

Convolutional neural networks can provide superior solutions for many computer vision tasks such as image classification, segmentation, and detection. It is well-known that the size of the neural network model is correlated with its accuracy. As the model size increases, the accuracy increases as well. This can be seen in Table 1 showing the Top-1 accuracy in the ImageNet classification benchmark for several known models:
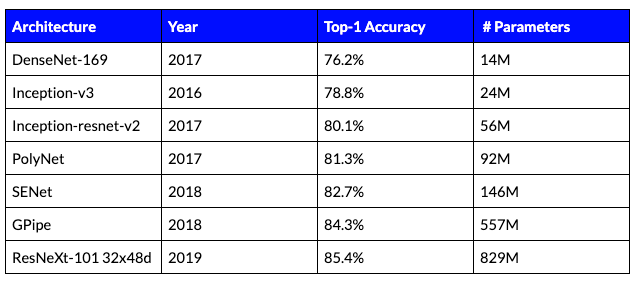
Table 1: Comparison of different classification models on ImageNet.
The well known Moore’s law states that hardware capacity doubles itself every 1.8 to 2 years. Moreover, according to Moore’s second law, the cost of a semiconductor chip fabrication plant doubles every 4 years. On the other hand, in the years between the 2012 launch of AlexNet and the 2018 introduction of Alpha-Go, the amount of computation needed by large AI systems doubled itself every 3 to 4 months! (Shown in the figure below). This outstanding number, means that the acceleration of deep networks will depend on the ability to develop light and algorithmically efficient models. Consequently, the software efficiency of deep learning will be of paramount importance for inference production systems.

Figure 1: Neural network models by year and the amount of petaflops required (for training).
Most real-world applications aim to achieve the highest accuracy with the lowest running time possible. This raises several interesting questions in the field of efficient deep learning. In this post, we address the following:
- How does the architecture of the network affect running time?
- How can we decrease the running time without degrading the model’s accuracy?
In the rest of the article, we answer these two fundamental questions.
Architecture vs. Inference Run-Time
As can be seen in Table 1, the bigger the model becomes, the more accurate it is. To find the most accurate architecture with the lowest running time, we need to understand the tradeoffs between three quantities:
- Floating point operations (FLOPs)
- Run-time
- Accuracy
The figures below suggest that while there is a clear positive correlation between the three, they are not perfectly correlated. This can be seen by the thickness of the graph, showing that for two networks with the same running time (or number of FLOPs), the accuracy can be significantly different.
Figure 2: Number of operations (in Giga-FLOPs) vs. the Top-1 accuracy on ImageNet.
Figure 3: Run-time in milliseconds of the network vs. the Top-1 accuracy on ImageNet.
To understand the gap between FLOPs and run-time, several parameters need to be accounted for, such as framework, hardware, architecture, and more. Let’s look at an example explaining why FLOPs do not have a one-to-one function for accuracy. In this example, we consider depth separable convolution (DSC), which was introduced by Howard et al. to reduce the number of parameters of deep networks. Assuming we would like to apply a convolution kernel of size K x K x D, using DSC we split the filter into 2 separate kernels: a depth-wise kernel operating on the same entries across different channels and a point-wise kernel operating on different entries in the same channel. For instance, if we take a 3 x 3 depthwise convolution on a 112 x 112 feature map with 64 input channels, we perform 3 x 3 x 64 x 112 x 112 = 7,225,344 FLOPs. Then we apply the separable component, which is a regular convolution using a kernel of 1 x 1. For this operation, we take the previous convolution output of size 112 x 112 x 64 and project it into a 128 dimension feature map; this requires 64 x 112 x 112 x 128 = 102,760,448. Adding the number of operations from the 2 convolutions comes to 109,985,792 FLOPs. In contrast, a regular 3 x 3 convolution for the same size will require 924,844,032 FLOPs, which is almost 9 times more operations! Note that the expressivity of the 2 models are different. However, using this idea, the original paper, shows comparable accuracy with much fewer network parameters. This example clearly demonstrates how comparable accuracy can be achieved with much fewer FLOPs. But, the number of operations is only one part of the story. Memory bandwidth is the second part–but we’ll save that for a different post.
Now let’s deal with our second question.
Decreasing run-time while preserving accuracy
From the model perspective, several heuristics were established to decrease the running time at inference in deep neural networks. Let’s briefly explain a few of them:
Quantization – The goal of quantization is, given a model, to map the weights into smaller sets of low-precision quantized levels. The number of levels reflects the precision and roughly, the number of bits required to store the data (by applying log on the number of levels). During the quantization process, we would like to preserve the model accuracy on one hand, yet on the other hand quantize the model into the smallest number of levels possible. The impact of quantization is twofold. First, it allows us to store the model with much fewer bits, i.e., less memory. Second, it helps us replace expensive operations with much cheaper operations. For example, replacing a double precision (64-bit) floating point operation with a half precision (16-bit) floating point operation. This, in turn, enables us to reduce the inference time of a given network. The benefits of quantization vary, depending on the data, quantization precision, hardware, etc.
Pruning – Modern architectures are usually heavily overparameterized. This, however, makes large amounts of weights redundant at inference time. Pruning refers to the process of setting these redundant weights to zero. Similar to quantization, the ultimate goal of pruning is to set as many weights to zero as possible, while preserving accuracy. After pruning, it is necessary to fine tune the model. While in some cases, pruning can preserve accuracy, it cannot be used to easily reduce latency because the weight pruning results in the sporadic erasure of weights, making it hard to leverage the structure for faster matrix multiplication. Moreover, if channels are pruned (i.e., using channel pruning) the model accuracy usually degrades.
Knowledge distillation – This term refers to the process of transferring the knowledge learned by a complex model (teacher) to a simpler model (student). Ultimately, the student network can achieve an accuracy that would be un-achievable if it was directly trained on the same data. Therefore, the same accuracy can be achieved with a simpler model. This is usually expressed in shorter running time. Although this idea sounds appealing, recent works suggest that it is impractical in many cases.
Activation statistics – In modern architectures, ReLU is one of the most widely used activation functions. This activation has a unique sparsity property that can be exploited to boost efficiency. For example, the feature maps of AlexNet have a sparsity level between 19% and 63%. Given such a sparse feature map, a more efficient implementation can be used to decrease memory access and FLOPs. While this solution may preserve accuracy, its running time benefits may deteriorate depending on the dataset and network architecture.
Neural Architecture Search – In recent years, there have been several attempts to automatically search for efficient architectures that decrease run-time and preserve accuracy. This is usually done by heuristically searching in the space of all possible architectures or within their subsets. NASNet, EfficientNet, and AmoebaNet are a few architectures of this type. The main issue with this solution is the vast amount of computation required to find such an architecture. Typically, such methods require thousands of hours of GPU to find the best architecture. For this reason, it is inapplicable for most deep learning practitioners.
Conclusion
The idea of efficiency in deep learning has gained increasing popularity in recent years. There are several ways to improve the hardware capacity of deep learning chips; however, these are either expensive or cannot outpace the need for computation resources. This fundamental problem triggered the need for algorithmic solutions that will boost the run-time associated with the inference of deep nets. In this article, we saw some of the solutions and challenges associated with designing efficient deep learning algorithms. In this extensive field of research, all methods have pros and cons. Hence, accelerating inference without sacrificing accuracy is an extremely challenging task. We invite you to read our white paper explaining how Deci AI solved this challenge, or book a demo with one of our experts.









