

Many existing techniques can help improve the performance of deep learning models. For computer vision models alone, there are many tips and tricks in various papers, including object detection, image classification, image segmentation, and other tasks.
Deci’s previous blog, 5 Must-Have Tricks When Training Neural Networks, discussed various training techniques, including knowledge distillation, EMA, and weight averaging. We recommend these techniques and utilize them ourselves to improve model performance.
In this blog, you’ll learn how to achieve better model performance and accuracy by applying these training techniques. We will demonstrate how these techniques allowed us to achieve 81.9% Top 1 Accuracy on ImageNet with ResNet50, outperforming pre-existing SOTA results.
We also provide a notebook showing you how to write a recipe code using these techniques, and how to use knowledge distillation in SuperGradients, our open-source training package, when writing your training recipe.
Now let’s discuss how we achieved 81.9% Top 1 Accuracy on ImageNet with ResNet50 using our training techniques.
Previous Approaches to ResNet50
Choosing the best neural network training recipe for deep learning models is challenging. A paper called “Resnet Strikes Back” demonstrated the significance of the right training for training ResNet50 on ImageNet. They boosted ResNet50 to a top-1 accuracy of 80.4% on ImageNet-1K. The original ResNet50 recipe reached 75.8% accuracy, so this improved.
Their training procedures are detailed below under procedures A1, A2 and A3.
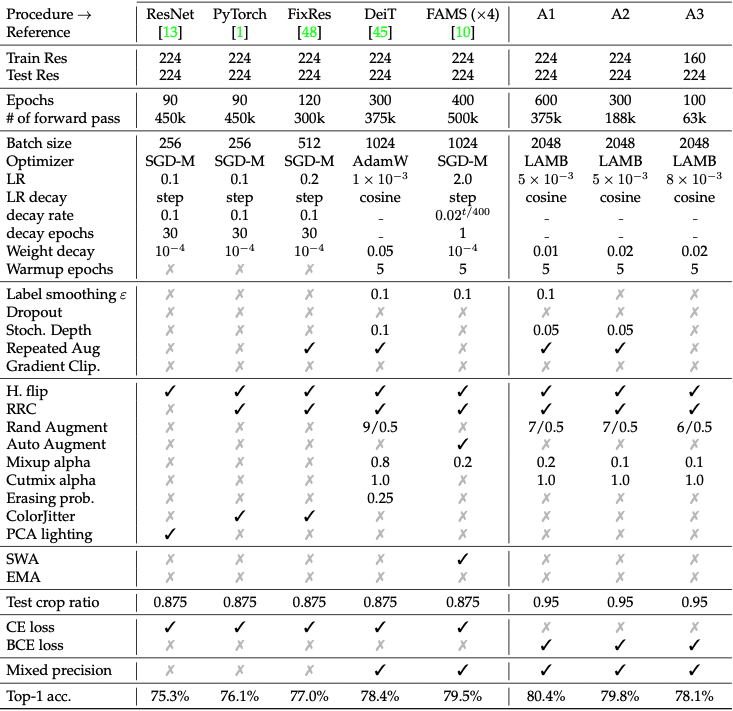
Such a significant boost in performance from simply changing the training recipe is pretty amazing. By tweaking and applying our own techniques, we achieved even better results – 81.9% Top 1 Accuracy on ImageNet with ResNet50.
Let’s look deeper at our recipe and what we did to achieve these results.
Improving Upon ResNet Strikes Back
We wanted to see if we could outperform ResNet Strikes Back’s SOTA results by utilizing some of our training techniques. Our training recipe includes techniques from the A1 procedure above, but with some key differences:
- Knowledge Distillation. A training technique that trains small machine learning models to be as accurate as large models by transferring knowledge. Read more about knowledge distillation here.
- We apply EMA. A method that increases the stability of a model’s convergence and helps it reach a better overall solution by preventing convergence to local minima.
- Weight averaging. Weight averaging is a post-training method that takes the best model weights across the training and averages them into a single model.
- We don’t apply stochastic depth. Stochastic depth aims to shrink the depth of a network by randomly removing/deactivating residual blocks during training.
We utilized several essential techniques outlined in this previous blog to improve the A1 recipe.
Now let’s dive into the recipe a bit more in detail.
Our Recipe’s Data Pipeline
- Standard Augmentations – Our recipe’s data pipeline begins with standard random resized crops and horizontal flips.
- RandAugment – We then apply RandAugment, which is an automated augmentation policy. It works by maintaining a list of predefined transforms, and from that list, we randomly select 2 transforms and apply them sequentially with varying magnitudes.

- Cutmix and Mixup – In the last stage of our data pipeline, we leverage Cutmix and Mixup for regularization. For each image, we either blend the image with a different image in the batch or cut out an area and replace it with a corresponding area in a different image in the batch.
The alpha parameters control the blending coefficients in the case of Mixup and the area percentage to replace in the case of Cutmix.

We also use very large mini-batches. We used 8 GPUs, with a batch size of 192 on each GPU, yielding an effective batch size of 1536.
We apply batch augmentation, which enables the benefits of large-batch training while keeping the number of input examples constant and minimizing the number of hyperparameters.

We repeat each input 3 times so that in distributed training, three processes have a different augmented version of an image in each forward pass.
Our Recipe’s Training Hyperparameters
Our training recipe includes a unique set of meticulously fine-tuned training hyperparameters.
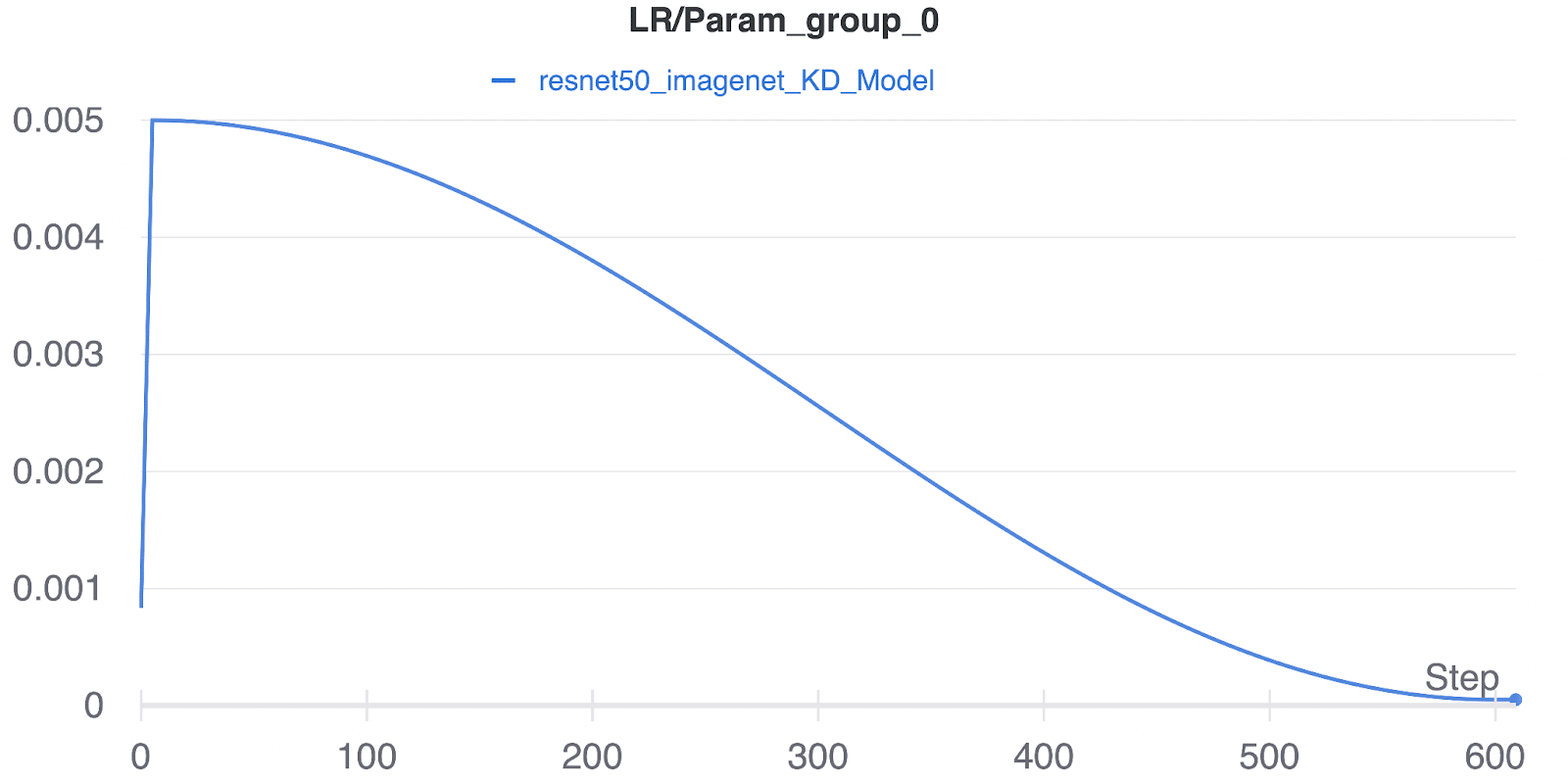
We begin by training our model for 610 epochs, which consist of 5 warm-up epochs and 10 cool-down epochs. During the warm-up phase, the learning rate increases linearly until it reaches the end of the 5th epoch. Following this, we employ a cosine scheduling policy, which remains in effect until we reach the 600th epoch.
Once the cosine scheduling policy is complete, we train the model for an additional 10 epochs at the minimum achieved learning rate.
This extended training period allows our model to extract the maximum performance possible. To further enhance our training process, we utilize the LAMB optimizer, known for its exceptional performance when dealing with large batch training.
Combining these carefully chosen hyperparameters, we’ve reached the remarkable Top 1 Accuracy of 81.9% on ImageNet with ResNet50.
We use a weighted sum for the loss function between the cross-entropy loss applied on image labels and the KL divergence loss applied on the teacher’s softmax response. We use the pretrained BEIT Base for the teacher network, a powerful image transformer.
It was initially pretrained on ImageNet-21K and then fine tuned to reach 85% Top-1 accuracy on a regular ImageNet.
Main Ingredients and Steps of Our Training Recipe
The training process we utilized comprises two key components: the data pipeline and the training hyperparameters.
Data Pipeline
The data pipeline plays a crucial role in our success.
We start with a batch size of 192*8, which equals 1536 images per batch. To augment the dataset, we use repeated augmentations with a factor of 3. Using a random interpolation method, the random resized crop and interpolation step scales images from 256 pixels to 224 pixels. To further enhance the dataset, we apply horizontal flips and RandAugment with m=7 and mstd=0.5.
Finally, we use Cutmix and Mixup techniques to introduce additional variety to the dataset.
Training Hyperparameters
Our carefully chosen training hyperparameters consist of 610 epochs, with 5 learning rate (lr) warm-up and 10 lr cool-down epochs.
The initial learning rate is set to 5e-3 and employs a cosine learning rate schedule throughout training. Other training strategies include Exponential Moving Average (EMA) and Model Weight Averaging. The optimizer of choice is the LAMB optimizer, well-known for its excellent performance in large-batch training. The loss function combines 0.8KLDivergenceLoss and 0.2CrossEntropy, which helps optimize our model’s performance.
Combining these data pipeline strategies and training hyperparameters, we achieved a remarkable Top 1 Accuracy of 81.9% on ImageNet with ResNet50.
Conclusion
In conclusion, we have reviewed how we outperformed SOTA results and achieved 81.9% Top-1 Accuracy on ImageNet with ResNet50 by applying training techniques. With our recipe, you can achieve SOTA results in 91 training hours on 8 NVIDIA A5000 GPUs.
We went over our process and training recipe. We have also provided a notebook showing you how to write a recipe code using these techniques and how we achieved Top-1 accuracy with ResNet50. You can access our training recipe, including the logs, tensorboards, complex commands, and configurations, by following this link.
You can get started training this and other recipes with SuperGradients, our open-source training package. SuperGradients includes knowledge distillation models for writing your own training recipe and seamlessly integrates the training techniques we discussed.









