Improve latency and throughput and reduce model size by up to 10x while maintaining your models’ accuracy.


Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.

Semantic Segmentation
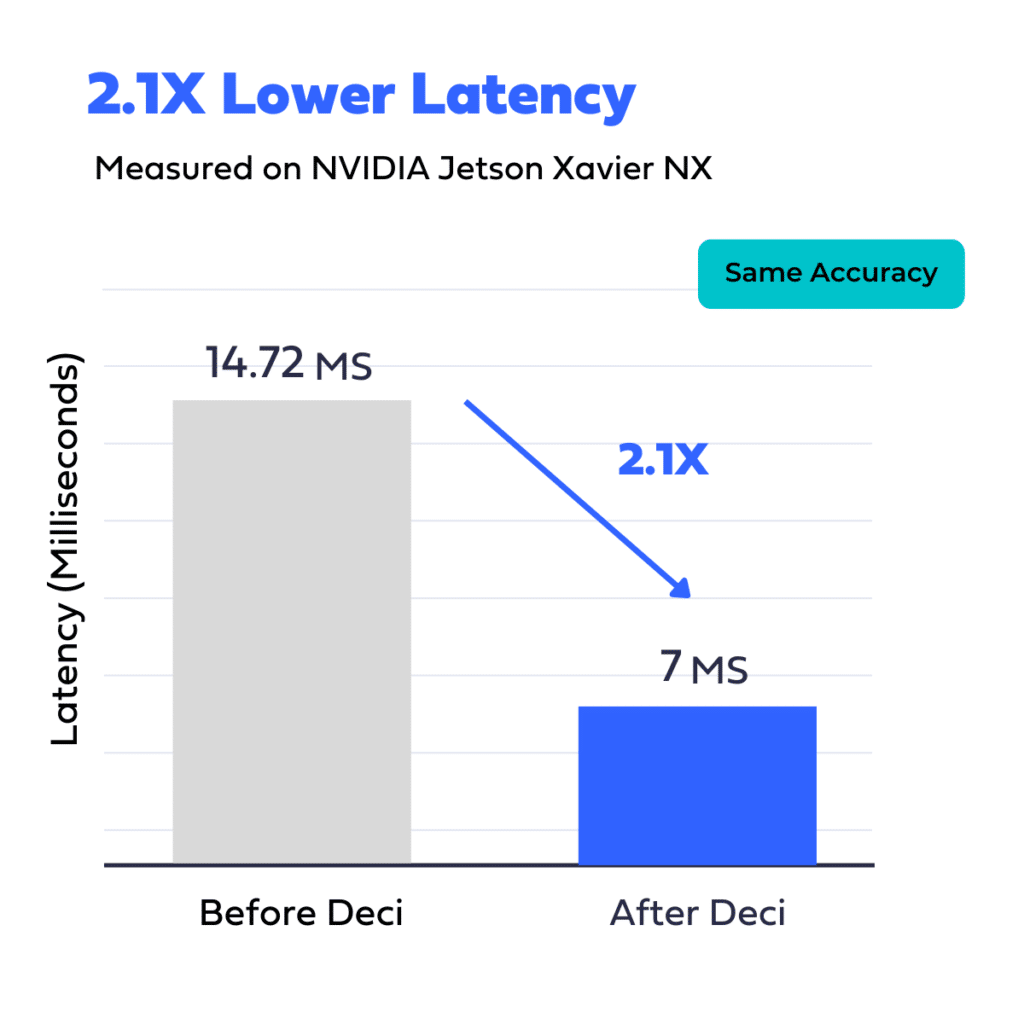
An automotive firm faced challenges hitting their throughput goals with a U-Net model on NVIDIA Jetson Xavier NX. By employing Deci’s AutoNAC engine, they developed a quicker, smaller model, cutting latency by 2.1X, shrinking the model size by 3X, and reducing memory usage by 67%, without sacrificing accuracy.
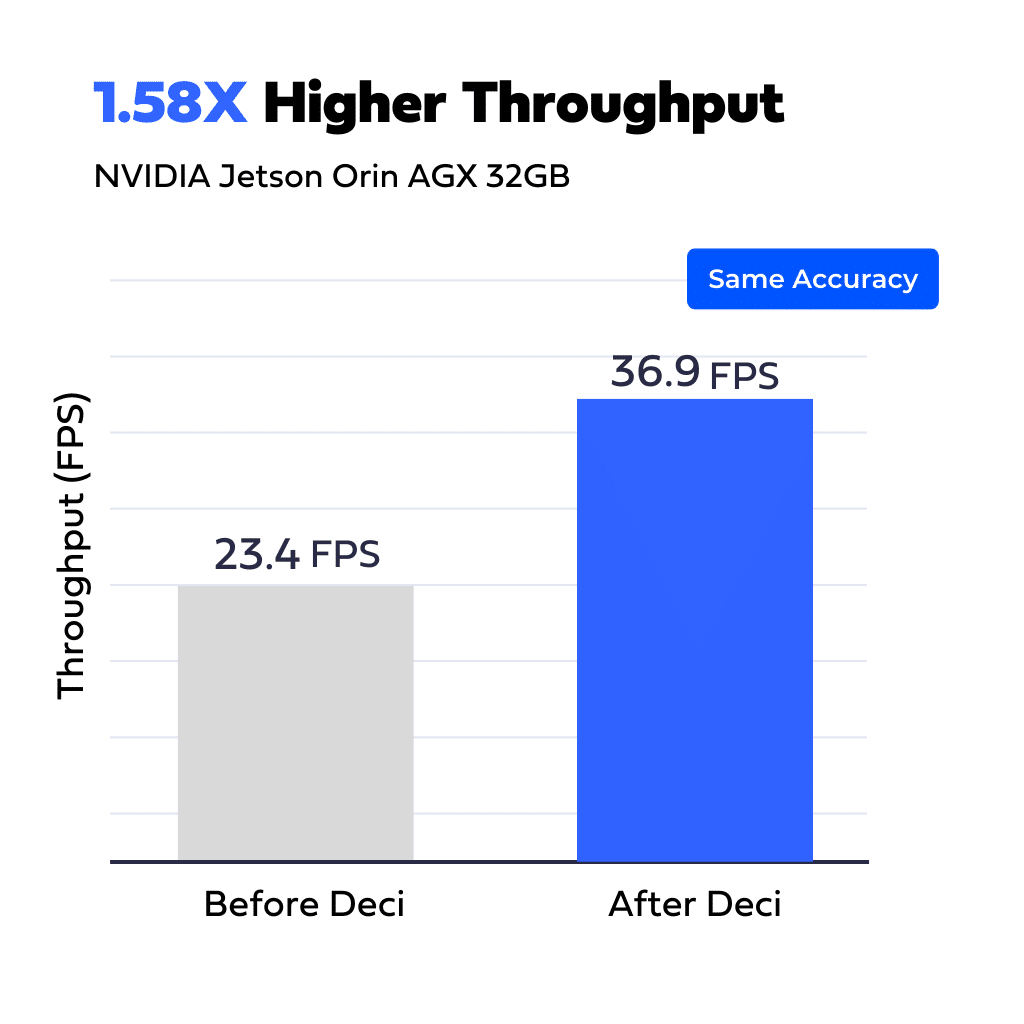
A defense company developing electro-optics solutions for space, airborne, ground, and maritime applications was looking to improve the throughput of an image-denoising model for video stream analysis to deliver real-time insights on the edge. The team was also looking for a way to free up GPU resources to support additional parallel tasks on the same edge device.
Using the Deci platform and its NAS-based engine, the team built a new architecture that delivered a 1.58x acceleration of throughput while maintaining the original model’s accuracy. The team achieved the desired performance within 10 days. Once the team trained the model, they easily compiled and quantized it to TensorRT FP16 using Deci’s platform.
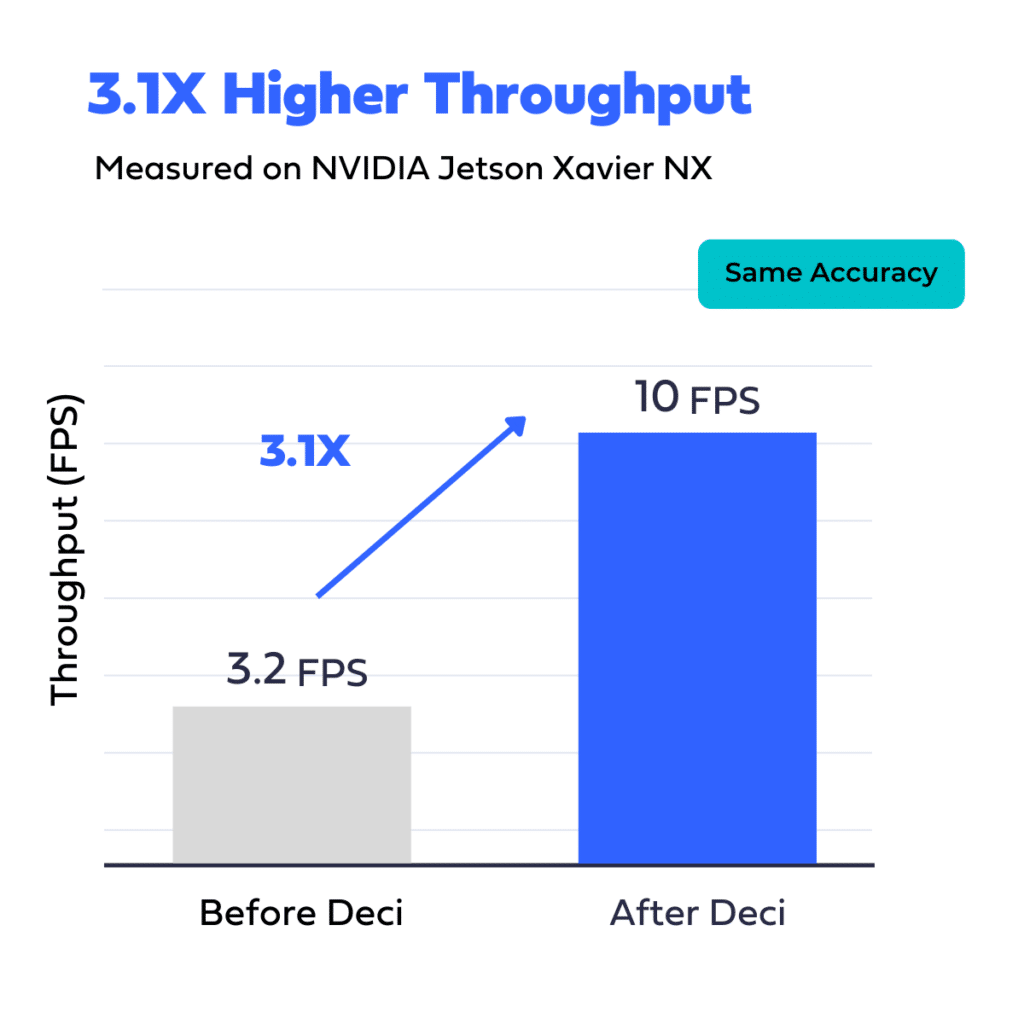
Object Detection | Object Tracking
A defense firm required processing high-res images for object detection and tracking on an NVIDIA Jetson Xavier NX, aiming to operate at 10 Watt mode with a 10 FPS throughput. Using Deci the company was able to increase throughput by 3.1x on their existing devices and launch the new solution.
Watch a quick walkthrough of how you can use Deci to accelerate your models’ inference performance.
Vadim Zhuk, Senior Vice President
RingCentral

Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")



