No matter where you turn, you can’t miss the reports on the positive growth trends related to the adoption of AI, machine learning, and deep learning practices. According to the McKinsey Analytics global survey on the ‘state of AI in 2020,’ respondents who adopted AI for their business use-cases reported an increase in revenue attributed to AI implementation in production. That said, releasing AI models is still challenging; it comes with many obstacles that must be overcome to reach inference and production. According to various industry analysts, 80% of these projects will never reach delivery. They get stuck at some stage before deployment, never making their true impact.
One of the main obstacles impeding the effective utilization of AI models, is their deployment on compute resources, within their target environments. In many cases, placing a model for inference on a general-purpose server results in inefficient inference performance. Furthermore, such sub-optimal inference performance may occur even while placing on an inference dedicated server but with outdated drivers or software packages that don’t fully match the underlying hardware. In today’s versatile environments with so many types of hardware, frameworks, and model types, DevOps and data scientists are constantly struggling to retune and optimize the relevant settings. This means wasted time and unnecessary expenses. What’s more, being able to deploy or upgrade models everywhere and having to scale up and down inference resources, all with zero-downtime, has become another major challenge preventing the successful serving of models in production.
A clear way of tackling this hurdle is to adopt new infrastructure concepts when inferring AI models in production. Over the past decade, container technology has been transforming the face of cloud-based IT development and operations. Containers allow businesses to maximize an application’s utility and efficacy by isolating the application from its surroundings. This isolation allows developers and operators to wrap or ‘cocoon’ the application with the optimal environment and settings, in a systematic manner, including the most suitable programs, configurations, and dependencies.
Similar to general application containers, using containers to perform deep learning inference allows faster deployment and portability of the AI-models, improved developer productivity, the agility to scale on-demand, and more efficient utilization of compute resources.
RTiC – Deci’s Runtime Inference Container
Deci’s RTiC is a containerized deep-learning runtime engine that lets you place your models in an isolated context within a running microservice environment. Using RTiC you can maximize GPU/CPU utilization and boost your model’s inference performance accordingly.
RTiC, as a standard container, has its own file system plus a dedicated inference server software and packages, all bundled together within the container. RTiC maximizes the utilization of the underlying hardware while enabling the inference of multiple models on the same hardware. You get to leverage the best-of-breed open source optimization compilers, such as TensorRT and OpenVino. RTiC also supports the “hot-swap” of models within the container, with zero downtime when it comes to real-time upgrading or switching of models.
With RTiC, you can use standard container orchestration applications such as Kubernetes to deploy, manage, and scale microservices up or down. Similar to other microservice-based containers that communicate with each other via APIs, RTiC exposes well-defined APIs to its “outside” world. RTiC’s API enables communication with the container for inference requests, sharing data results, and for service functions such as measuring, replacing models, and deploying new models.
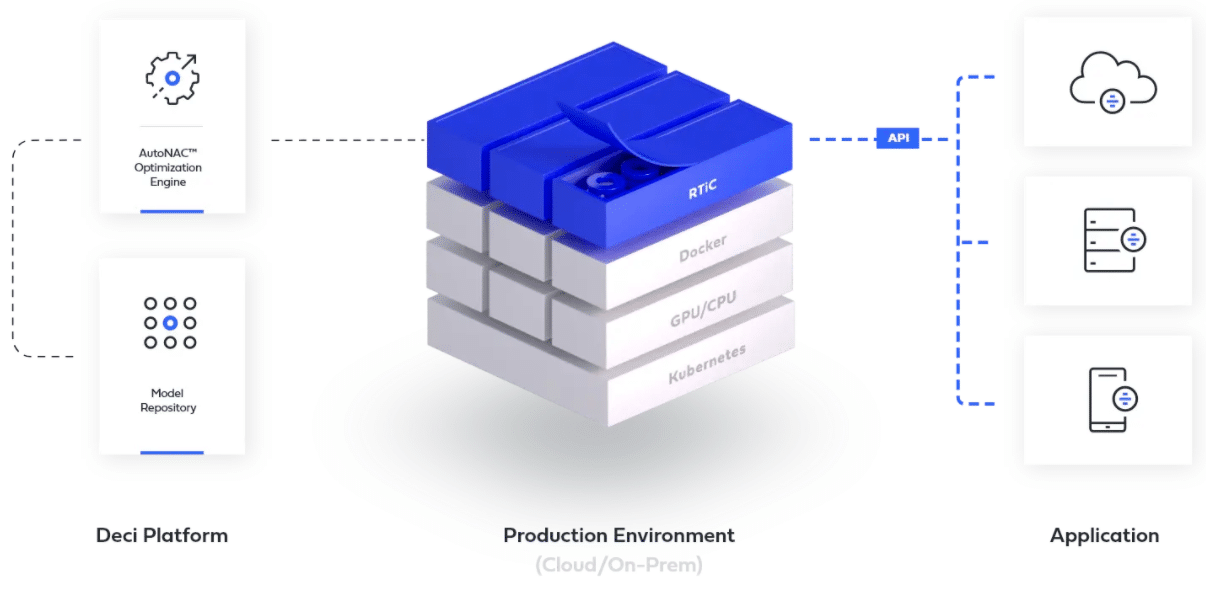
Connecting RTiC to Deci’s Deep Learning Platform
Deci’s deep learning platform automatically gears up your trained neural networks to become top-performing production-grade solutions on any hardware, at scale. Data scientists can use Deci’s AutoNAC optimization engine to automatically optimize their models’ inference throughput/latency. Everything is done in a hardware-aware manner, without compromising accuracy. What’s more, as part of this platform, data scientists can get actionable benchmarking insights for their models’ fitness across different hardware hosts and cloud providers.
When it comes to serving these models in production, RTiC elegantly and efficiently takes you to the next step. RTiC will package these models into a standardized inference server, ready for scaled deployment in any container-based environment. Deploying your models through RTiC gives your data scientists the flexibility to work on any framework while providing DevOps with operational-transparency to the actual contents of the container.
Main RTiC Product Advantages
- Models packaged into RTiC benefit from a highly efficient inference server that works on most common cloud environments, including GCP, AWS, and Azure.
- RTiC can be orchestrated using standard tools including Kubernetes, EKS, AKS, and GKS.
- Models placed into RTiC can be developed with leading DL frameworks, including TensorFlow, PyTorch, ONNX, and Keras. These frameworks are automatically maintained (installed and updated) within RTiC, ensuring version compatibility to their latest builds.
- RTiC optimizes performance and resource utilization by leveraging best-of-breed graph compilers such as TensorRT and OpenVino, integrated into the container for easy use.
- Standard API communication to/ from the models uses methods such as HTTP, gRPC, or IPC. Defined API messages include functions for inference requests, loading models–including production hot swapping–and measuring or monitoring model performance in production.

Summary
Deci’s RTiC is a dedicated deep learning inference container that enables data scientists and DevOps teams to benefit from all the advantages of a standalone runtime engine within a microservice environment. Inserting your models into RTiC will result in faster deployment and portability of your AI-models, better developer productivity, enhanced performance, agility to scale on-demand, and efficient utilization of compute resources. For more information about Deci RTiC, please refer to RTiC Solution Overview.