

On September 18, we submitted several deep learning models to the Open division of the MLPerf v0.7 inference benchmark. In this collaboration with Intel, we used our technology, the Automated Neural Architecture Constructor (AutoNAC), and integrated it with Intel’s OpenVINO toolkit to cut the inference latency and boost throughput of the ResNet-50 model. This collaboration successfully reduced ResNet-50’s latency by a factor of up to 11.8x and increased throughput by up to 11x–all while preserving the ResNet-50 accuracy (within 1%). These results clearly demonstrate the benefits of using algorithmic solutions to accelerate deep learning inference (see official results website). If your DL stack includes models that are based on Resnet-50, this post is definitely for you!
What is MLPerf? The “Olympics” of neural network performance
Established by AI leaders from academia, industry, and research labs, MLPerf is a non-profit organization that provides fair and standardized benchmarks for measuring the training and inference performance of machine learning hardware, software, and services. There are two independent benchmark suites in MLPerf: Training and Inference. Each inference benchmark is defined by a model, dataset, quality target, and latency constraint. Every benchmark also contains two divisions: Open and Closed. The Open division allows modification of the neural architecture, in contrast to the Closed division, which is restricted to benchmarking a given neural architecture without modifications. We submitted to the Open ImageNet ResNet-50 track, and included results for latency and throughput. Moreover, we used three kinds of CPUs as our target hardware, due to the paramount importance of CPU inference in real world applications.
Why is CPU inference so important?
CPUs are ubiquitous, inherent inside everything from large data centers to tiny smartphones. They are also much cheaper than GPUs and consume less power. However, in many real-world applications of neural networks, the inference on CPU devices is difficult due to its high latency, or low throughput. Many research groups around the globe are trying to reduce the runtime of neural networks to enable more extensive use of deep learning inference on CPU devices. Making the move to run deep networks on the CPU has several direct implications. Communication time and costs associated with cloud GPU machines are reduced. New deep learning tasks can be performed in a real-time environment on edge devices. And companies that use large data centers can dramatically cut cloud costs, simply by changing the inference hardware from GPU to CPU.
Deci’s AutoNAC and Intel’s OpenVino together achieve 11.8x Acceleration
MLPerf enabled us to test our core technology on a fair benchmark and we demonstrated top results in all of our submissions. According to the MLPerf rules, our goal was to maximally reduce the latency, or increase the throughput, while staying within 1% of ResNet-50. Table 1 displays the results for latency and throughput scenarios on the hardwares we tested. As shown, our optimized model improves latency between 5.16x and 11.8x when compared to vanilla ResNet-50.
To further distinguish the improvements due to the AutoNAC, we compared a compiled 8-bit ResNet-50 precision to our submitted model. This comparison shows an improvement in latency of between 2.6x and 3.3x. What’s more, our throughput scenario submissions improved ResNet-50 vanilla’s throughput by a factor of 6.9x to 11x. Isolating the net effect of AutoNAC, when compared to a compiled 8-bit ResNet-50 precision, we can see an improvement factor in the range of 2.7x to 3.1x.
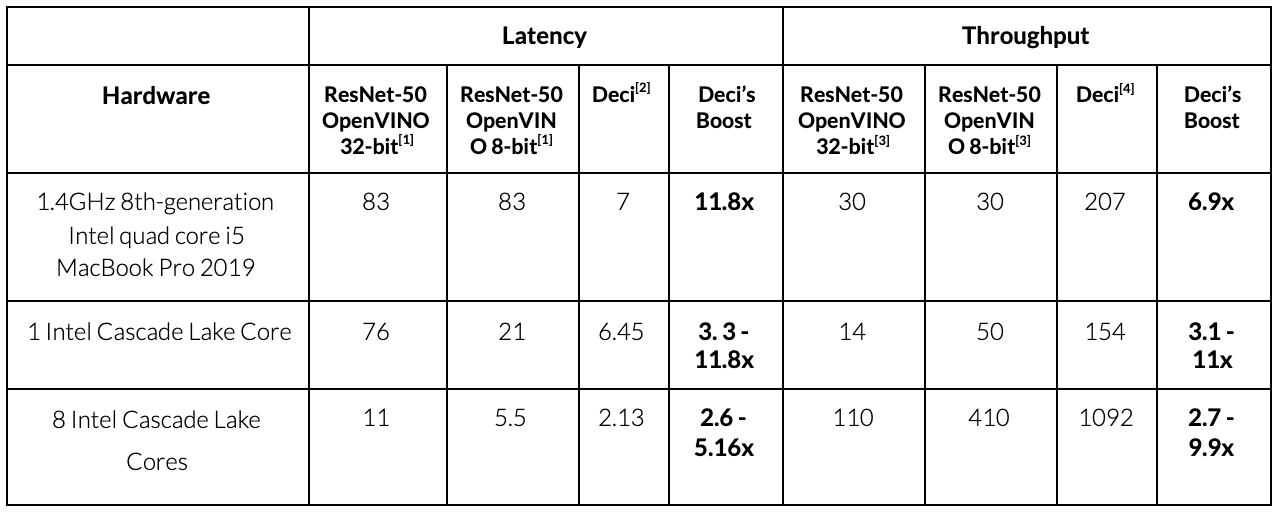
Table 1: Our results for latency and throughput scenarios. Three hardware types were tested. ResNet-50 vanilla is ResNet-50 compiled with OpenVINO to 32-bit. The “ResNet-50 OpenVINO 8-bit” columns show the same hardware with compilation to 8-bit, and the columns labeled “Deci” show the custom model after AutoNAC with 8-bit compilation.
Apples to apples comparison of the results
Although not the main goal, one of the nicest things about MLPerf is that it enabled us to compare our performance to other submitters. To compare apples to apples, we normalized each submission with the number of cores it used. Figure 1 shows our results compared to other submissions. This draws a very optimistic picture, with our throughput per core 3x higher than other submissions.

Figure 1: Comparison of throughput per-core[6] among submissions. On the x-axis the submissions from other companies, and the Intel Cascade Lake Core submission. The y-axis displays the throughput per core of the submission. The green bars are unverified results[3], the yellow and azure are Closed division submissions[5] and the blue is our Open division submission[4].
The technology behind the results – AutoNAC
We started the optimization process with ResNet-50 v1.5 achieving 76.45% top-1 accuracy. Our goal was to minimize the inference latency, or maximize throughput, while keeping the accuracy above MLPerf target accuracy criterion- 75.7%. Deci’s proprietary technology can determine which operations can be compiled better, and based on that replaces the architecture with the optimal compiled architecture. Therefore, our first step was to replace ResNet-50 with a model that achieves similar accuracy but has “compiler aware” operations. In the second step, we applied Deci’s AutoNAC, short for Automated Neural Architecture Construction engine, to reduce the model size. Starting from a baseline architecture, AutoNAC applies a clever AI-based search to a large set of candidate revisions of the baseline. The AutoNAC successfully decreased the latency of the model in a hardware and compiler aware manner. Using the trained model from the AutoNAC, our third step of the optimization was to compile the model with Intel’s OpenVINO. Specifically, we used the OpenVINO post-training optimization toolkit to perform 8-bit quantization on the model and convert the network’s trained weights to 8-bit precision. This gave an additional boost to our model’s performance.
Conclusion
MLPerf provides fair and standardized benchmarks for measuring inference performance of machine/deep learning. Our submission to MLPerf proved that our AutoNAC technology reduces runtime while preserving the accuracy of the base model. This submission shows that the future is bright. When combined with off-the-shelf compilers such as Intel’s OpenVINO, Deci’s AutoNAC can achieve more than 11x improvement over the base models.
Going beyond the remarkable results achieved at MLPerf, the big news is that this kind of performance improvement enables extensive use of deep learning inference on CPU devices. As for us, we can’t wait for the next MLPerf to set new records.
To read the full in-depth article, read the Intel AI blog post.
[1] MLPerf v0.7 Inference Open ResNet-v1.5 Single-stream; Result not verified by MLPerf
[2] MLPerf v0.7 Inference Open ResNet-v1.5 Single-stream, entry Inf-0.7-158-159,173; Retrieved from www.mlperf.org 21 October 2020
[3] MLPerf v0.7 Inference Open ResNet-v1.5 Offline; Result not verified by MLPerf
[4] MLPerf v0.7 Inference Open ResNet-v1.5 Offline, entry Inf-0.7-158-159,173; Retrieved from www.mlperf.org 21 October 2020
[5] MLPerf v0.7 Inference Close ResNet-v1.5 Offline, entry Inf-0.7-87,78,100,122; Retrieved from www.mlperf.org 21 October 2020
[6] Throughput per-core is not the primary metric of MLPerf. See www.mlperf.org for more information
To learn more about achieving similar results for your models, talk to one of our experts.









