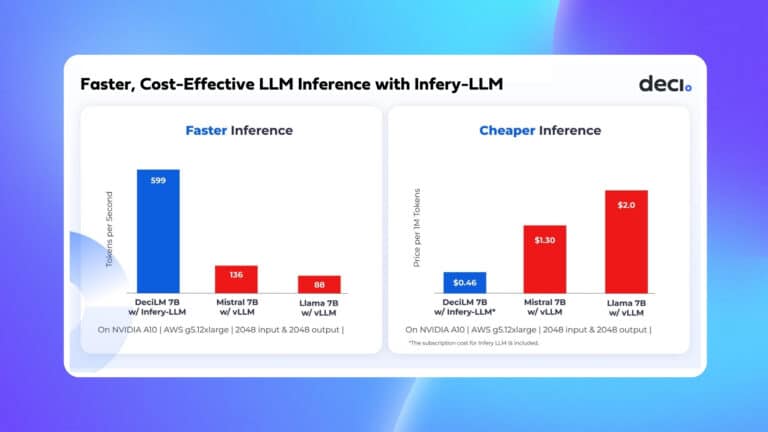
Deploying deep learning models to production is not an easy task. To deploy models, engineers cope with a wide range of challenges in the realms of hardware architecture, software dependencies, scaling, monitoring, profiling, and more. These challenges often become significant pain points for companies, resulting in wasted time and resources, and missed business opportunities. Infery, Deci’s high-performance inference engine, helps teams tackle these common issues and simplifies the deployment of deep learning models.
In this blog, we review Infery’s key features and their benefits. We also share the latest and greatest features that equip you with the ability to get even more compute power out of your hardware devices.
4 Common Deep Learning Deployment Challenges and How to Solve Them with Infery:
#1 Framework Portability
The ecosystem of deep learning frameworks is vast and diverse. From ONNX to PyTorch to Tensorflow and TensorRT, the list of possible inference frameworks is long. These different frameworks vary in terms of their ease-of-use, performance on different machines, and community support. Moving across frameworks can be a headache and means extra manual work.
How Does Infery Help You?
No more trying to learn and integrate different libraries. You get one unified API for inference on all frameworks.
#2 Incompatibility of Hardware and Software
Making sure the hardware and software environment is compatible with your model can be a daunting task. It involves managing dependencies, installing a plethora of software libraries, and maintaining a tested and up-to-date compatibility matrix.
How does Infery help you?
Infery offers optimized Python wheels and well-tested Docker containers that are ready with Infery pre-installed. The Docker images come in different flavors (tags), and you can pull an image that includes the minimal dependencies, without unnecessary frameworks – all based on your use case. This helps keep the container small in size, which is very important at scale.
Need to benchmark an ONNX model on a CPU instance? All you have to do is pull the latest Infery container with ONNX for the CPU tag (3.9.0-cpu-onnx at the moment). Need to benchmark a TensorRT model on an NVIDIA GPU instance, with no Docker? Just pip install infery-gpu[tensorrt], and you’ve got a basic working environment.
#3 Scaling and Performance
Deploying deep learning models at scale can get complicated, especially when you’re dealing with high levels of concurrency. Ensuring that the system can scale and maintain optimal performance is critical. If set up incorrectly, your inference runtime can run into unnecessary bottlenecks, like excess synchronization between the GPU and CPU. You may even end up preventing a server’s main thread from handling incoming requests, all because of GPU inference that isn’t even related and is running in parallel. These issues become more pertinent and painful as your application grows in scale.
How does Infery help you?
Infery lets you streamline deployment and boost serving performance using parallelism and concurrent execution.
- Concurrent (asynchronous) inference. Infery runs multiple prediction (forward pass) calls simultaneously so it increases throughput by handling more queries per second.
- Faster pre/post processing on the GPU. Infery reduces data copies. Each model can consume tensors on the CPU or the GPU, and the same theorem applies for the outputs.
- Benchmarking ability. Infery makes it easy to benchmark any model on any hardware to ensure you can maximize the hardware utilization and are able to reproduce the results. This allows you to understand the theoretical limits of your application and ensure you are using the most accurate model you can without losing performance.
- Profile model performance per layer in the neural network. Infery can compute the time it takes for each layer in your model, allowing you to quickly discover your model’s bottlenecks using a single command.
#4 Hardware Costs and Resource Constraints
Deploying and maintaining deep learning models can be expensive, so ensuring that the system is cost-effective and resource-efficient is critical. Teams are under utilizing their GPUs due to incorrect or suboptimal runtime configurations.
How does Infery help you?
With Infery, you easily leverage several engineering and memory management approaches that can help you maximize the hardware potential to the fullest.
- Infery has built-in support for pinned memory. When memory is ‘pinned’ it improves the performance and stability of the inference process because the kernel is prevented from paging out the pinned buffer. This can lead to much faster data transfer (thanks to GPU DMA mechanisms) and overall reduced inference latency.
- All data copies are asynchronous. Each memory copy kernel runs on an independent CUDA stream, keeping the main CUDA stream free. This helps Infery to run alongside external CUDA code used by other libraries, like Torch, TorchVision, TensorFlow, etc.
Get Superior Hardware Utilization with Asynchronous Inference
Once a model is trained and optimized, it can be loaded into the machine’s memory to make predictions. The real challenge lies in ensuring that the hardware on which the model is loaded is fully utilized. How do you leverage the power of your machine to its fullest extent? How can you “squeeze the last drop” out of every processing unit?
With GPUs in general, and especially in the pay-per-instance cloud, we strive to reach high GPU utilization in every instance. It’s simple math: two GPU instances that reach 50% utilization will cost twice as much as a single GPU instance at 100% utilization while providing the same amount of computational power. Often, the reason for suboptimal GPU utilization comes from CPU pre/post processing that prevents the GPU from performing inference. But, if you run multiple inference requests at the same time, you can concurrently perform inference with your model on a GPU all while preprocessing/postprocessing run on the CPU.
Concurrent inference offers several benefits:
- Increased throughput. With concurrent inference, an inference server can process multiple requests simultaneously, thereby increasing the overall throughput of the server.
- Decreased latency. Concurrent inference can also improve the latency of the inference server. If the preprocessing of a request can begin before the GPU completes the inference of a previous request, it’s possible to substantially cut down the overall latency to serve a request.
- Resource utilization. By processing multiple requests concurrently, an inference server can make more efficient use of the available hardware resources, such as CPUs and GPUs. This translates directly into better resource utilization and more cost-effective inference.
- Scalability. Concurrent inference can also improve the scalability of an inference server. As the number of requests increases, the server can scale up to handle more requests by processing them concurrently, rather than having to rely on scaling up individual resources.
How to Run Concurrent Inference with Infery
The workflow is pretty simple when it comes to running concurrent inference. Pseudo-code for concurrent inference might look like this:
- Prepare/Receive/Read N input tensors.
- Dispatch N corresponding inference tasks (requests). Save a reference to those tasks.
- Wait for N tasks to be ready.
- Postprocess: Do something with the task’s results (model outputs).
- Return a response to the user
- Write to a database
- Write to an attached media or disk
Let’s look at an example of how Infery can simplify concurrent inference, for any given model.
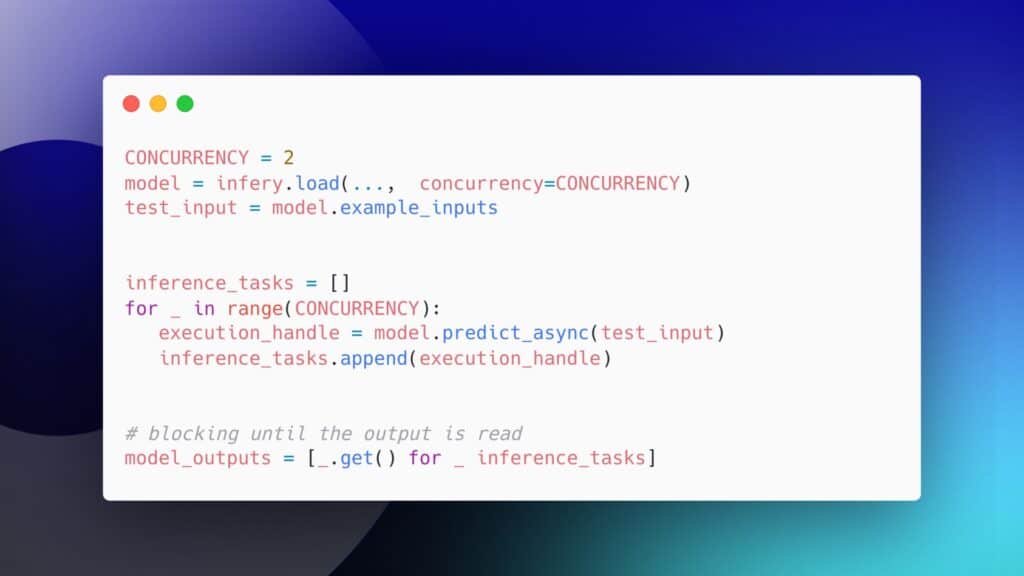
Example asynchronous inference with Infery:
CONCURRENCY = 2 model = infery.load(..., concurrency=CONCURRENCY) test_input = model.example_inputs inference_tasks = [] for _ in range(CONCURRENCY): execution_handle = model.predict_async(test_input) inference_tasks.append(execution_handle) # blocking until the output is ready model_outputs = [_.get() for _ inference_tasks]
The Effect of Concurrent Inference on Computer Vision Models
In computer vision models, the inputs and outputs of a model tend to be large.
A typical (float32) RGB input tensor of batch size 64 with a resolution of 224 x 224 pixels and 3 channels, is around 38 MB in size. When handling such high volumes of large data, data copies become a bottleneck. Asynchronous inference enables us to run computations on the GPU while performing these data copies from the CPU to the GPU and back, using the CUDA API.
Essentially, we are completely hiding the data transfer latency because it takes place during inference. Instead of blocking the main CUDA stream, we use several streams and the data is copied while the GPU computes the outputs of the model for another request.
Below is an Infery code snippet that demonstrates this substantial boost:
Let’s load a model using infery.load:
CONCURRENCY = 4 WARMUP_ITERATIONS = 100 model = infery.load( model_path="yolox_s.engine", framework_type="trt", concurrency=CONCURRENCY, output_device='cpu' )
Now, let’s execute concurrent inference using Infery’s predict_async method.
# Get an async execution handle and block until the output is ready execution_handle = model.predict_async(pinned_memory_inputs) execution_handle.get() # Warm up the GPU for benchmarking [model.predict(pinned_memory_inputs) for _ in range(WARMUP_ITERATIONS)]
In order to use predict_async, we need to dispatch several requests at once.
The following code snippets compare the regular predict() method, which runs inference for given inputs and returns the outputs of the model with the predict_async() method, which runs inference without blocking the main Python thread.
Synchronous inference:
start = time.perf_counter()
for i in range(100):
model.predict(pinned_memory_inputs)
sync_e2e_ms = (time.perf_counter() - start) * 1000
Asynchronous inference:
tasks = []
start = time.perf_counter()
for i in range(100):
tasks.append(model.predict_async(pinned_memory_inputs))
[task.get() for task in tasks]
async_e2e_ms = (time.perf_counter() - start) * 1000
Printing the difference between synchronous and asynchronous inference:
print(f'Predict Asynchronous took: {async_e2e_ms:.2f} [ms]')
print(f'Boost from using Asynchronous inference: {100 * (1 - (async_e2e_ms / sync_e2e_ms)):.2f}% Speedup')
The resulting output on an NVIDIA A4000 mobile GPU shows that:
- Predict synchronous took: 2949.63 [ms]
- Predict asynchronous took: 2140.77 [ms]
- Boost from using asynchronous inference: 27.42% speedup
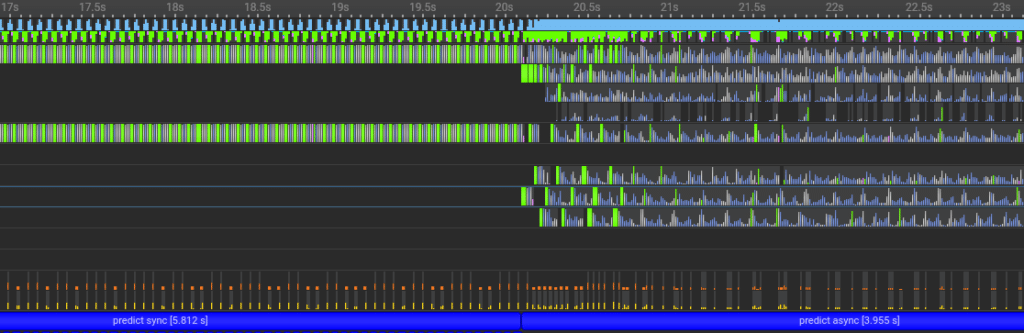
To highlight the advantages of asynchronous inference, we had Infery generate a profile while executing the code excerpt above. The left half of the profile demonstrates normal, synchronous predict calls. The top row shows GPU activity. On the left hand side, you can see periodic gaps in this activity, as opposed to the right hand side, in which just under 100% of the GPU is utilized 100% of the time.
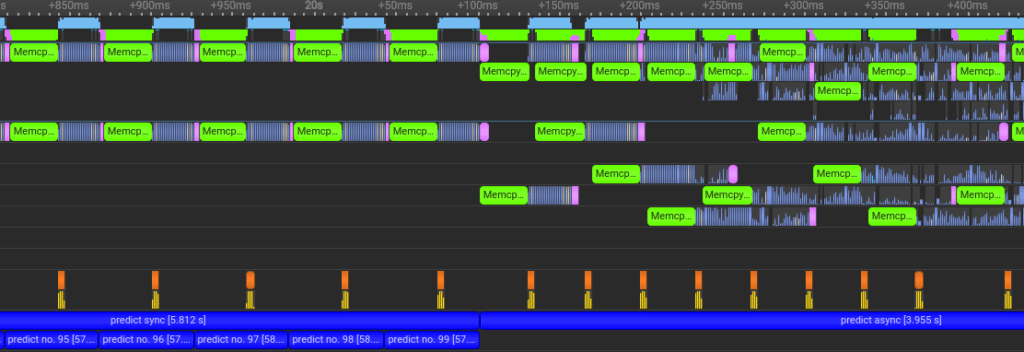
The second profile, shown below, illustrates a close-up of the latency that is hidden when we use predict_async. In the left half of the profile, the data transfers (the green and pink boxes) never overlap with inference calls (the blue boxes that correspond to CUDA kernels). Meanwhile, on the right half of the profile, CUDA kernels are executing the entire time, all while data transfers continue:
Preventing Unnecessary Transfers of Data from the GPU to the CPU
Often, an application will be required to keep the outputs of an inference call in the GPU memory rather than transferring it back to the CPU. This is helpful when post-processing is computed on the GPU. With Infery, we avoid unnecessary data copies from the CPU to the GPU and back from GPU to CPU. Instead, we use a buffer and copy the model’s output from the GPU to another GPU memory allocation, using CUDA’s cuMemcpyDtoDAsync method.
This way, our model outputs are memory-safe and the model can process more queries without overriding the old one. This can be accomplished in Infery by simply adding the output_device parameter when loading a model, and all inference results will be returned as PyTorch Tensors on the GPU:
CONCURRENCY = 4 model = infery.load( model_path="yolox_s.engine", framework_type="trt", concurrency=CONCURRENCY, output_device='gpu' ) output_tensor_async = model.predict_async(pinned_memory_inputs).get()[0]
Post-processing is something we usually need to help an application utilize a model’s outputs to draw meaningful conclusions. Similarly, pre-processing is a crucial (and often compute-intensive) requirement if we want to integrate a model into an application that gets input data from the real-world. To help software engineers develop high-performance deep learning applications, Infery automatically detects the device (CPU/GPU) on which the provided inputs reside and transfers the data only if necessary. The user may provide Infery with a Python list or dictionary of Numpy ndarrays on the CPU, PyTorch Tensors on the CPU, or PyTorch Tensors on the GPU. Infery will perform inference with these inputs and only transfer the data between the host and the device if absolutely necessary. An example of this functionality appears in the code snippet below:
# Load a YOLOX Small model with a single input named "input"
model = infery.load(model_path='/tmp/yoloxs.engine', framework_type='trt')
# Create Numpy (always CPU) test inputs
np_list = [np.random.rand(1, 3, 640, 640).astype(np.float32)]
np_dict = {'input': np.random.rand(1, 3, 640, 640).astype(np.float32)}
# Create Torch CPU and GPU test inputs
torch_cpu_list = [torch.randn(1, 3, 640, 640)]
torch_cpu_dict = {'input': torch.randn(1, 3, 640, 640)}
torch_gpu_list = [torch.randn(1, 3, 640, 640).to('cuda')]
torch_gpu_dict = {'input': torch.randn(1, 3, 640, 640).to('cuda')}
# Perform inference using all possible formats
for test_input in [np_list, np_dict,
torch_cpu_list, torch_cpu_dict, torch_gpu_list, torch_gpu_dict]:
model.predict_async(test_input).get()
Accelerating NLP Models with Concurrent Inference
In language models, both inputs and outputs are usually smaller in size as compared to computer vision models. A paragraph of 786 characters might be represented as a tensor of size (1,786) with unsigned-int data type, adding up to a total of only 3.144 KB–as opposed to the example of our computer vision data at 38MB.
Let’s see how Infery helps us perform asynchronous inference on an NLP model with a TensorRT compiled model:
tokenizer = AutoTokenizer.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english"
)
CONCURRENCY = 2
model = infery.load(
model_path="bert_sts_model.engine",
framework_type="trt",
concurrency=CONCURRENCY
)
sentence = "While deep learning model deployment can be challenging, the benefits make the effort well worth it"
tokenized_inputs = tokenizer(
sentence, return_tensors="np", max_length=384, padding="max_length"
)
input = {k: v.astype('int32') for k, v in tokenized_inputs.data.items()}
output = softmax(model.predict_async(inputs).get()[0])
# Output’s index 1 holds the confidence of the model in a positive sentiment
sentiment = output[1] * 100
print(f"{sentiment:.2f}% positive.", "Sentence:", f'"{sentence}"')
By running the code, we get the following output:
99.82% positive. Sentence: “While deep learning model deployment can be challenging, the benefits make the effort well worth it”
A profile taken while executing code similar to that shown above again demonstrates the increase in GPU utilization (the top, teal row) when we move from normal predict calls to predict_async usage:
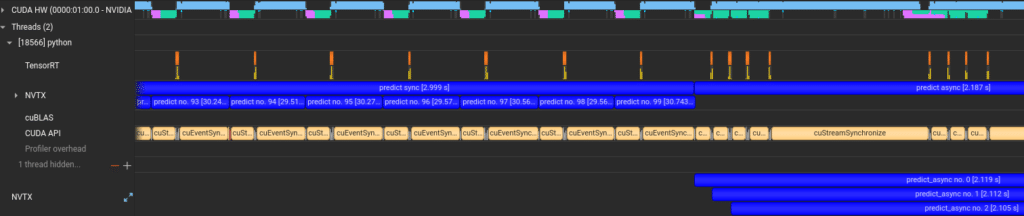
When we performed a benchmark similar to that shown for the computer vision example, the boost from simply using asynchronous inference over multiple samples provides a 13.44% speedup. Although this is lower than the IO-heavy computer vision use case, it’s still impressive for a two-line change.
In the figure above, we dispatched several predict_async calls. Each call is represented by a blue line in the NVTX section (bottom of the figure). The CUDA-HW section (the top row) is more utilized – includes less blank areas – when using asynchronous predictions.
When zooming in, you can see that 4 streams are being used in the middle of the figure.Memory-Copies and Model Forward-Pass are done concurrently using different streams, and this improves the CUDA HW (top row) utilization.

Profiling Model Layers
Another great power feature that Infery provides for all ONNX and TensorRT models is layer profiling. After loading an engine, with just a 1-line call to the get_layers_profile_dataframe method you can get a table showing the latencies for each of the deep learning model’s layers. This is especially useful for weeding out slow and unexpressive layers that hurt a model’s performance much more than they improve its latency. Here’s a simple example on how to generate a dataframe of the model layers, and the time each layer takes in ms:
model = infery.load( model_path="resnet18.engine", framework_type="trt", profiling=True ) model.get_layers_profile_dataframe()
And the corresponding output:
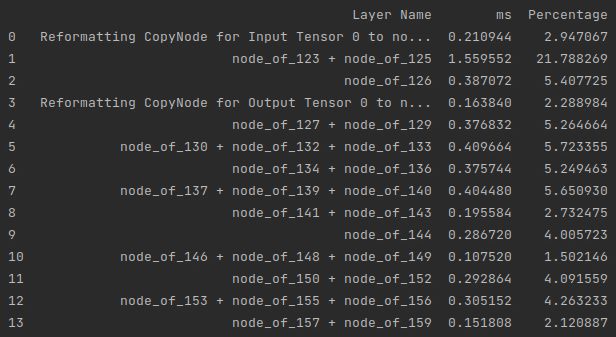
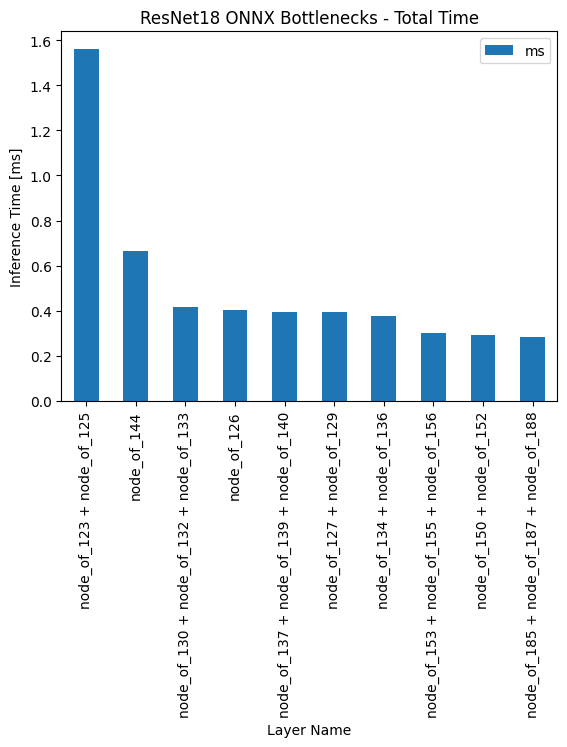
Once you’ve got a list of the layer profiles, calling the model.get_bottlenecks method will sort the layers and leave the most problematic ones at the top of the list. Below is an example of this method, along with the creation of a plot to illustrate the results provided.
bottlenecks = model.get_bottlenecks(num_layers=10)
ax = bottlenecks.plot.bar(
x="Layer Name", y="ms", rot=90, title="ResNet18 ONNX Bottlenecks - Total Time"
)
ax.set_xlabel("Layer Name")
ax.set_ylabel("Inference Time [ms]")
# Plot total time (ms) spend in each layer
ax = bottlenecks.plot.bar(
x="Layer Name",
y="Percentage",
rot=90,
title="ResNet18 ONNX Bottlenecks - Percentage",
)
Streamlining Deployment and Boosting Serving Performance
Infery is a model inference engine that uses parallelism and concurrent execution to streamline deployment and boost serving performance. By leveraging the power of asynchronous threading, it is enabling AI models to achieve higher throughput and lower latency – exactly what you need for the real-time processing of large volumes of real-world data. Infery does all the heavy lifting so that all you need to do is write a couple of lines of code.
Incorporating Infery into your deep learning workflows lets you optimize model performance and deliver faster, more accurate predictions – no matter where inference takes place.
Check out Infery on Github: https://github.com/Deci-AI/infery-examples or learn more about Infery on here: https://deci.ai/deploy-deep-learning-models-infery/