Now, we’re moving into ‘edge AI’ where what’s taking place on ‘the edge’ is no longer just computing. In the next few years to come, AI will increasingly be brought to the source of data, unlocking new applications that require optimal speed and intelligence. By 2025, according to Seagate, “44% of data created in the core and edge will be driven by analytics, artificial intelligence, and deep learning, and by an increasing number of IoT devices feeding data to the enterprise edge.”
So, what is edge AI, what are the opportunities and challenges in running AI on edge devices, and how can developers and enterprises use it to deploy deep learning-based solutions on the edge?

Like AI, IoT, and cloud, ‘edge’ is a term that’s being thrown around a lot these days. But what exactly does it mean? Gartner defines edge as “the physical location where things and people connect with the networked, digital world.”
Therefore, to expand the term a bit, edge computing means computing that’s done at or near the source of the data. Instead of relying on ‘the cloud’ at one of several data centers, edge computing moves the computing and storage resources to local places where data is produced or consumed. This removes reliance on internet connection and significantly reduces latency and bandwidth usage.
Running deep learning (DL) models requires heavy computing power which limits the majority of processes to the cloud. By bringing AI computing to edge devices, ‘edge AI’ enables you to process deep learning algorithms locally, either on the device that people use or on the server near it.
Also called ‘on-device AI’, edge AI is a distributed computing paradigm that doesn’t require data to be sent over the network for it to be processed on the cloud. The algorithms can utilize the data generated by the device as well as its computing power, enabling it to handle computations, run inference, and make independent decisions in near real-time. This is crucial because more and more edge AI use cases, such as autonomous cars and industrial robots, demand high-speed processing with minimal latency while maintaining high accuracy.
A related field to edge AI is Tiny Machine Learning, also known as TinyML, which facilitates machine learning inference on smaller, performance and power-constrained devices and embedded systems. Successful deployment in this field can broaden the reach of ML and unlock new applications just like edge AI.

01
Centralized Cloud Computing
In the initial stage, data generated by devices was predominantly sent to and processed in centralized data centers or cloud infrastructures. This approach, while enabling significant data storage and processing capabilities, faced challenges such as high latency and bandwidth constraints due to the reliance on remote servers.
02
Emergence of Edge Processing
As technology advanced, there was a shift towards processing data locally on devices or nearby edge servers. This development was driven by the need to reduce latency, conserve bandwidth, and enhance data privacy. Edge processing enabled real-time or near-real-time data analysis and decision-making directly at the source of data generation.
03
Hybrid Edge-Cloud Integration
The current phase in the evolution of edge computing involves the integration of edge processing with cloud computing. This approach leverages the immediate, localized processing of data at the edge, combined with the powerful, expansive computational and storage capabilities of the cloud. This hybrid model offers flexibility, efficiency, and scalability, addressing a wide range of application needs while optimizing resource use.
Mobile phones and wearables that store information and do a lot of processing
Traditional computer that sits in a data center can take part in an edge architecture by providing edge-based services
Small devices such as Raspberry Pi that have local storage, processing, and networking
Drones, robots, and sensors that require near real-time computing, without having to depend on network connectivity
Edge computing with AI is a powerful combination that can bring promising applications to both consumers and enterprises. An industry report suggested that enterprises that seek optimizations and innovations enabled by edge computing and edge AI stand to gain competitiveness. With promising applications to both consumers and enterprises, what makes running on the edge ideal for deep learning?
More speed, less latency
Inferencing locally eliminates cloud communication delays. Processes like data creation and decision-making can transpire in milliseconds, making edge AI ideal for use cases that necessitate quick responses.
Data security
Computing on the cloud requires data to be transmitted and processed in a centralized location, raising risks and privacy concerns. Edge AI reduces these threats as it processes data on local devices.
Improved reliability
For critical applications such as autonomous cars and industrial robots, edge AI ensures that operations run continuously even if there are issues with the network or cloud.
Better user experience
By reducing latency, end-users can engage in real-time with activities like operating smart speakers with voice commands and using wearables to track physical activities.
More efficient use of power
Edge hardware requires less energy usage compared with sending data to the cloud. Some deep learning models and tasks can be performed with less energy on the edge hardware itself, which extends battery life.
Reduced costs
Edge AI lowers the amount of money users spend on bandwidth, cloud processing expenses, and other costs associated with transferring video, voice, and sensor data over the network.
Lower carbon footprint
Instead of consuming cloud computing resources, edge AI processes AI on devices and leverages existing and local compute power. This helps maximize existing hardware and reduce the carbon footprint of AI Inference.
In other words, as deep learning applications increasingly require faster latency without compromising accuracy and environmental impact, edge AI becomes indispensable.
Edge AI and cloud computing are not interchangeable as they possess specific strengths and applications. Edge AI is used when handling time-sensitive data, conducting processes in remote locations requiring local storage, and operating smart devices. Drawbacks include available compute power, limitations of deep learning frameworks, and the wide variety of inference hardware.
Meanwhile, cloud computing supports on-device processing remotely with greater computing power on the cloud. While cloud provides more architecture and design options, it also reduces power consumption by the hardware for high-level processing, as discussed above, this comes at the expense of latency and security.
Deep learning, in particular, requires large computing power which is why many computer vision (CV) and natural language processing (NLP) models are still primarily handled on the cloud today. A typical scenario is as follows: a mobile phone sends data, such as an image or text, over a network to the cloud. The cloud at one of several data centers does the calculations and then sends the results back to the user’s device.
With edge AI, the back-and-forth transfer and processing of data is eliminated. As more deep learning applications become time-sensitive and demand real-time performance, shifting the majority, if not all, of the computations on the edge is inevitable.
Even though edge AI has numerous benefits, it also comes with a range of challenges to overcome. Understanding the design bottlenecks, application requirements, and tight constraints like performance, flexibility, power consumption, and more can help you successfully deploy deep learning on edge devices.
Limited computing power and memory
Edge AI offers a lot of potential, but now, at least, only select deep learning tasks can run on the edge. Due to computing power constraints, most edge hardware today can only perform on-device inference with smaller models.
Restrictions in deep learning frameworks
Not all state-of-the-art (SOTA) and open-source deep learning frameworks and architectures can readily support edge hardware platforms. This requires further customization and adds another layer of complexity to edge AI applications. Developing and training a model is often done using PyTorch or TensorFlow while deploying it may use a variety of other frameworks. The performance of the model greatly depends on the framework running it. For example, an efficient model in PyTorch on the training server may be inefficient and slow when running with TFLite on a mobile phone, and vice versa. The framework modifies the model by using sophisticated techniques. For example, a Batch Normalization (BN) layer can be merged with the prior convolution, making the BN cost zero in terms of hardware utilization, or two consecutive linear layers can be combined during deployment.
Increasing variety of hardware platforms
The hardware market for deep learning inference, including GPUs, CPUs, FPGA, and custom AI chips, is rapidly developing. Different vendors are releasing new platforms with new features all the time. Meanwhile, it takes months to adapt existing software, frameworks, and libraries to support the new hardware causing compatibility issues to often arise.
Scalability of deploying models to specific hardware and locations
Beyond getting models to run successfully in production, another issue is scalability and specialization. Often, you must customize models to fit the use case, hardware, and location requirements. This can create friction which limits the ability to run many models on many edge devices.
Maximizing the use of models and inference hardware
Beyond getting models to run successfully in production, another issue is scalability and specialization. Often, you must customize models to fit the use case, hardware, and location requirements. This can create friction which limits the ability to run many models on many edge devices.
Choosing the kind of edge device the model is going to run inference on includes careful consideration of its capacity and features. Hardware for deep learning usually includes CPUs, GPUs, ASICs, and FPGAs. A popular choice for edge deployment is NVIDIA Jetson hardware. Usually, there are implementation guidelines that maximize the utilization of hardware resources that consider both model and hardware parameters.
In addition, unlike the comfortable, climate-controlled environment in data centers, the edge device may be exposed to extreme temperatures, vibrations, altitude, or humidity. It must then be able to operate within power and thermal constraints, as well as meet size and weight requirements. As an interface to the real world, the edge device also must support common interface technologies and peripherals such as ethernet, USB, displays, and more. Another limitation when it comes to design and hardware is regulatory requirements.
In a typical AI project, the process usually begins by training and fine-tuning a model for a specific task and dataset. This stage considers the architectural design of the model, which includes the deep learning frameworks and libraries that are suitable for edge deployment. The pipeline is also established at this point to document workflows for how to work with data, build models, optimize model parameters, and store trained models.
01
Consider everything that affects runtime performance
There are different components that play a role in inference computation including the hardware, graph compilers, compression techniques, and neural architecture search. These computation elements can be called the inference acceleration stack. Together, they impact the model selection process as well as the maximum optimization that the deep learning model can get.
02
Analyze the accuracy and latency of all models based on the hardware
With on-device deep learning, there is always a trade-off between accuracy, inference speed, or model size. So, it’s important to benchmark the model when choosing the right architecture and then customize it according to the specific dataset, inference hardware, and performance targets.
03
Get the optimal performance
It’s not unusual for neural architectures to be very large and over-parameterized. But if the model is being deployed on the edge in which real-world use cases typically require fast inference time, it is crucial to optimize it for speed and performance. To select the best model, you can run a neural architecture search (NAS) algorithm for each production environment for every task, then select and optimize for your exact use case.


Another key factor to emphasize when planning to run AI on edge devices is the runtime performance. Is the model selected capable of providing the throughput, latency, and memory footprint that the use case requires to function efficiently and reliably even in dynamic environments? The behavior during inference is different from the behavior in training. So it’s helpful to consider runtime performance during model selection as discussed.
In any AI project, the cost is always an important consideration. Taking into account factors such as processing power, memory, and storage when planning can help determine the cost limit, which then contributes to the successful deployment of deep learning to edge devices. Enabling high-performance and cost-effective edge AI will yield the lowest possible bill-of-materials cost. It’s also good practice to provide scope for scalability as there may be a need for performance increases in the future. Model, device, and software updates are increasingly inevitable as new data and hardware are made available.
Finally, to gauge the success of edge AI deployment, it’s important to agree on the criteria for addressing the expectations of end-users. In addition, since there are multiple stakeholders within and beyond the enterprise, another essential question to address is how to balance multiple requirements to meet business needs.Finally, to gauge the success of edge AI deployment, it’s important to agree on the criteria for addressing the expectations of end-users. In addition, since there are multiple stakeholders within and beyond the enterprise, another essential question to address is how to balance multiple requirements to meet business needs.
When it comes to edge AI applications today, the practice usually starts with algorithms being trained on the cloud, which are then pushed to edge devices for inference. In some cases, the architecture captures data from the edge and sends it back to the cloud to improve the model. The base algorithms are enhanced with new input from production, which is then deployed in the next update.

Manufacturing and industrial IoT
Advanced CV enables factories to automate quality control and deploy predictive maintenance. For example, AI-powered edge devices can monitor machinery for quality deviations or defects, respond in real-time, and even collect data for further analysis. This can improve safety and reduce costs in the long run.
Self-driving vehicles
The need for near-instantaneous response times in autonomous cars makes edge AI indispensable to the automotive industry. Processing activities on the road of everything from traffic signs and pedestrians to other vehicles is critical to deliver a smooth driving experience and most importantly, to ensure maximum safety.

Agricultural technology
Edge AI infrastructure powered by deep learning and IoT sensors can gather, analyze, and act on data that can increase agricultural efficiency, improve crop yields, and reduce food production costs. In particular, AgTech use cases include yield mapping, smart tractors, drone data analysis, and monitoring of crop fields for animal or human breaches.

Retail
With edge AI, brick-and-mortar retailers can improve the customer experience with relevant interactions based on shoppers’ present intent and context. It can also optimize shelf display and in-store ad placements. Some CV use cases in retail include expression analysis, self-checkout, and virtual mirrors and recommendation engines.
Security and monitoring
Deep learning built into cameras can analyze video streams in real-time, automating video monitoring with and without limited human intervention. Specific use cases include home security and theft identification.
A critical part of the deployment process to the edge is the use of optimization techniques such as compilation and quantization. But optimizing and getting deep learning models ready for edge deployment is only the beginning, it’s also crucial to assess and improve the inference pipeline in production.
Unlike in the research phase where there is no pipeline (only forward-pass), inference behaves and acts differently in the production environment. It’s a two-way process that involves the hardware, operating system, applications, users, and everything in between.
01
Inference server
The inference server executes your model algorithm and returns the inference output. It’s the biggest part of the pipeline, so it must meet expectations. When choosing your inference server, make sure that the inference server is easy to deploy, versatile and dynamic, and efficient.
02
Client and server communication
The client and server denote a distributed but cooperative application structure that divides tasks between the providers of resource or service (servers), and the service requesters (clients). Tensor data must be shared and transferred in both ways between the client and server to fasten communication.
03
Batch size
Batch size is the number of training examples utilized in one forward/backward-pass. Optimizing it is a low-hanging fruit when aiming to boost inference performance in production. Look at the model task, model memory consumption, and model replication to choose the best batch size for your use case.
04
Code optimization
Code is something that can be changed in the fastest way. One method to do that is to utilize asynchronous code, which fires multiple requests at a certain point, so that when you predict, you get a future object that you can use once it’s needed.
05
Serialization
Serialization translates state information of a data or object instance into a format that can be stored, transported over a network, and reconstructed later. The process affects latency because it manipulates the data, and it is a CPU blocking operation. It can be done in various ways that can reduce memory footprint.

Optimizing and deploying deep learning applications for edge devices presents a unique set of challenges, including adhering to the stringent storage, memory, and computational constraints of your specific hardware, while also ensuring real-time responsiveness and maintaining high accuracy. At Deci, we understand these challenges intimately, which is why we offer specialized foundation models alongside our innovative tools for custom model development.
Addressing the demands of edge AI, Deci introduces a suite of foundation models, meticulously crafted for diverse tasks, hardware specifications, and data types. Our models stand out for delivering unmatched inference performance across various domains, including object detection, pose estimation, image classification, and semantic segmentation. Each model is designed to excel in production environments, ensuring your applications run smoothly and efficiently.
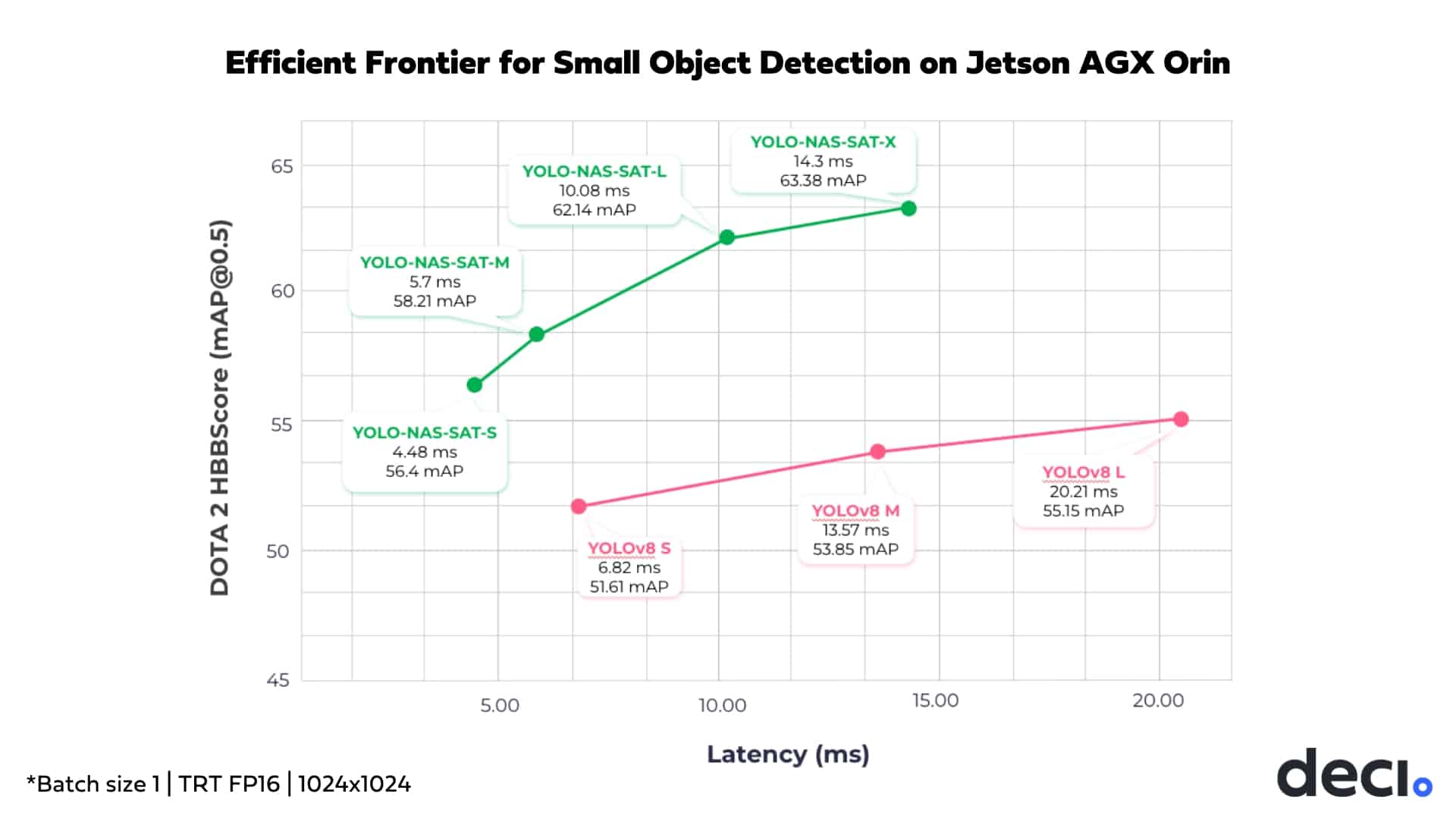
Among our foundation models, YOLO-NAS-Sat and YOLO-NAS Pose are specifically optimized for edge AI applications, targeting small object detection and pose estimation, respectively. These models, along with DeciSegs, YOLO-NAS, and DeciNets, owe their exceptional performance to their innovative design, all generated through AutoNAC (Automated Neural Architecture Construction). AutoNAC, Deci’s proprietary neural architecture search engine, excels in developing hardware-aware architectures, optimizing for factors such as target latency, throughput, and hardware and data characteristics.
If your project demands a tailored solution, AutoNAC empowers you to create custom models that deliver optimal performance for your unique use case.
To further refine your chosen model, whether a foundation model or a custom build, Deci provides SuperGradients, our open-source PyTorch training library. SuperGradients supports quantization-aware training, enabling you to enhance model efficiency without sacrificing accuracy.
To ensure your model operates seamlessly in its target environment, it requires proper compilation and quantization. Compilation prepares your model for its specific execution environment, while quantization reduces the precision of the model’s weights, minimizing its memory footprint and enhancing performance.
Along with a Deci foundation or custom model, you get Infery, Deci’s model optimization and runtime SDK. It provides you with all the tools you need to benchmark, compile, quantize, and deploy your model to any environment, including on edge devices with limited resources.
It’s clear that edge AI has promising opportunities for multiple industries, but it’s still in its infancy stage and many factors impact its success and should be considered. Armed with deep academic expertise and industry experience, Deci’s end-to-end tools for edge deployment can bring deep learning models to production—in the most cost-effective way possible. Get started now
Share

Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")