
There’s a lot of discussion around deep learning, and AI in general, and which approach is better: data-centric or model-centric. In this blog post, we will take a deep dive into both approaches and discuss the benefits and drawbacks of each discipline. By the end of this post, you’ll have a better understanding of both approaches, and discover a more holistic way to develop deep learning applications that can fit any task, set of constraints, and environment.
The Holy Trinity of Deep Learning
AI systems are based on the pillars of model architecture, data, and compute. These three components can be regarded as the holy trinity of deep learning. While often, these components are worked on in silos, there is in fact great interplay between them.
A suboptimal relation between model and data can lead to overfitting or underfitting, and therefore, models should be optimized for the data and the problem that we are trying to solve. Another example is the relation between model architecture and inference hardware. Models do not run as effectively on different hardware. Each hardware type works in different ways in terms of what it is able to parallelize, what operator it runs more efficiently and memory cache sizes. An ideal model architecture would utilize these attributes in the best way possible.
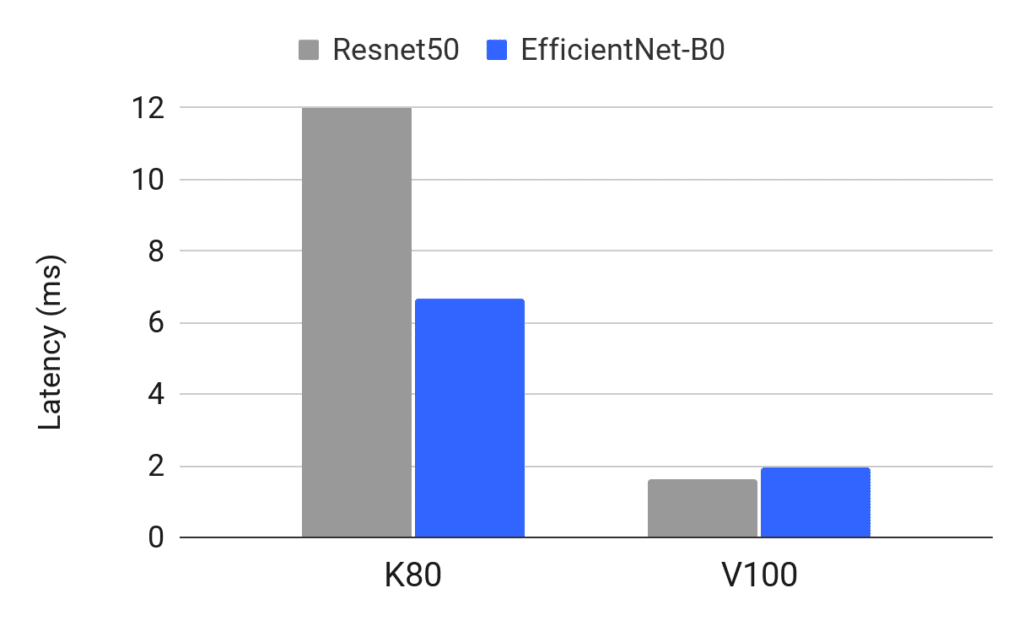
In the below figure, you can see a comparison of the latency performance of ResNet50 and EfficientNet-B0 on NVIDIA’s K80 and V100 GPUs. As you can see, when measured on the K80 GPU, EfficienNet-B0 is much faster than ResNet50 but this performance gap almost disappears when measured on V100. Being aware of the vast interplay between model architecture, data and compute is key for successful development and deployment of deep learning models.
When it comes to improving models’ accuracy and taking them to production, it isn’t always clear which of these three components takes precedence. One of the great debates currently circulating within the AI community is over data versus models, specifically whether to approach the development of robust deep learning models from a data-centric approach or a model-centric approach. Let’s start by better understanding these two approaches.
What is the Data-centric Approach?
AI developers are always seeking to improve the accuracy and performance of their models. Data scientists and proponents of the data-centric movement argue that in order to do this you must change or improve your data. Rather than focusing on altering your model, you should focus on tweaking and improving your data and leverage various pre/post processing techniques. Proponents of this approach argue that by treating data as a priority, a data-centric approach results in better performance than a model-centric approach. This approach is not only data-driven but is also centered around the accumulation and improvement of high quality data.
The data-centric approach views AI advancement as based on generating as much quality data as possible, tailored to use cases. By improving both the quality and quantity of data, better model accuracy will be achieved as a result. Therefore, focusing on datasets needs to be prioritized over models.
What is Model-centric Approach?
The model-centric approach to AI prioritizes changing and improving the model (or “code”) to improve performance, rather than the data that it is based upon.
This approach prioritizes improving the functionality of the model, by selecting the best architecture, training processes and techniques. It’s about designing models that can better capture data properties. For example, identifying small objects in object detection, detailing the frame rates in classification or in semantic segmentation, or learning the probability of words in NLP tasks, and so on.
Below is a great example that illustrates what can be achieved with modeling techniques (including model architecture selection, training techniques and hyperparameter selection).
Figure 3 below illustrates the past 10 years since AlexNet. You can see that for the exact same ImageNet dataset and the same training and validation sets, we saw a significant boost in model accuracy. In 2011, starting with AlexNet accuracy was around 60% Top-1 and over the years progressed to reach the state-of-the-art Top-1 Accuracy metrics that we see today all without making any changes to the data(!!).
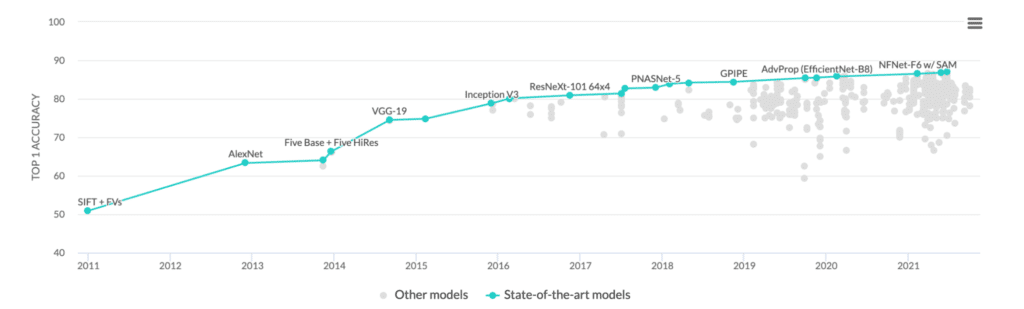
The journey from AlexNet to present SOTA models was long, nevertheless, it illustrates the following simple truth: in a probabilistic way, the model that you are currently training is probably not the optimal one for the task that you are trying to solve, (not to mention the hardware you want to use in deployment) and by iterating on the model, you are very likely to improve the accuracy. So where do you start? by identifying architectural components that can help you achieve higher accuracy.
Key Architectural Components that Lead to Better Accuracy
Residual connections, width vs depth or scaling rules, receptive field, and input resolution are some of the components of a model’s architecture that can impact and lead to improved accuracy. If we cover the history of models on Figure 3, one of the first leaps forward was the evolution from VGG to ResNet around 2014, when residual connections were introduced.
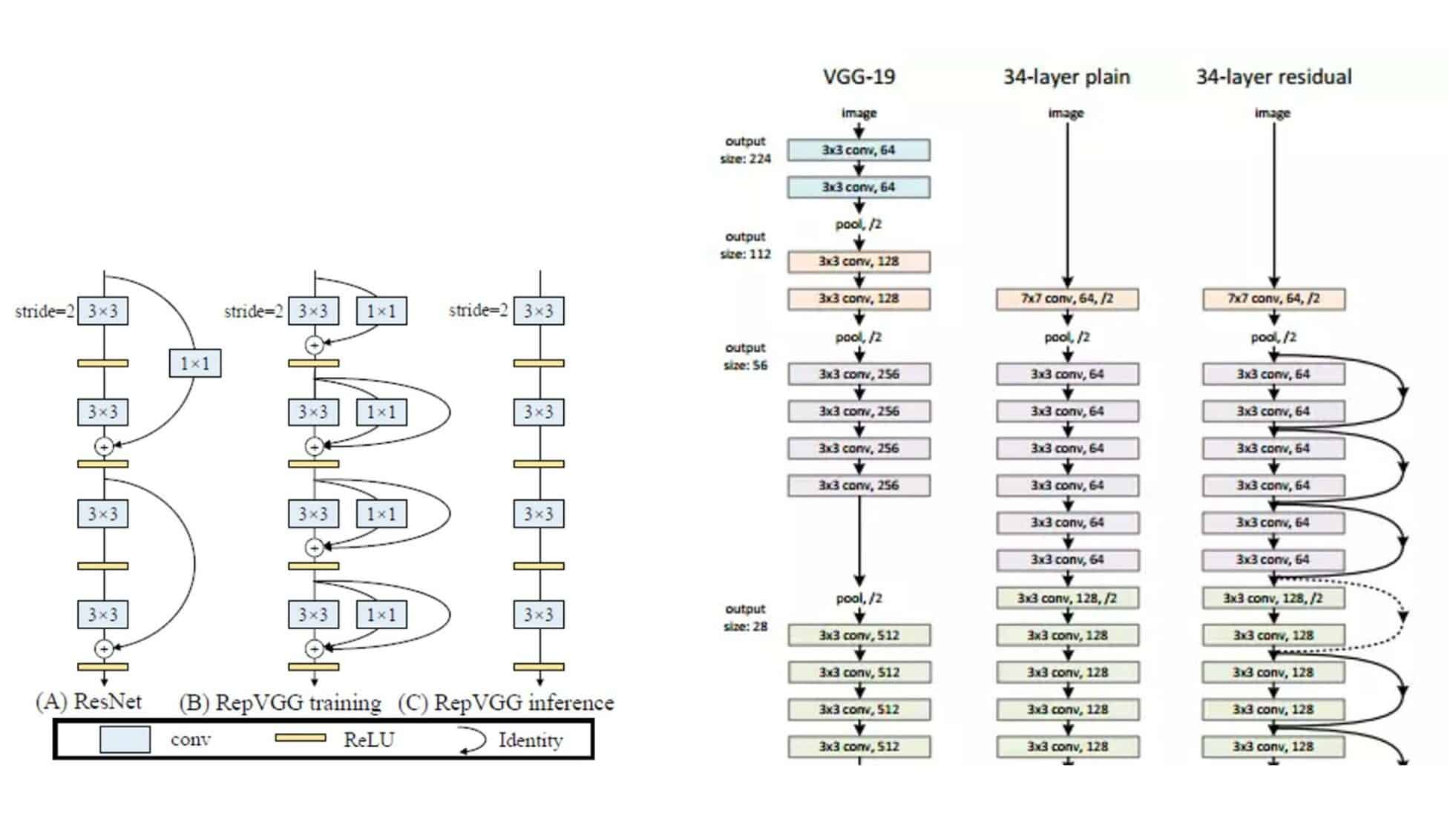
Many think that the residual connections are important for the prediction side of the model because they are passing information and skipping those layers, but actually, it seems that those residual layers or skip connections are more important for the training phrase propagating back the gradients. We can see in RepVGG, which is a quite recent architecture, that with some reparameterization tricks, the residual connections at inference time can be removed. Removing these connections improves speed due to fewer calls to memory to save tensors.
Other components to consider are the receptive field, the types of the blocks, and input resolution for the model. There is also a need to find some balance between the data set and the architecture capacity or size to avoid overfitting and underfitting.
All of these components and many others can significantly impact the accuracy of the models.
Data-centric vs Model-centric
Now that we’ve gone over both data-centric and model-centric approaches, the question is which approach is better. Well, the answer is that both are important and should be taken into consideration. Historically, the model-centric approach has been the most dominant. This may be partly due to its prominence in academic research, which the AI sector is deeply influenced by. However, this paradigm has begun to shift due to the advent of the data-centric movement, proponents of which argue that developers should focus more of their efforts on gathering and improving the quality of the data rather than working on the models. Andrew Ng, the founder and CEO of DeepLearning.AI and Landing AI is one of the movement’s most ardent advocates, arguing that the disproportionate focus on models has resulted in the significance of data being overlooked.
It is true that data has been disregarded and underused historically, and that should change. High quality data is of the utmost importance to achieving superior performance and it’s a good thing that this is being highlighted. However, to say that the impact of the model is negligible and can be ignored is not correct either.
It should be a given that every model be based upon the best quality data. But what do you do if your datasets are not the problem? If the quantity and quality of your data is a fixed variable?
Well, in some cases, the dataset is simply not the issue – it is the model architecture that needs to be improved upon. In such a case, the model architecture itself has a huge impact on model accuracy and performance. The model selection and evaluation requires more attention in order to deliver the best results.
Deci’s Approach to Model Development
At Deci, we incorporated many years of both industry as well as academic research experience into developing a proprietary, hardware-aware Neural Architecture Search engine, called AutoNAC. Using the AutoNAC engine, teams can quickly and easily build custom model architectures that are tailored for their specific use cases and therefore, deliver outstanding performance in minimum time. Teams using Deci typically gain anywhere between 3-10x increase in inference performance compared to SOTA models (depending on various factors) while maintaining and in some cases improving the original accuracy.
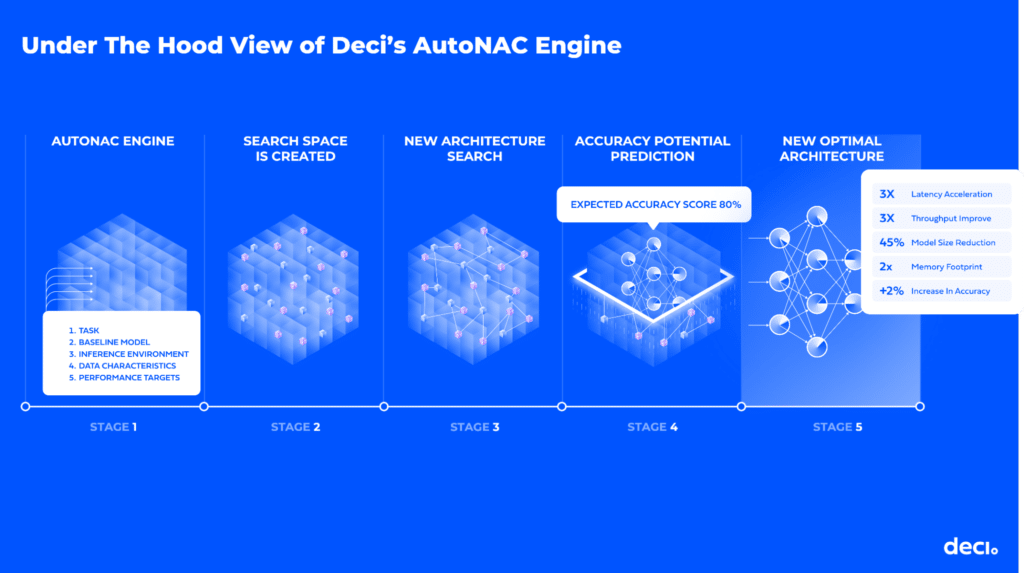
How AutoNAC Works
To begin the process, Deci’s AutoNAC engine requires three inputs:
- The task (e.g. computer vision object detection, semantic segmentation, etc.)
- The inference environment.
- The data OR the data characteristics (e.g. number of objects size of objects, etc.)
- A baseline model
Using this input the AutoNAC engine creates a search space that consists of millions of candidate architectures. The candidate models may have different shapes, different structures, and different connectivity. As a next step, AutoNAC performs a multi-objectives search within this huge search space to find an architecture that delivers the highest accuracy for the target latency/ throughput, model size and inference hardware. The output is a fast and efficient model architecture ready for training.
How can Deci’s AutoNAC Yield an Accurate Neural Architecture Without Access to the Data?
First, it is important to state that in cases where the customer’s data can be used as an input for the AutoNAC engine then AutoNAC applies a data-dependent prediction method, which obtains the best results. The integration of hardware awareness and data awareness into Deci’s AutoNAC engine turns it into a powerful tool that is used by AI teams to quickly achieve the best results possible and build models that outperform well known state of the art models.
However, in many cases and for various reasons, teams are not able to use the data as an input to the AutoNAC process. In such cases, the data characteristics can be used instead.
A key ingredient in Deci’s secret sauce is an AutoNAC component called the accuracy potential predictor. This sophisticated predictor analyzes the architecture’s ability to reach a high accuracy by examining the network’s topology and building blocks and determines the expected performance without having to train it. Using this unique data-less approach, it can estimate what will be the accuracy or what is the power of a given neural architecture when it meets the data.
There are some similarities between Deci’s predictor and an existing predictor called the synaptic flow [1], in which the importance of a neural parameter is defined as its contribution to reducing the final loss. Specifically, if W=(w1,…,wn) are the network parameters, the importance of parameter wj is defined as, L(W)-L(W | wj=0), whose first order Taylor approximation is d Ld wjwj. The overall score of a given architecture is then obtained by summing up the importance of all its parameters. While there are similarities to the synaptic flow, Deci’s proprietary predictor is more sophisticated and substantially more powerful. Recently various related techniques have been published and showed promising results in the context of training-free, or zero-shot NAS [2,3,4,5].
As previously mentioned, when AutoNAC can access the user’s data, it can apply a more powerful data-dependent prediction method, which can obtain even better results.
To summarize, there are various ways to improve a model’s accuracy. Adding more quality data can definitely help, but at a certain point will have diminishing returns. In addition, adding more data is not always possible. On the other hand, smart model design using Neural Architecture Search is the most impactful and advanced method today to deliver high accuracy and inference performance, even when dealing with small data sets, as proven by the SOTA models generated with such tools.
Contact us to learn more about the Deci platform and how it can empower your teams to build better models faster.









