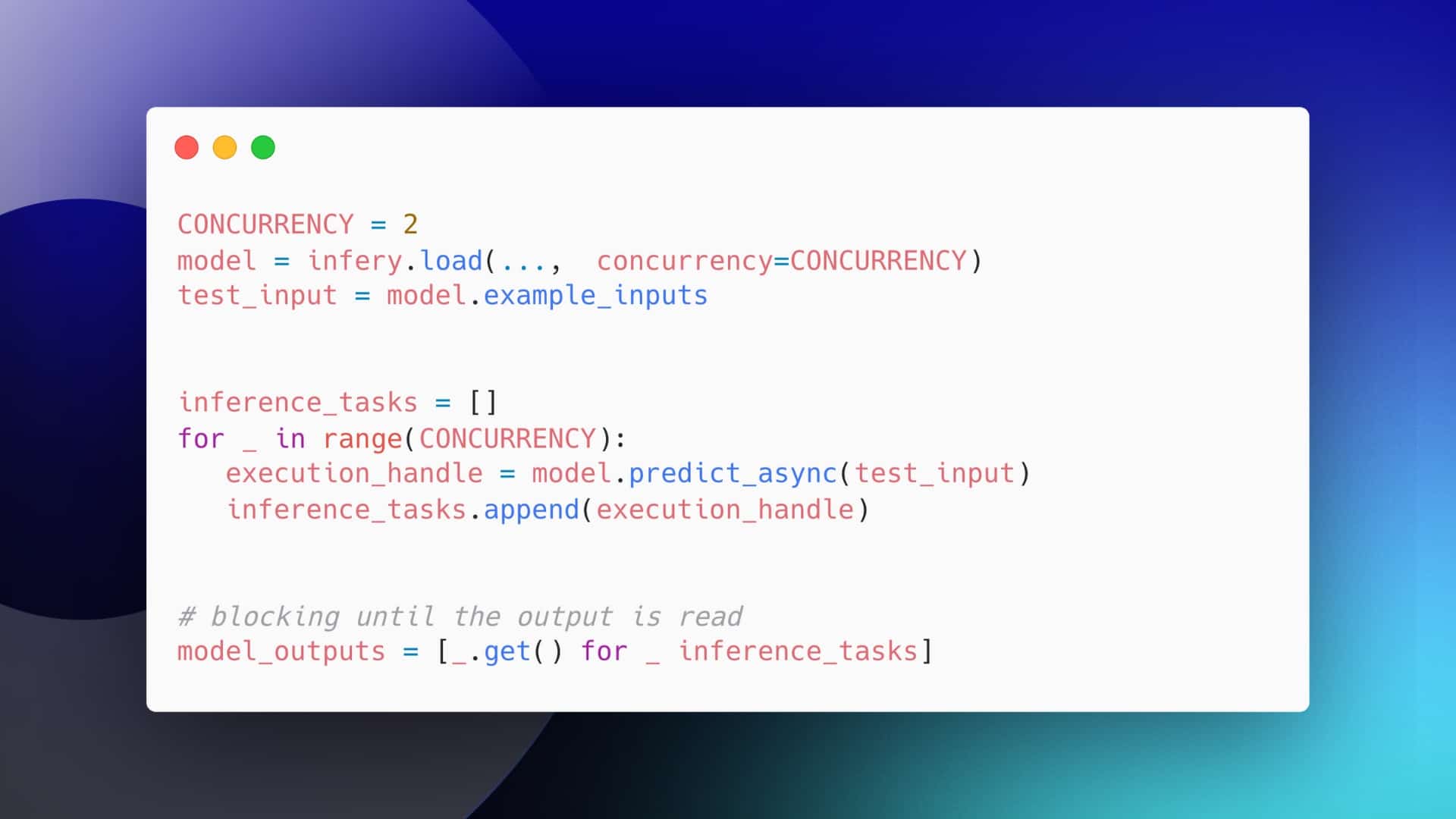
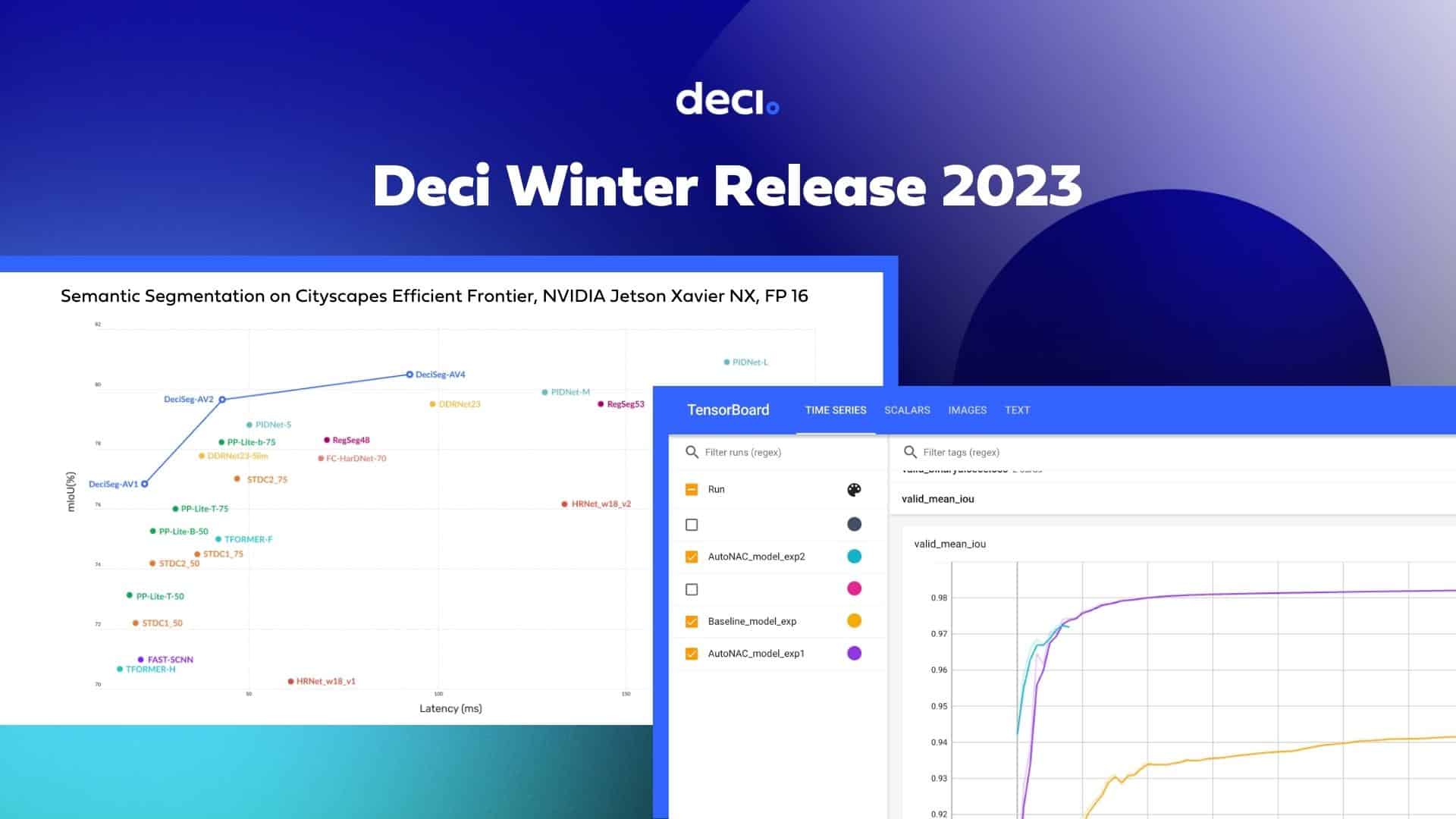
Deep learning inference acceleration is the end-to-end process of accelerating the inference of neural models while preserving the baseline accuracy. It is fully aware of the desired target inference hardware including GPU, CPU, or any ASIC accelerator. Powered by AutoNAC, it helps AI teams to squeeze the maximum utilization out of any hardware, speed up the trained model’s runtime, and reduce its memory size.