetson AGX Orin Developer Kit is and how AI teams can accelerate the performance of their deep learning models using Jetson AGX Orin and the Deci platform.
Intro to NVIDIA Jetson Orin
In March 2022, NVIDIA announced Jetson Orin modules as their most powerful AI computers specifically designed for embedded solutions, including autonomous machines, robots, and drones.
The Jetson AGX Orin developer kit can emulate the entire family of Jetson Orin modules including Jetson AGX Orin 64GB, Jetson AGX Orin 32GB, Jetson Orin NX 16GB, and Jetson Orin NX 8GB. The maxed-out variant is Jetson AGX Orin 64GB, which boosts AI performance up to 275 terra operation per second (TOPS), compared to 32 TOPS offered by the previous Jetson AGX Xavier modules.
The performance leap is due to Jetson Orin’s inclusion of an NVIDIA Ampere architecture GPU with up to2048 CUDA cores and 64 Tensor cores, together with next-gen Deep Learning and Vision accelerators. All of that together with high-speed IO and fast memory means multiple concurrent AI inference pipelines can be run at the same time.
How to Get the Most Out of Your Jetson Orin with Deci’s Platform
The Deci platform is powered by Neural Architecture Search and is used by data scientists and Machine Learning engineers to build, optimize and deploy accurate and efficient models to production. Teams can easily develop production grade models and gain unparalleled accuracy and speed tailored for their applications’ performance targets and hardware environment.
If you are planning to use the NVIDIA Jetson AGX Orin Developer Kit for your computer vision projects, here is how you can leverage the Deci platform for your projects:
- Simplify the model development process by easily finding the best model for your task and target hardware, in this case, the NVIDIA Jetson AGX Orin. This will help you ensure ultimate accuracy and inference performance from the get go.
- Easily compile and quantize any model for the Jetson AGX Orin to further accelerate your runtime performance (latency, throughput, reduce model size and memory footprint) using NVIDIA TensorRT
Access the Deci Platform
First things first, book a demo of the Deci Platform.
Find the Best Model For Your Task and NVIDIA Jetson AGX Orin Developer Kit
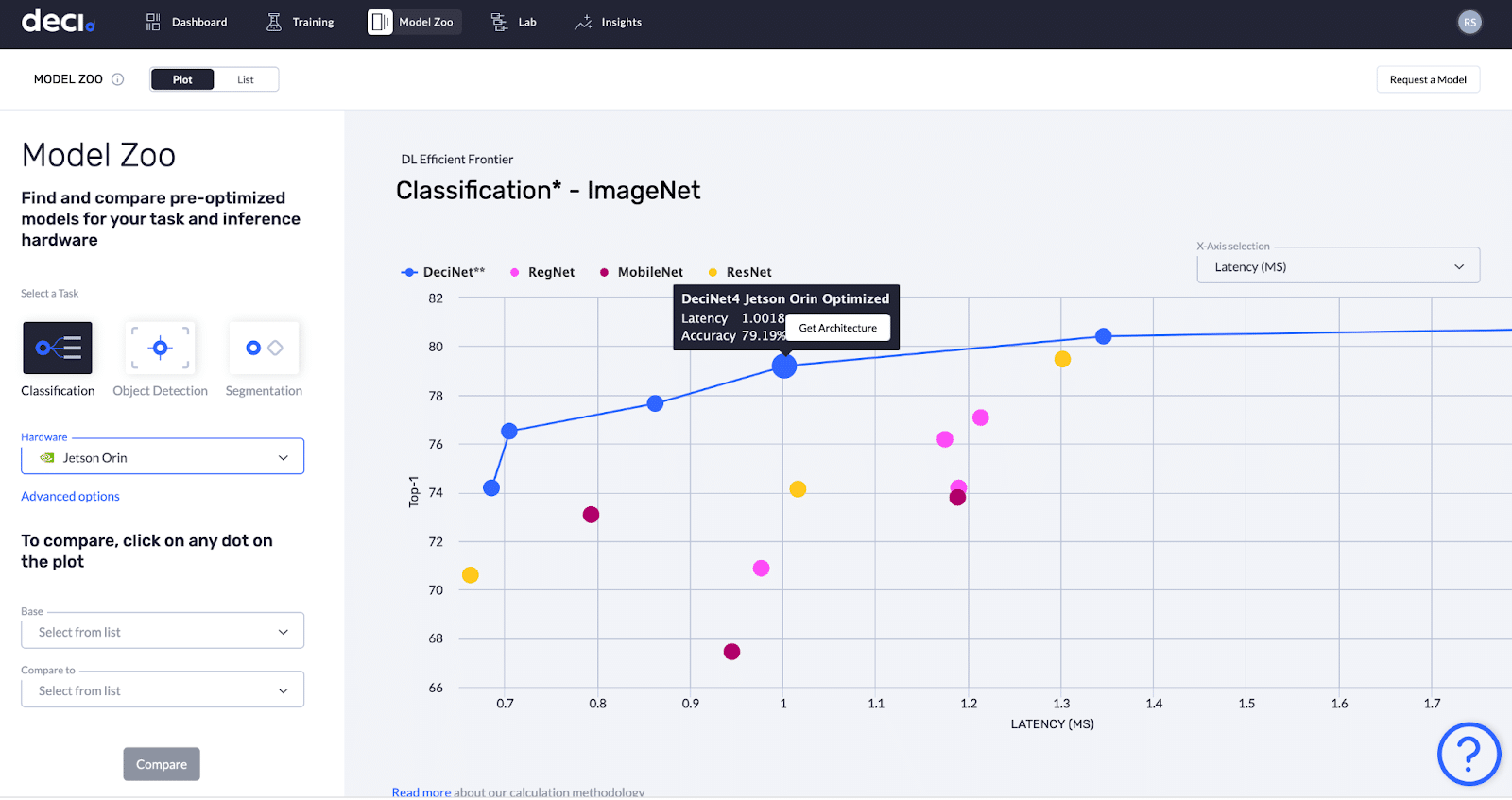
Once you’ve accessed the Deci platform, go to the Model Zoo tab. Deci’s hardware-aware model zoo allows you to see various SOTA computer vision models and their accuracy and runtime performance results (including throughput, latency, model size, and memory footprint) on various hardware types.
Select the computer vision task you are interested in. Click on the hardware dropdown menu and select the NVIDIA Jetson AGX Orin device from the list.
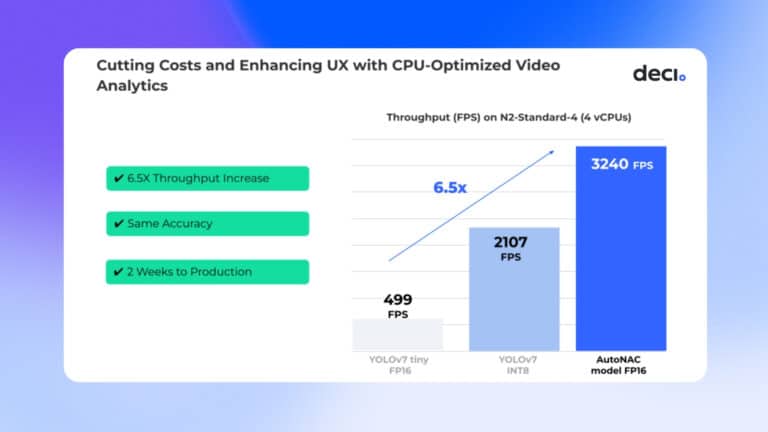
As illustrated below, you can view the accuracy and runtime performance results of the models plotted on an “Efficient Frontier” graph. This graph enables you to easily see the “accuracy-latency” or “accuracy-throughput” trade-offs measured on the NVIDIA Jetson AGX Orin developer kit. All models presented in the below chart were evaluated on a 50K validation set from ImageNet; Batch Size = 1; Quantization: FP16.
In addition to the open source models presented, this model zoo includes Deci’s SOTA DeciNet models. DeciNet models are generated by AutoNAC, Deci’s proprietary NAS-based engine and deliver superior performance over other well known models (as illustrated in the above efficient frontier graph).
In the graph above, the blue dots represent different versions of DeciNet image classification models. As you can notice, these models deliver better accuracy-latency / accuracy-throughput tradeoff compared to known SOTA classification models.
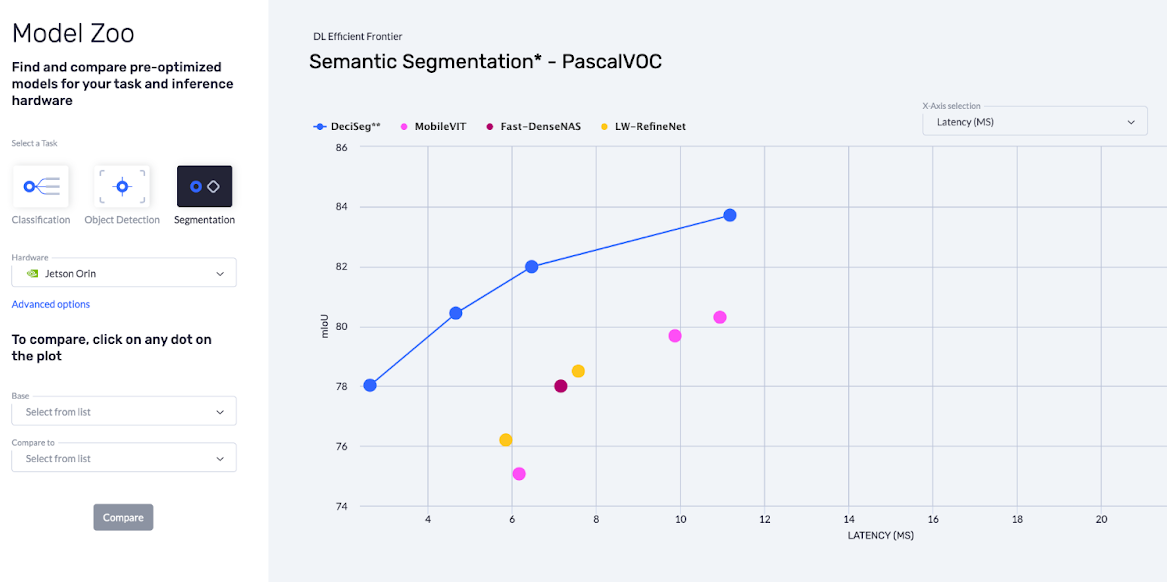
Similarly, the Efficient Frontier for Semantic Segmentation is shown below. The models presented in this graph are trained on the PascalVOC dataset and optimized to run on the Jetson AGX Orin device. Like the classification models, DeciSeg models outperform other open source SOTA Semantic Segmentation models such as Fast-DenseNAS, MobileVIT and LW-RefineNet among others.
In Image 1 below you can see an example of the performance gains that can be achieved by leveraging both NVIDIA TensorRT™ and Deci’s AutoNAC™ engine on the NVIDIA AGX Orin™ developer kit.
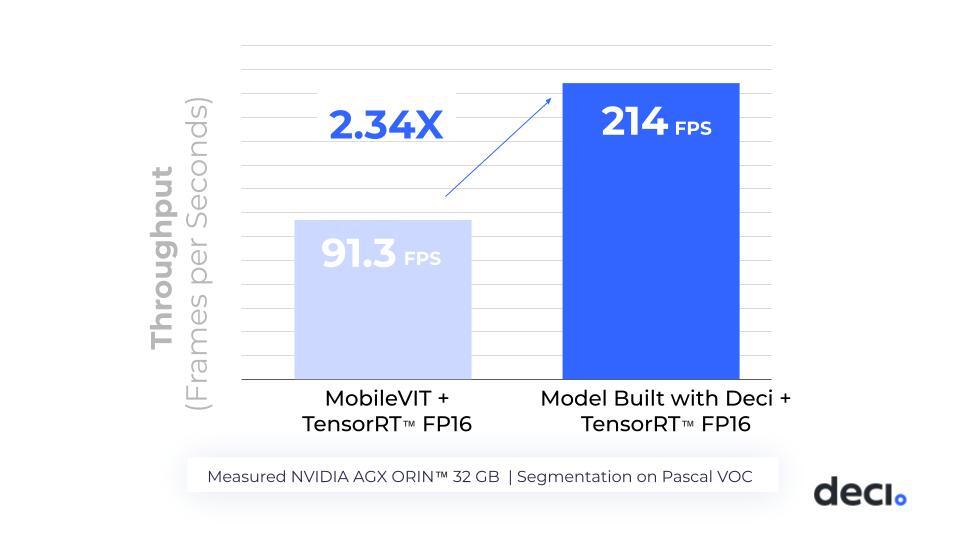
By taking the MobileVITV2-1.5 model and applying compilation and 16 bit quantization with NVIDIA TensorRT, one can reach a throughput speed of 91.3 frames per second. By building a superior architecture with Deci and then applying the same compression (using TensorRT), one can gain a 2.34x higher throughput to reach 214 frames per second on the NVIDIA Jetson AGX Orin Developer Kit. The model generated with Deci’s AutoNAC engine is not only faster but also more accurate (80.44) compared to MobileVIT (80.3)
If your existing model doesn’t meet your performance targets, you can leverage Deci’s AutoNAC to build a model specific to your needs.
AutoNAC performs a multi-constraints search to find the architecture that delivers the highest accuracy for any given dataset, speed (latency/throughput), model size and inference Hardware targets. With AutoNAC, AI teams typically gain up to 5X increase in inference performance compared to state-of-the-art models (the range is between 2.5-10x depending on various factors).
How to Easily Compile and Quantize your Model for Accelerated Performance on Jetson Orin
If you already have a model and want to understand how it will run on a Jetson AGX Orin developer kit, Deci can help. Go to the Deci lab tab and click the New Model button in the top right corner, as illustrated below.
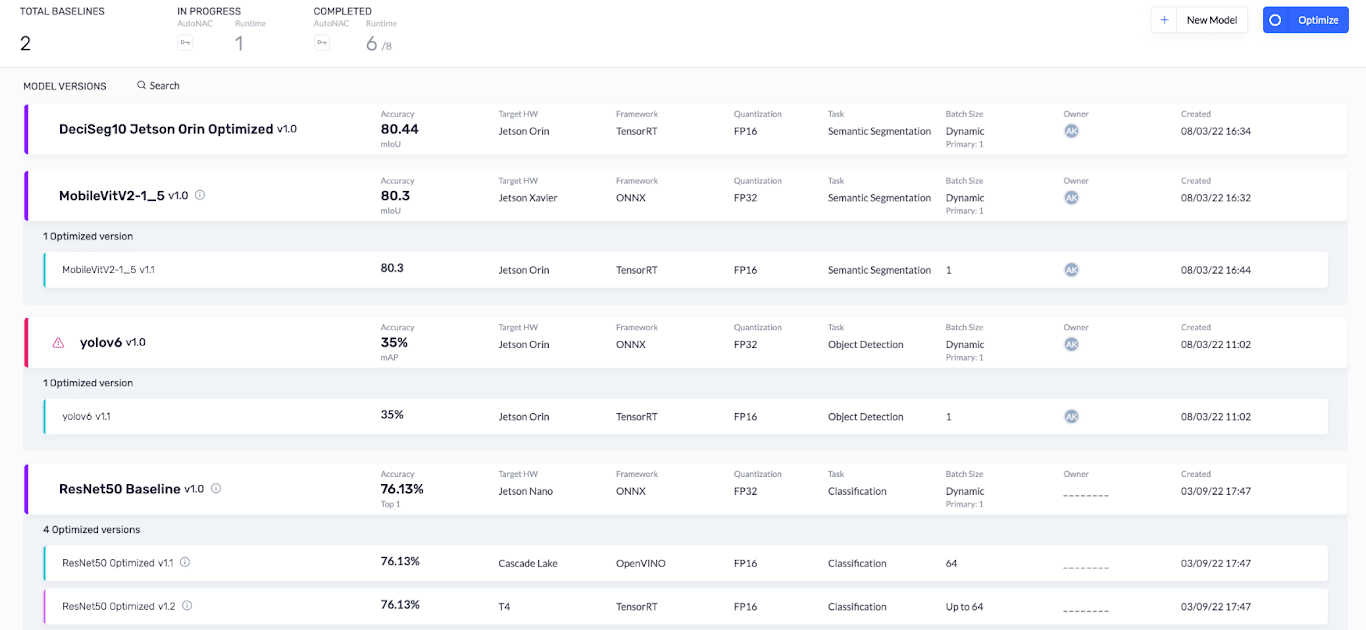
Observe Model Insights
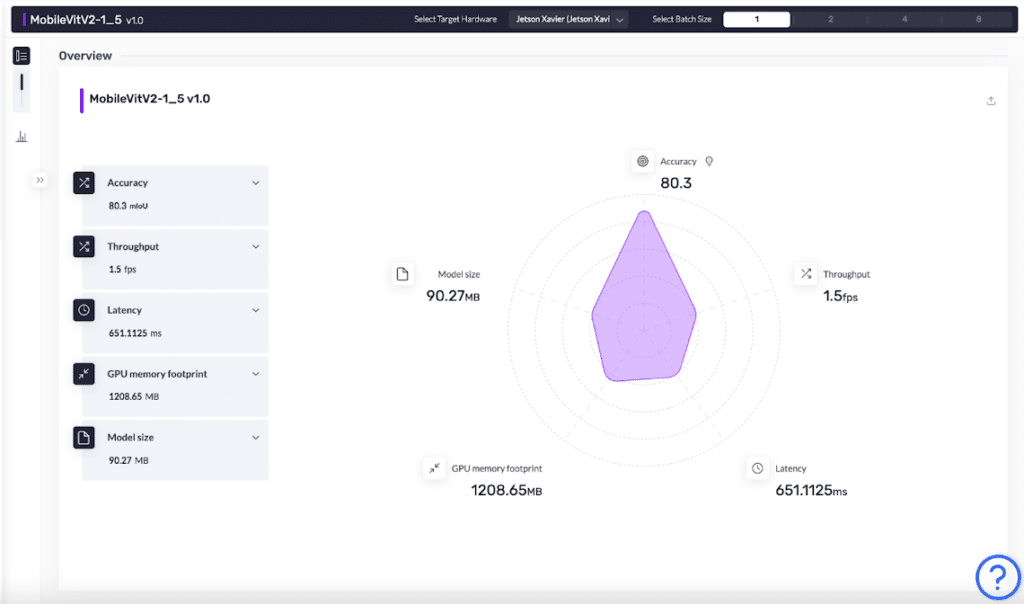
Click on the Insights button in front of the MobileVit model to open its detailed view, as shown below.

- Throughput: measure in frames processed per seconds
- Latency: delay in performing inference measured in milliseconds
- Model size: physical space consumed measure in Megabytes
- Memory footprint: RAM used during inference while running in Megabytes
Below you can see the performance metrics of the MobileVit baseline model:
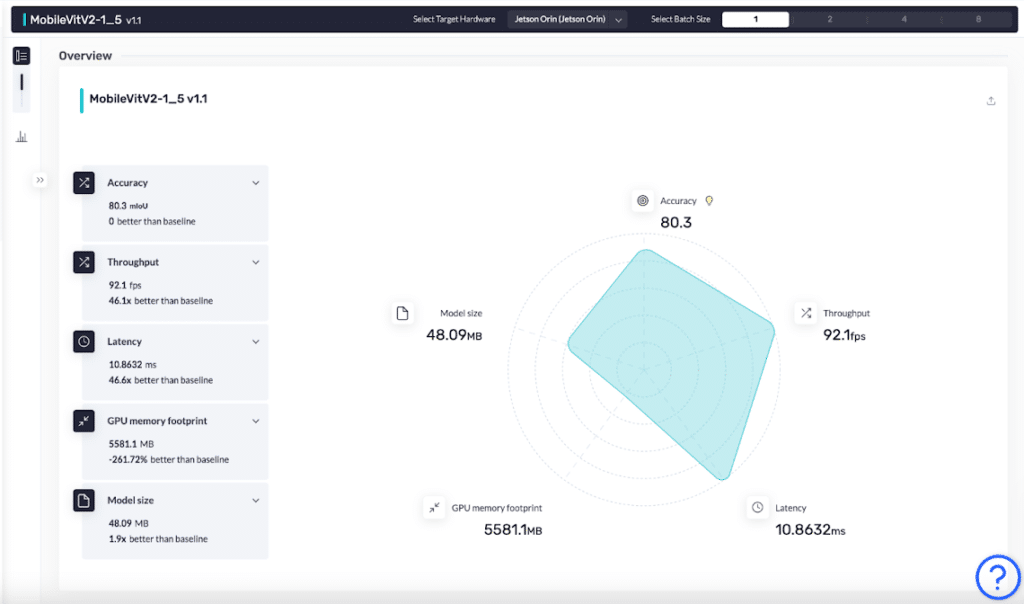
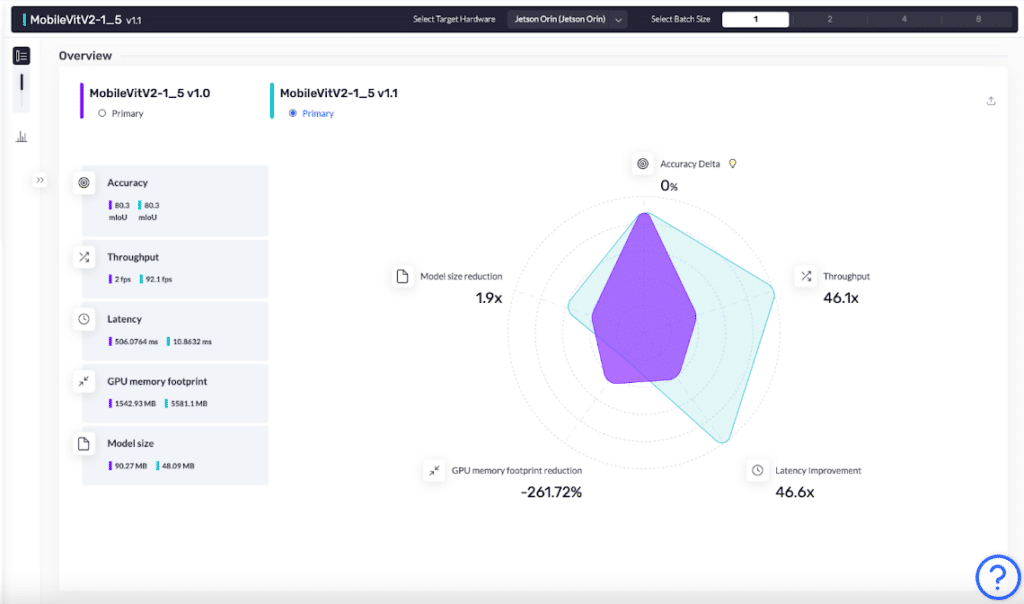
- The optimized model’s throughput improved from 1.5 fps to 92.1 fps. The model is now 46.1 times faster.
- The size of the model was reduced by 1.9 times, from 90.27 MB to 48.09 MB.
- The model’s latency improved by 46.6 times from 651.1 ms to 10.8 ms.
Sometimes, even after you have optimized your model using compilation and quantization, it may not reach your desired performance on your targeted hardware. This is because not every model is suited for every hardware. If you are still unsatisfied with your model performance you might need a model that is better suited to your hardware. At this point, you can request access to Deci’s AutoNAC engine in order to generate your custom trainable architecture.
Over the course of this blog you’ve learned how to boost the overall performance of your models using the NVIDIA Jetson Orin hardware and how to get the most out of it using the Deci platform. You’ve also learned about DeciNets’ superior performance over other SOTA models and about the AutoNAC NAS engine that can generate models customized to your needs.
If you are interested in learning more about how the AutoNAC engine works, read our white paper on AutoNAC.
You can get started today by booking a demo of the Deci Platform.