

Using machine learning and deep learning to solve various problems has become ubiquitous. This means it’s vital to ensure that the model performs fast inference on the target hardware, without compromising on accuracy. The next item to consider when serving machine learning models is the cost of computing. This is a challenge that can be solved by optimizing the utilization of inference hardware. The third challenge involves deploying production models at scale. The process of configuring and setting up servers for this task can take days or even weeks. What’s more, you need MLOps engineers to continuously monitor the uptime of the systems. This can quickly turn into a very expensive affair. Luckily, the Deci platform can be used to solve all these problems at once. In this article, you will learn how the platform can be used to optimize your machine learning models. We use the YOLOv5 in our example, but the platform allows you to optimize any model.
YOLOv5
YOLOv5 is one the most popular deep learning models in the object detection realm. The task of object detection involves identifying objects in an image and drawing bounding boxes around them. Object detection has various applications, such as autonomous cars, smart robotics, and video surveillance–just to name a few.
Since we’ll be using the YOLOv5 model in this demonstration, let’s take a minute for a brief description.

YOLOv5 is the latest member in the YOLO family of models. YOLO, short for You Only Look Once, is a powerful real-time object detection algorithm that is trained on images to optimize detection performance. According to the model’s GitHub page, the model is faster than previous YOLO versions. The page also provides pre-trained models that you can download and start using right away. The model can also be trained from scratch. However, the smallest model with the smallest image size will cost you 48 hours of 4 v100 GPUs (and a larger image or larger model will be much longer). This is to say that experimenting with this architecture is not cheap.
With that basic information about YOLOv5 out of the way, let’s get started optimizing the model with the Deci platform.
How to optimize the model on Deci
Our first step is to obtain the relevant checkpoint of the trained model we’d like to optimize. In our case, we used the YOLO v5 that was trained on the COCO dataset and is in the ONNX format, an open format aimed at machine learning interoperability. The Deci platform also supports other model formats such as Keras, TensorFlow, or PyTorch. We’re going to target the T4 GPU, which offers good value for money. T4 is a deep learning accelerator developed by Nvidia.
Another really cool feature is Deci’s Model Hub. It’s a library of trained models that are ready for optimization. You simply have to clone them to your lab (your personal model repository). Model Hub already has a wide variety of models and it’s growing each day. YOLOv5 will soon be available there as well. So, stay tuned.
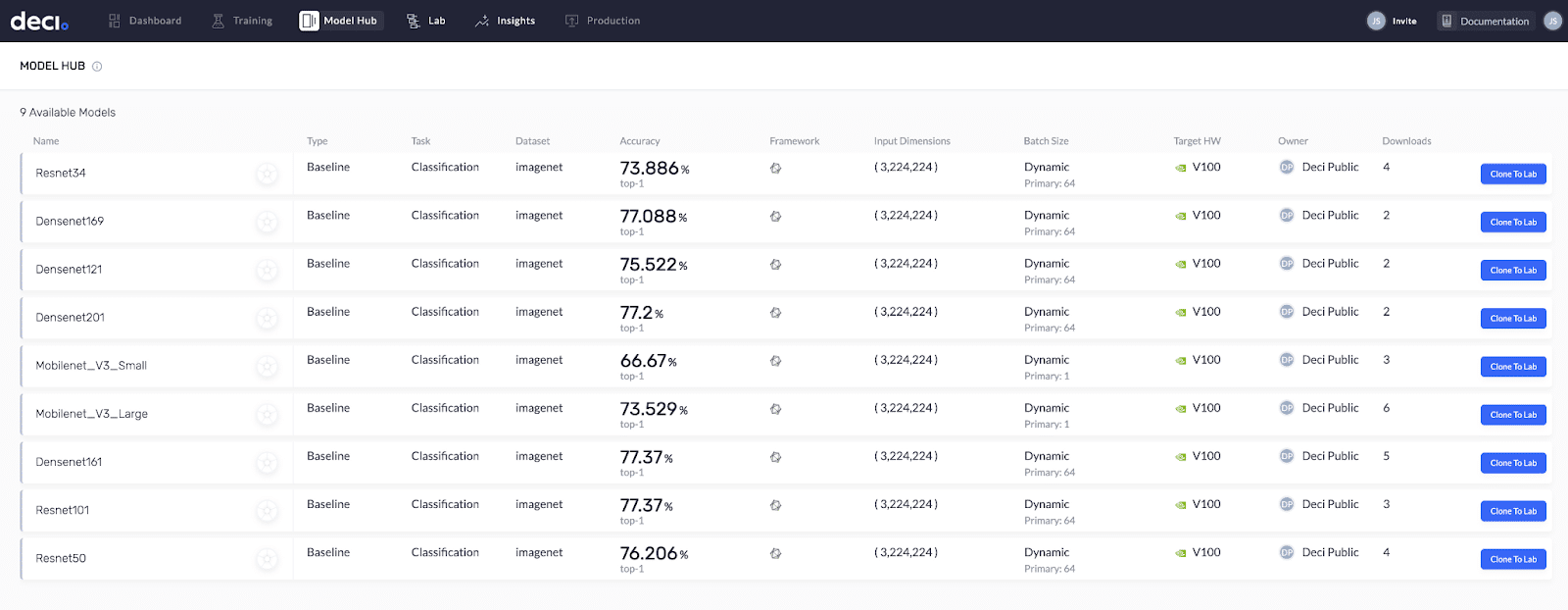
Deci’s Model Hub is a library of trained models that are ready for optimization.
Step 1: Request free trial of the Deci Platform
The next step is to book a demo of the Deci Platform. Fill out the form to get started.
Deci’s platform sign up page.
Deci will send you an email with instructions on how to verify your account. Once you verify your account, you’ll be greeted with Deci’s lab screen. This is the place where all the magic happens. Deci also provides a sample ResNet-50, ImageNet model, pre-optimized for CPU and GPU. You can use that to get a feel for the platform right away.
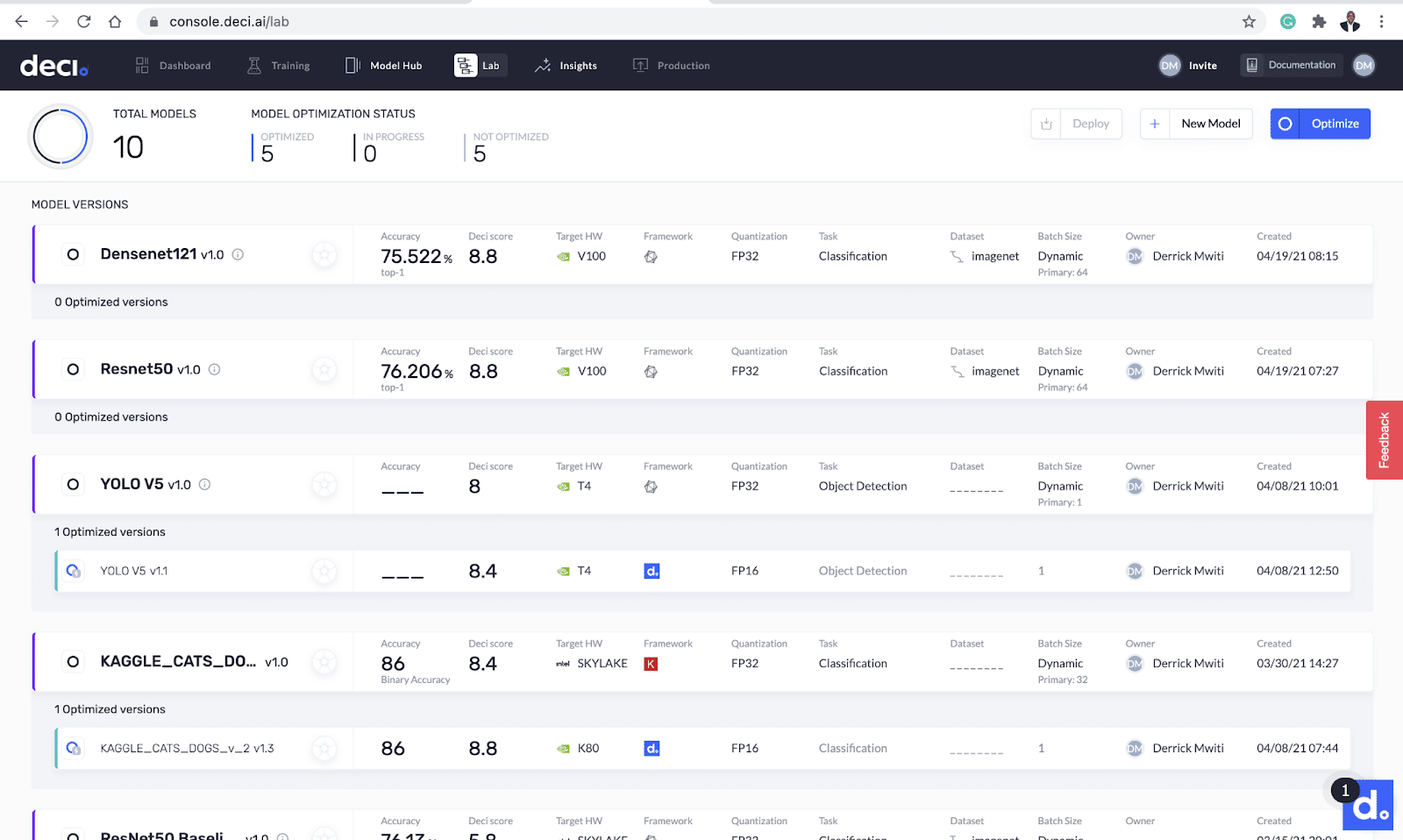
Deci’s lab screen.
Step 2: Uploading the model
Click the New Model button to upload the model.
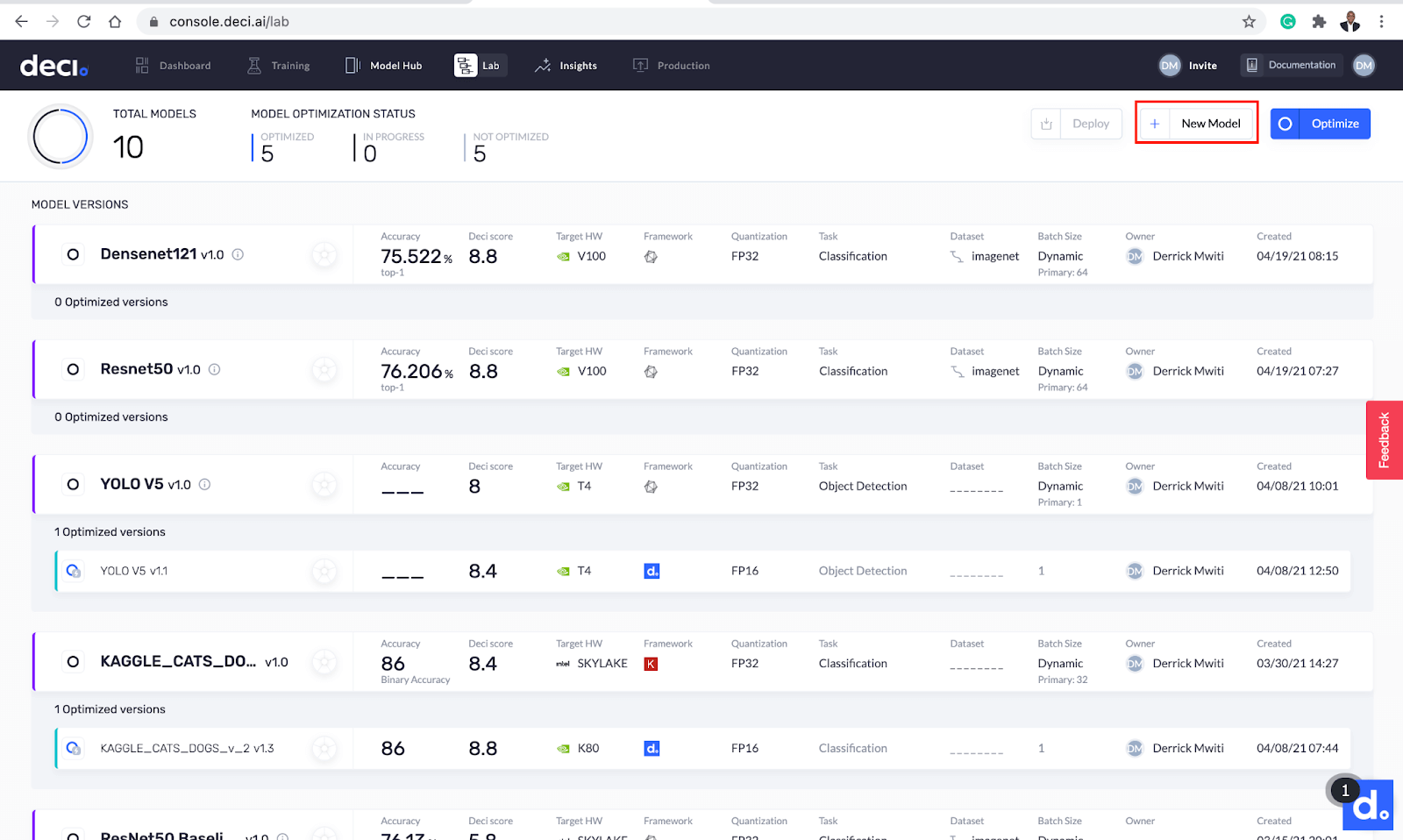
Upload a new model right from the lab screen.
The next pop-up gives you the option to upload the model and add its details. There are a couple of things you need to provide on this page:
- Model name
- Optional model description
- Type of task
- Inference batch size
- Target hardware
- Model framework
- Input dimensions of the model
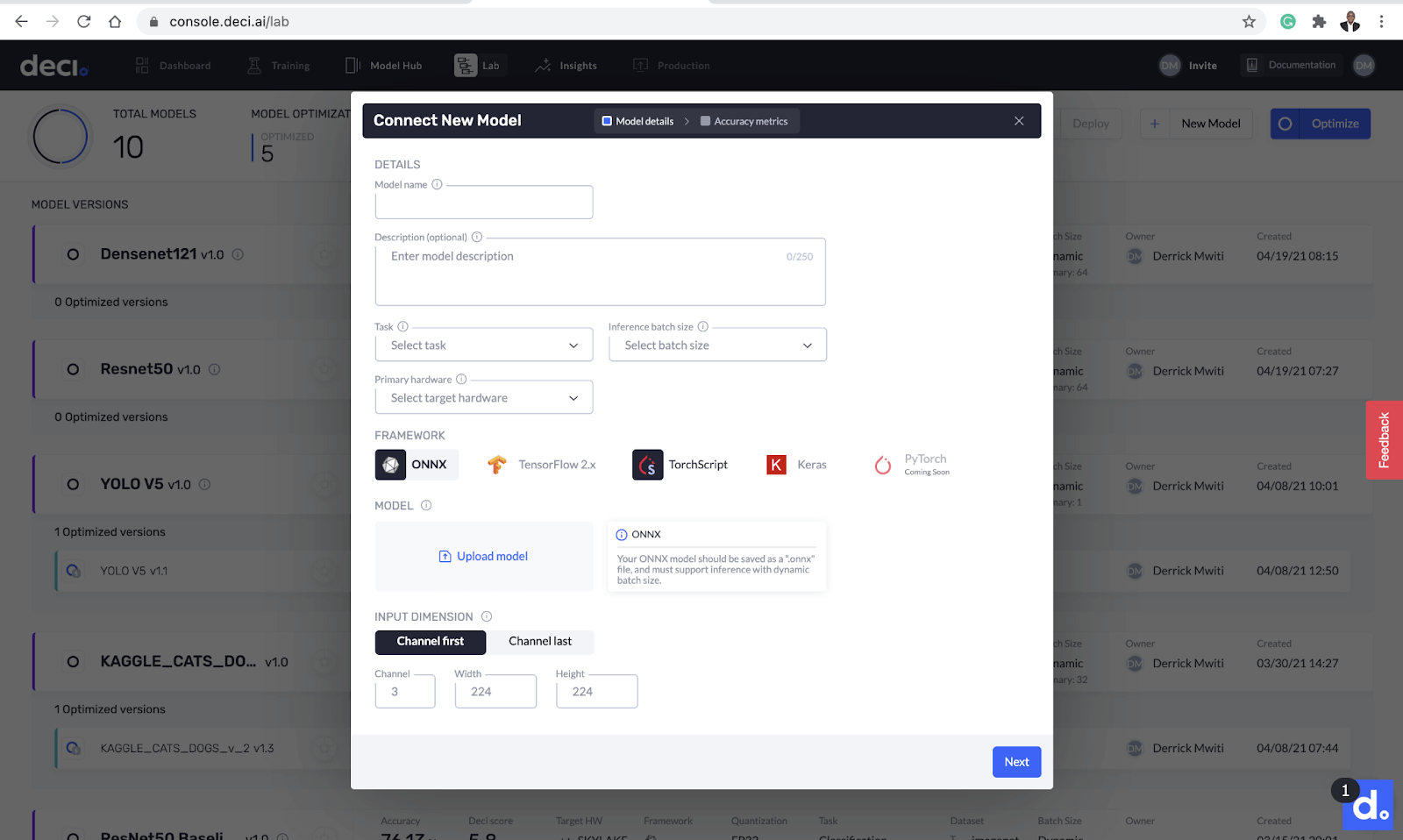
Add details to the model such as model name, inference batch size, target hardware, and more.
Let’s fill in this information. As you can see from the screenshot above, you need to know the input dimensions required by the model. A quick way to figure that out is to upload the model to Netron. Clicking the input node will display the input dimensions. This model has input dimensions of 3 x 320 x 320.

Netron app
With that information in hand, head back to Deci’s lab screen and fill it in. Deci also lets you key in the model’s accuracy but doesn’t verify it. Since we are not linking any dataset, we can leave it blank for now.
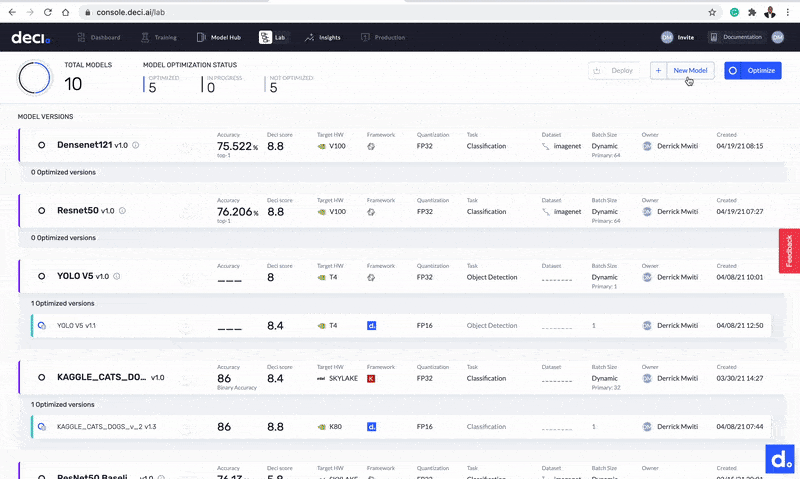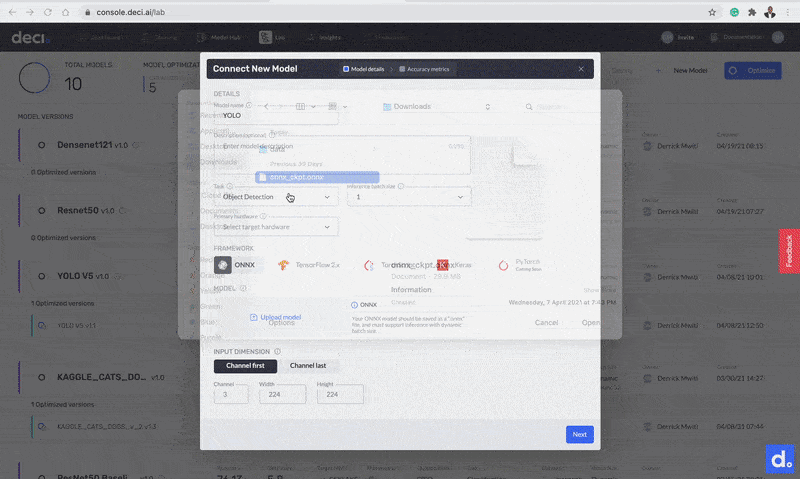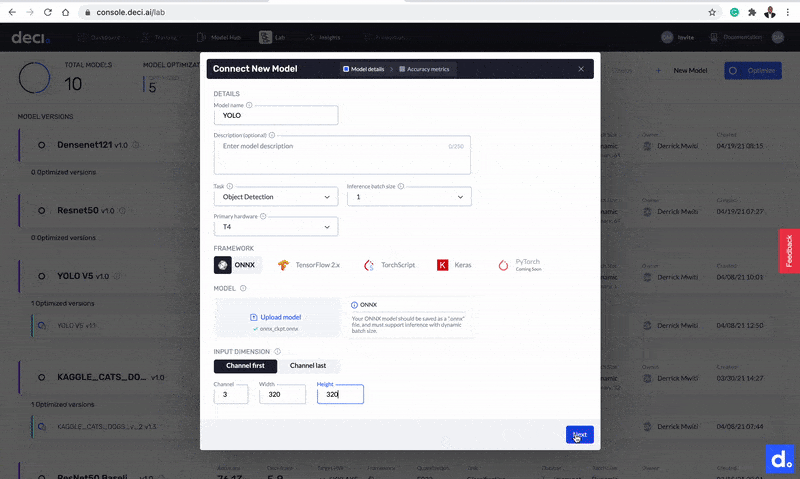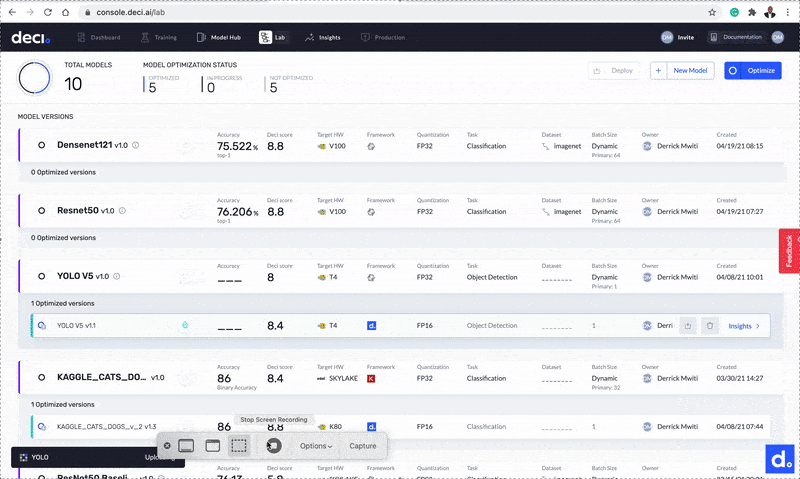
The process of uploading the model and automatically performing some benchmarks takes about 2 minutes.
Deci will now upload the model and automatically perform some benchmarks. This process takes about 2 minutes to complete. Once the process is done, you’ll see the results on the Deci lab screen.
Step 3: Check Deci model insights
The Deci score is one of the metrics displayed on the Deci lab screen. This is a number between 0 and 10 that tells you the model’s efficiency at runtime, on the targeted hardware. It shows how efficient your model would be in a production environment with the specified hardware and batch size.
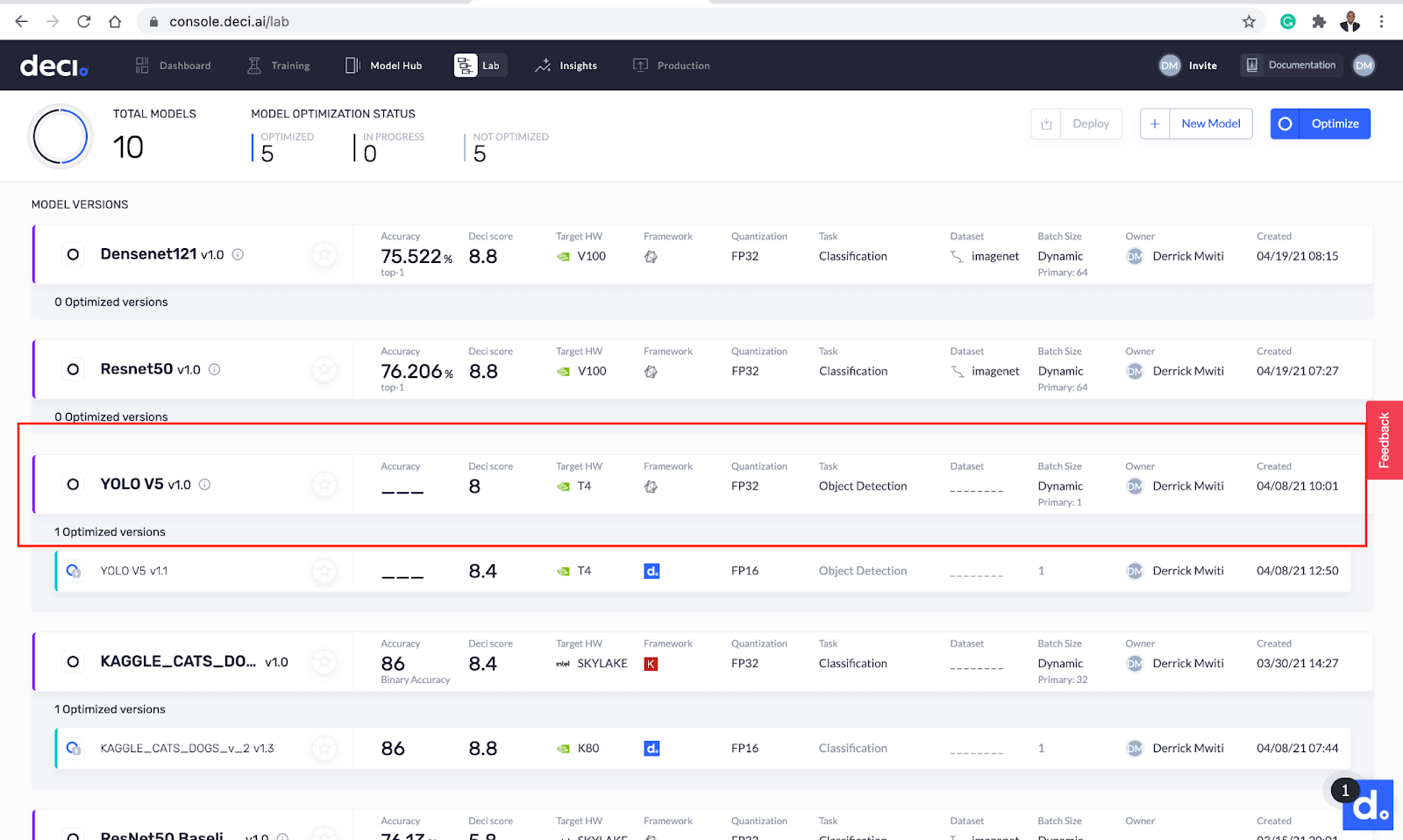
The Deci score shows the model’s efficiency at runtime, on the targeted hardware.
You can also view more insights by clicking the Insights button next to the model you just downloaded.
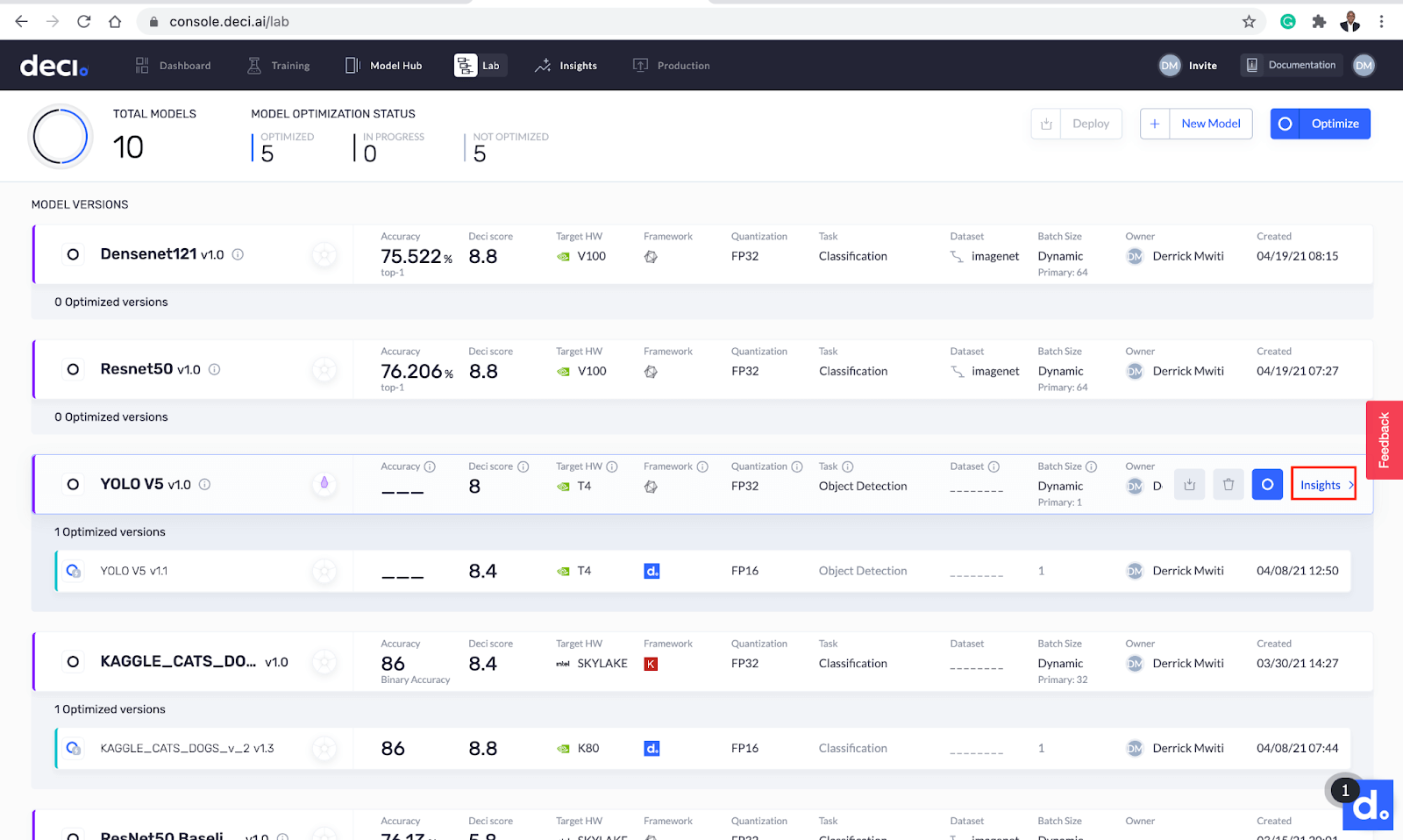
The Insights button offers more details.
Let’s take a closer look. There are a couple of metrics you’ll see on this page:
- Throughput: the number of requests processed by the model in a certain timeframe.
- Latency: your model’s delay when it is performing inference on a production server.
- Model size: the space the model takes up in the physical storage
- Memory footprint: the memory used by your model during inference.
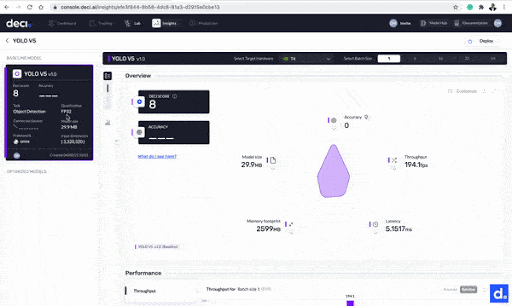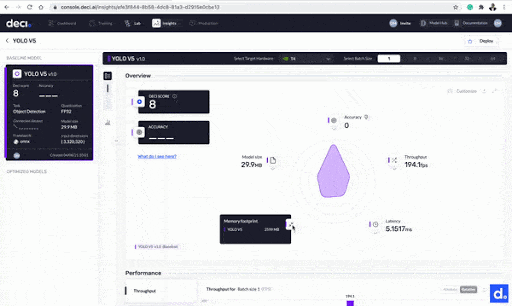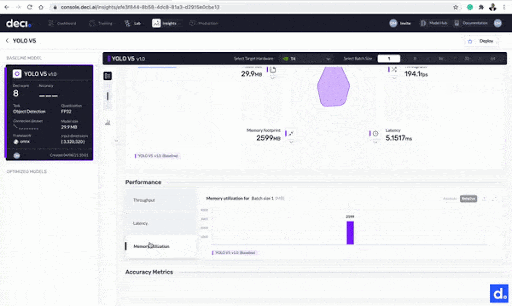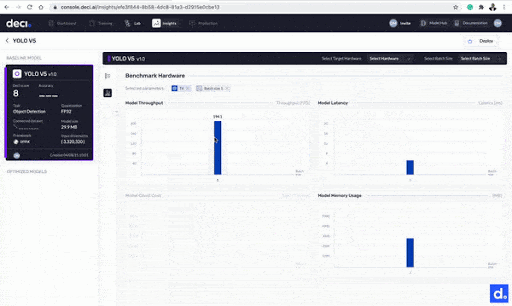
More metrics provided by the Deci platform.
Step 4: Optimize the model
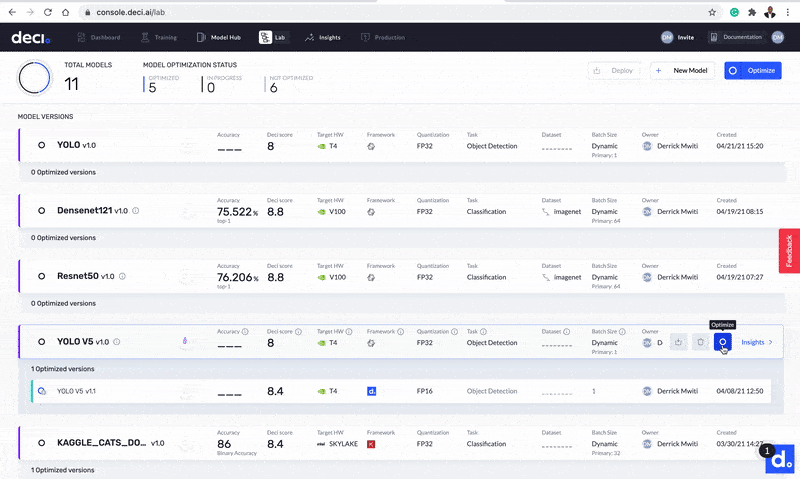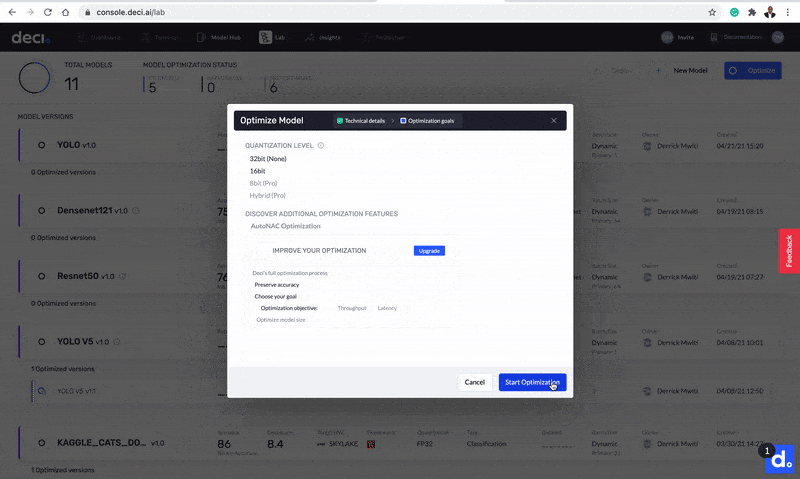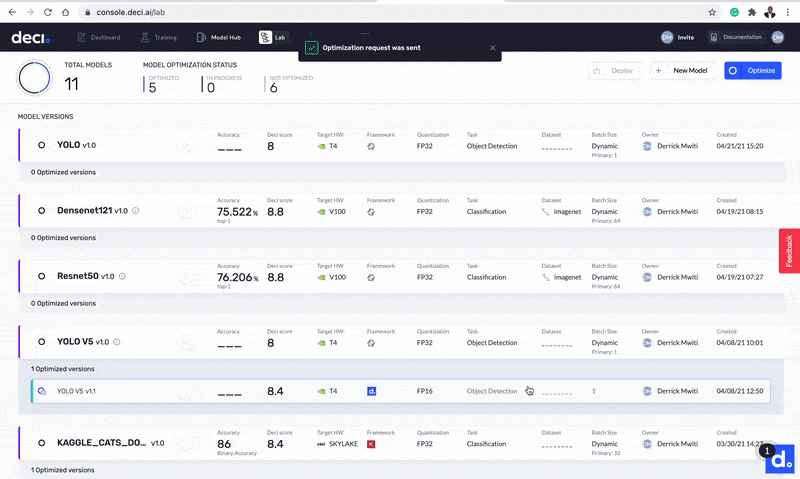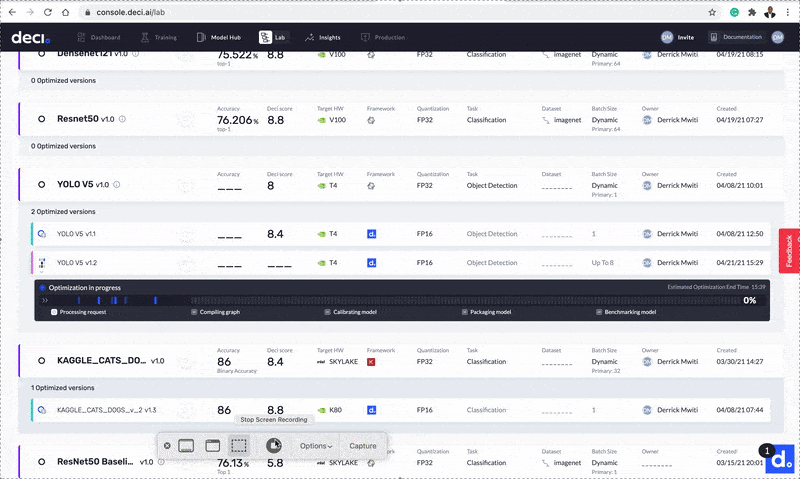
The next step is to use the platform to optimize the model. After that, we’ll compare the results from the optimized model with the initial model. You can initiate the model optimization by clicking the Optimize button next to the model.
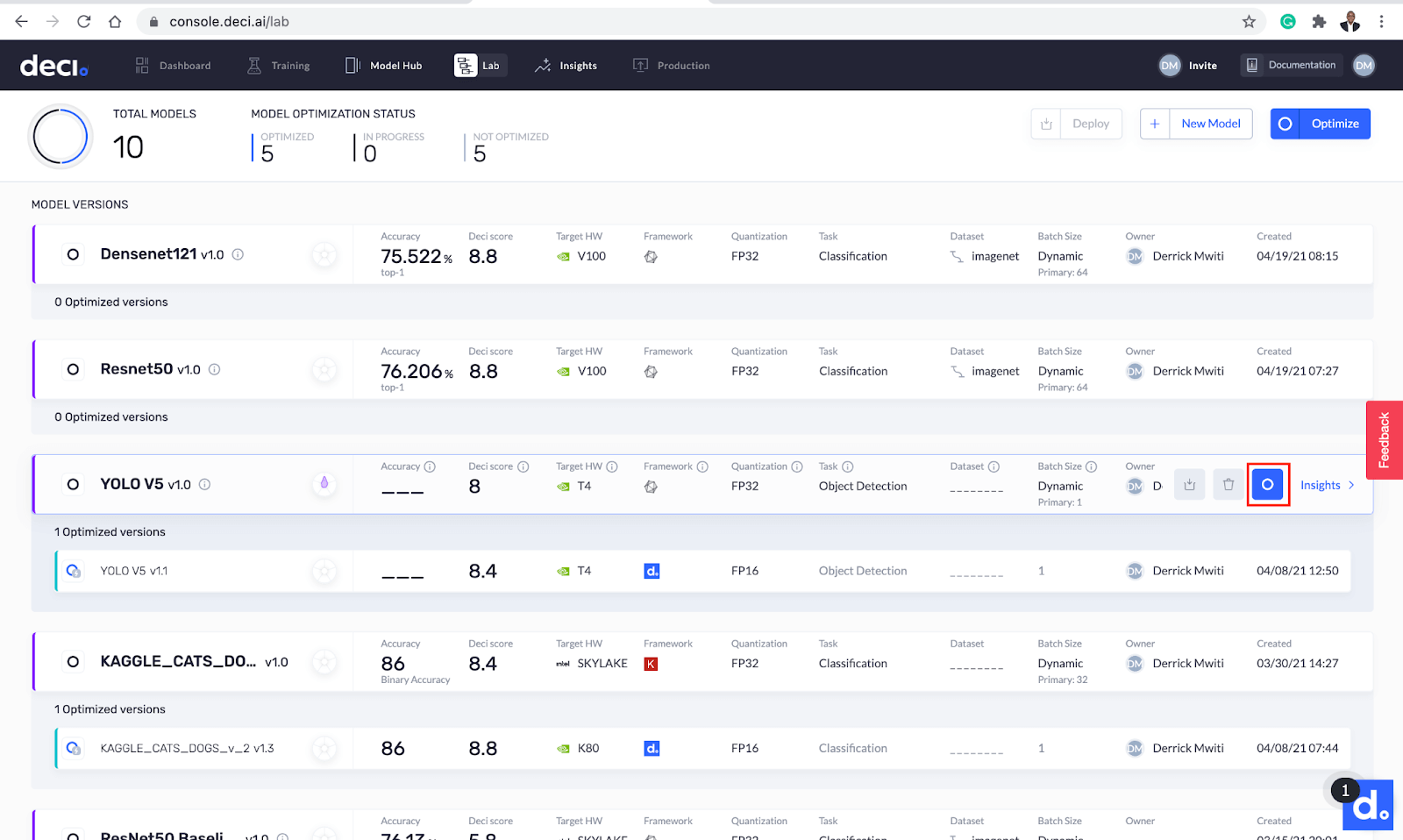
Initiate model optimization.
The next screen lets you configure the model’s optimization. You can choose to optimize the model for a CPU, GPU, or mobile device. Let’s do that by selecting the T4 GPU. You also have the option to select the batch size for your optimization. Let’s use a batch size of 1 in this case.
On the same screen you will see AutoNAC optimization, which is a paid feature that offers a higher level of optimization. Optimization for mobile and for lower levels of quantization are also pro features.
As we go through this demonstration, it’s important to keep our optimization goals in mind. These goals are to obtain a model with low inference and a high throughput. To achieve that, we optimize the model via 16-bit quantization. In the quantization process, the numbers are stored with less precision, hence taking up less memory. This means that expensive operations can be replaced with cheaper ones, leading to less inference time for the model.
Fill in the details for model optimization.
You should now see the optimization process progress bar. Sit tight and wait for the wizards at Deci to perform their magic!
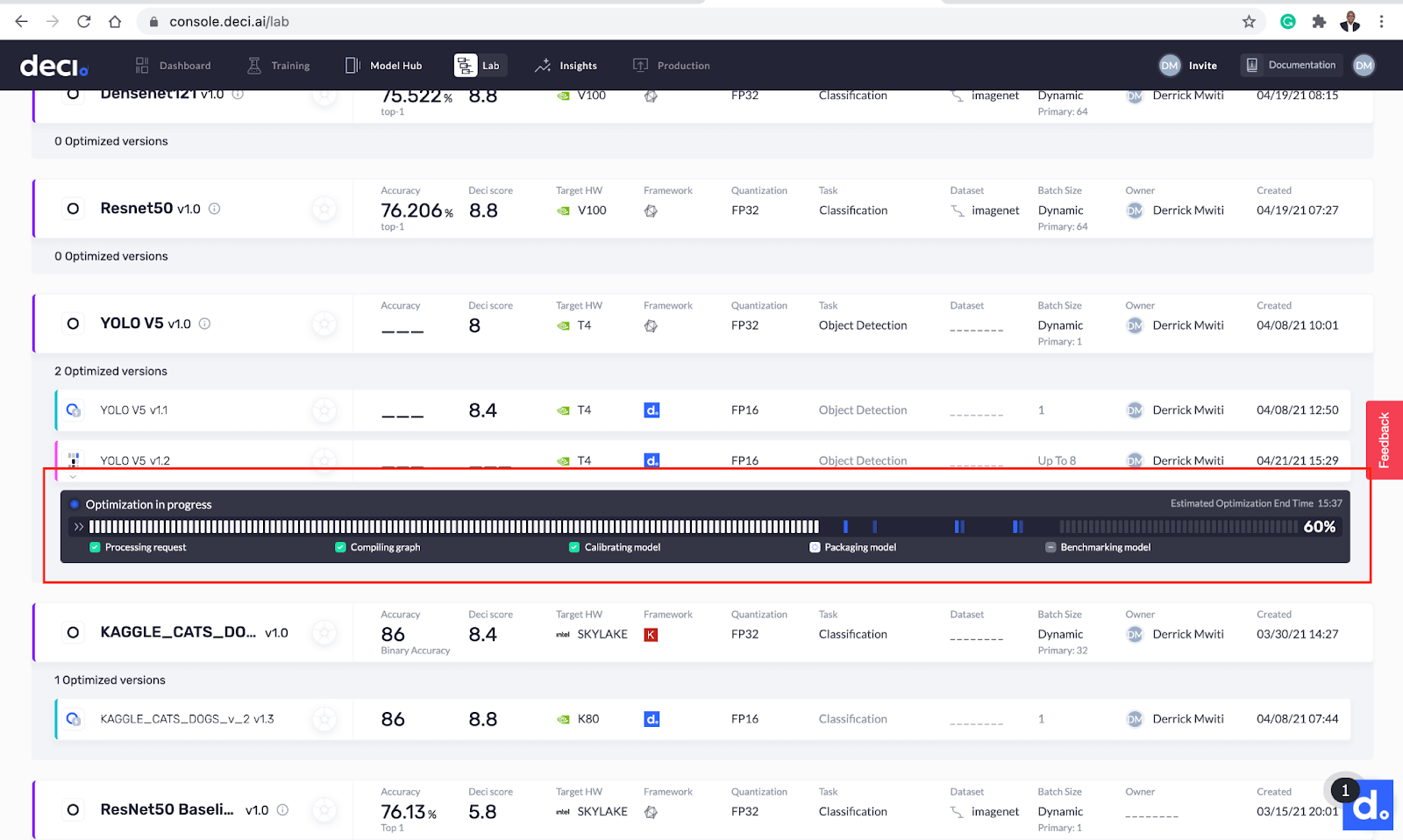
The optimization process progress bar.
The optimization is completed in roughly 11 minutes. After that, the new optimized model appears below the base model. You can quickly see that the Deci score increased after optimization.
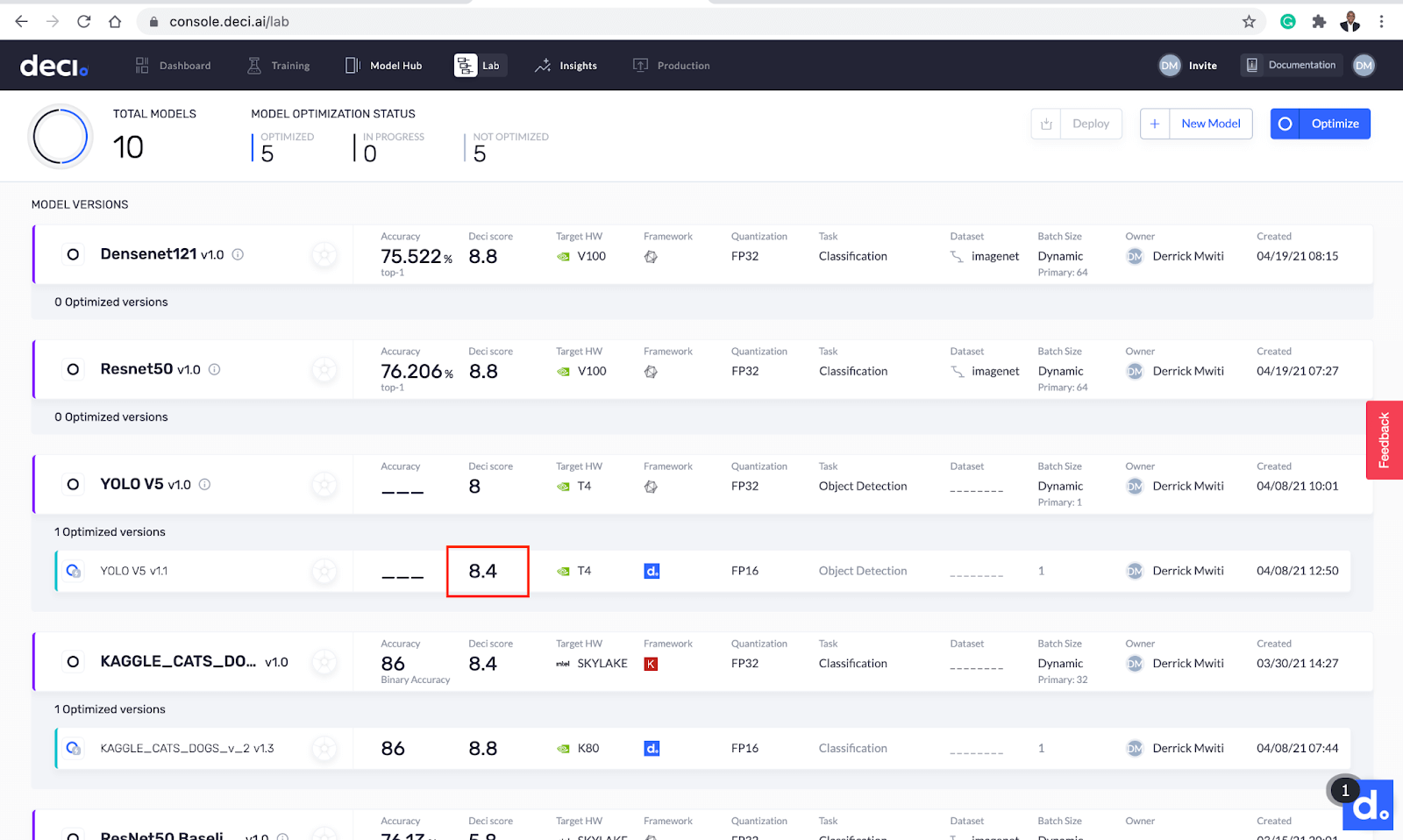
The Deci score increased after optimization.
Comparing the final results
With the optimization complete, it is now time to compare the base and optimized models. Click the Insights button next to any of the models to get started. Let’s take a look at the differences:
- The model’s throughput improved from 194.1 FPS to 413.2 FPS. The model is now 2.1 times faster.
- The size of the model is reduced from 29.9 MB to 22.07 MB.
- The model’s latency improved by 2.1 times from 5.1517 milliseconds to 2.4202 milliseconds.
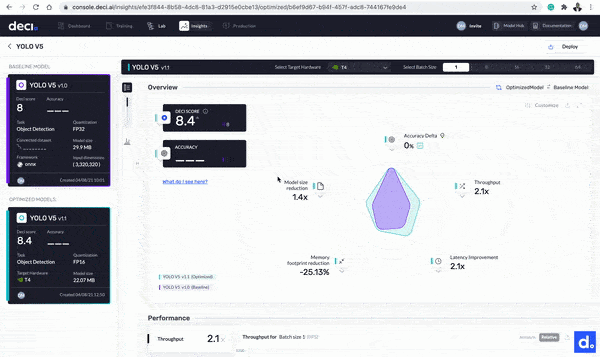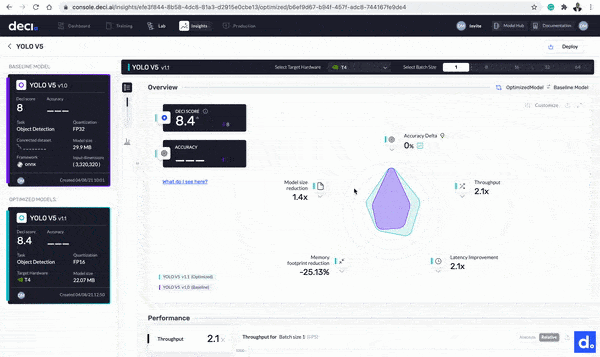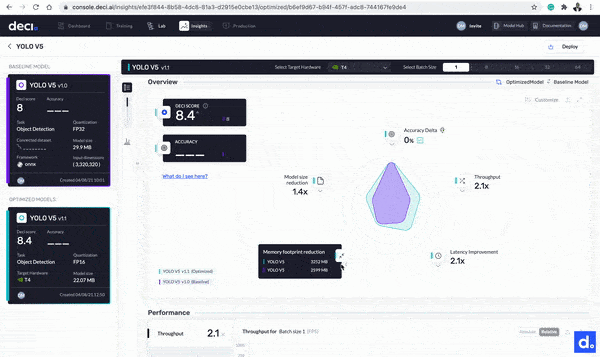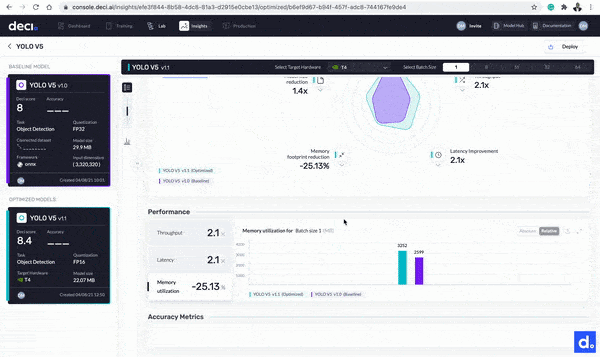
Click the Insights button next to any of the models to compare the base and optimized models.
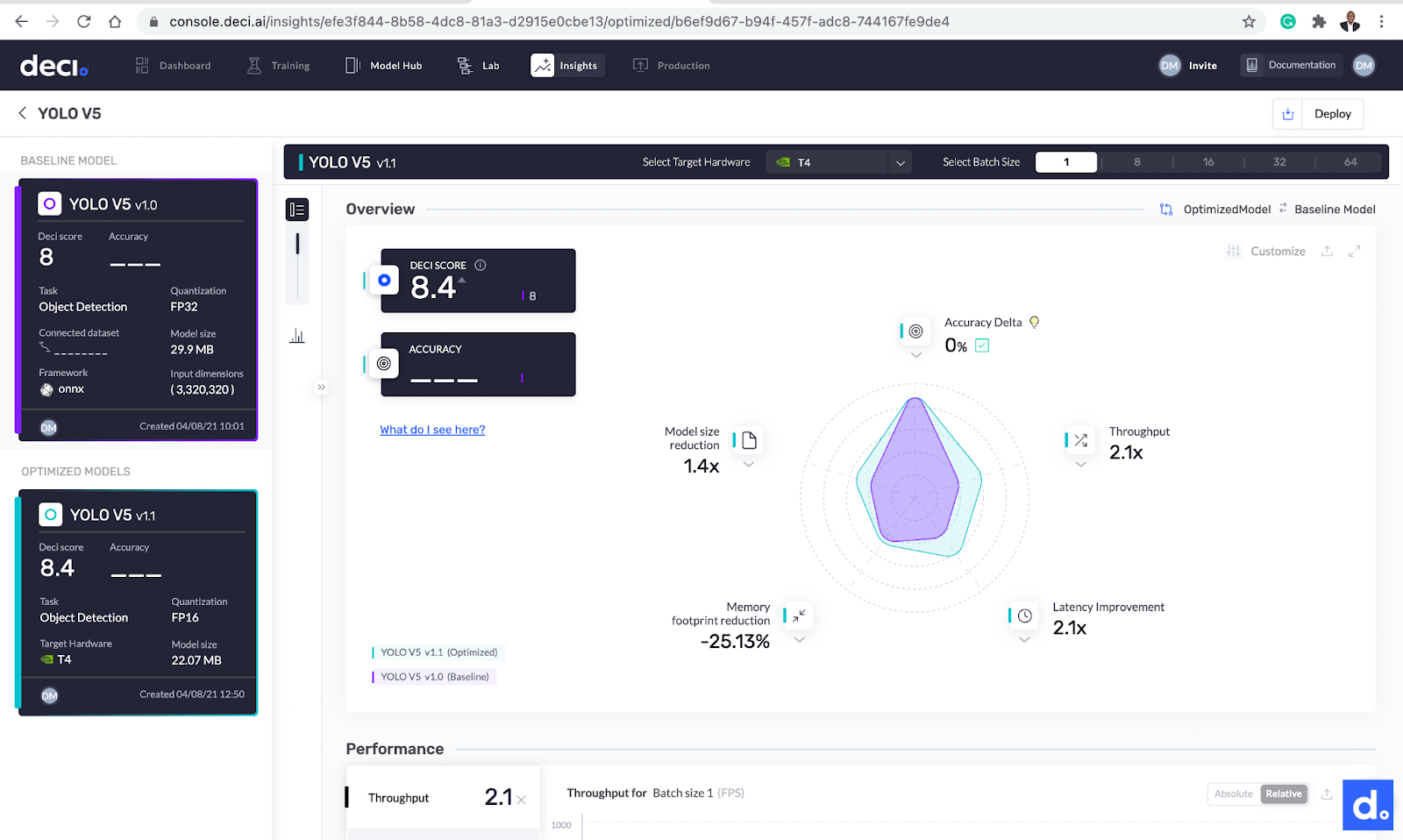
Summary of metrics.
Conclusion
As you have just seen, you can double the performance of a YOLOv5 model in 15 minutes overall time. You also saw that the Deci platform is super easy and intuitive to use.
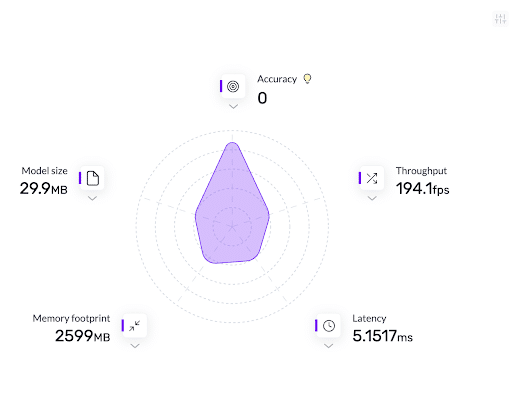
Before model optimization
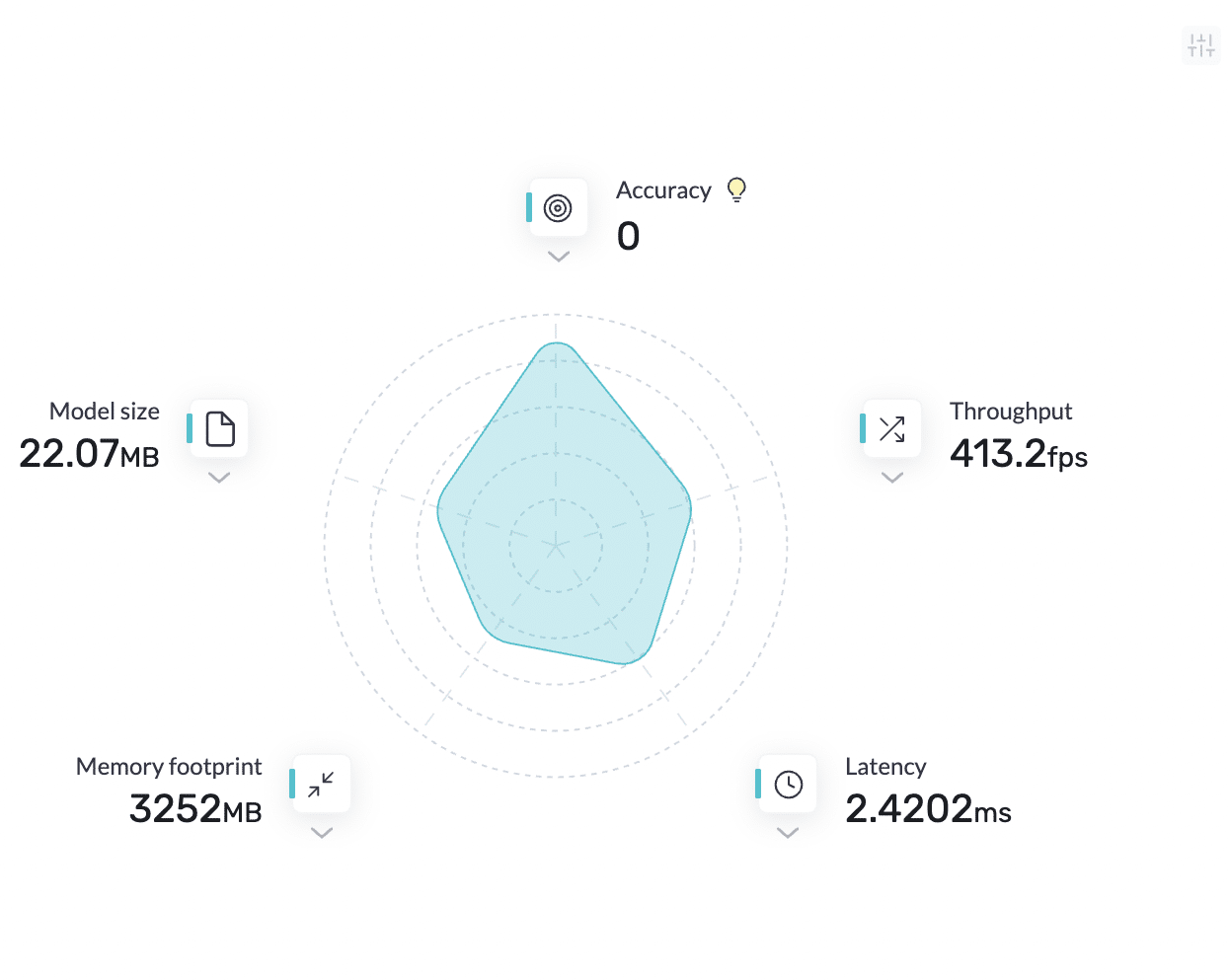
After model optimization
Here’s a graph comparing the before and after model latency.
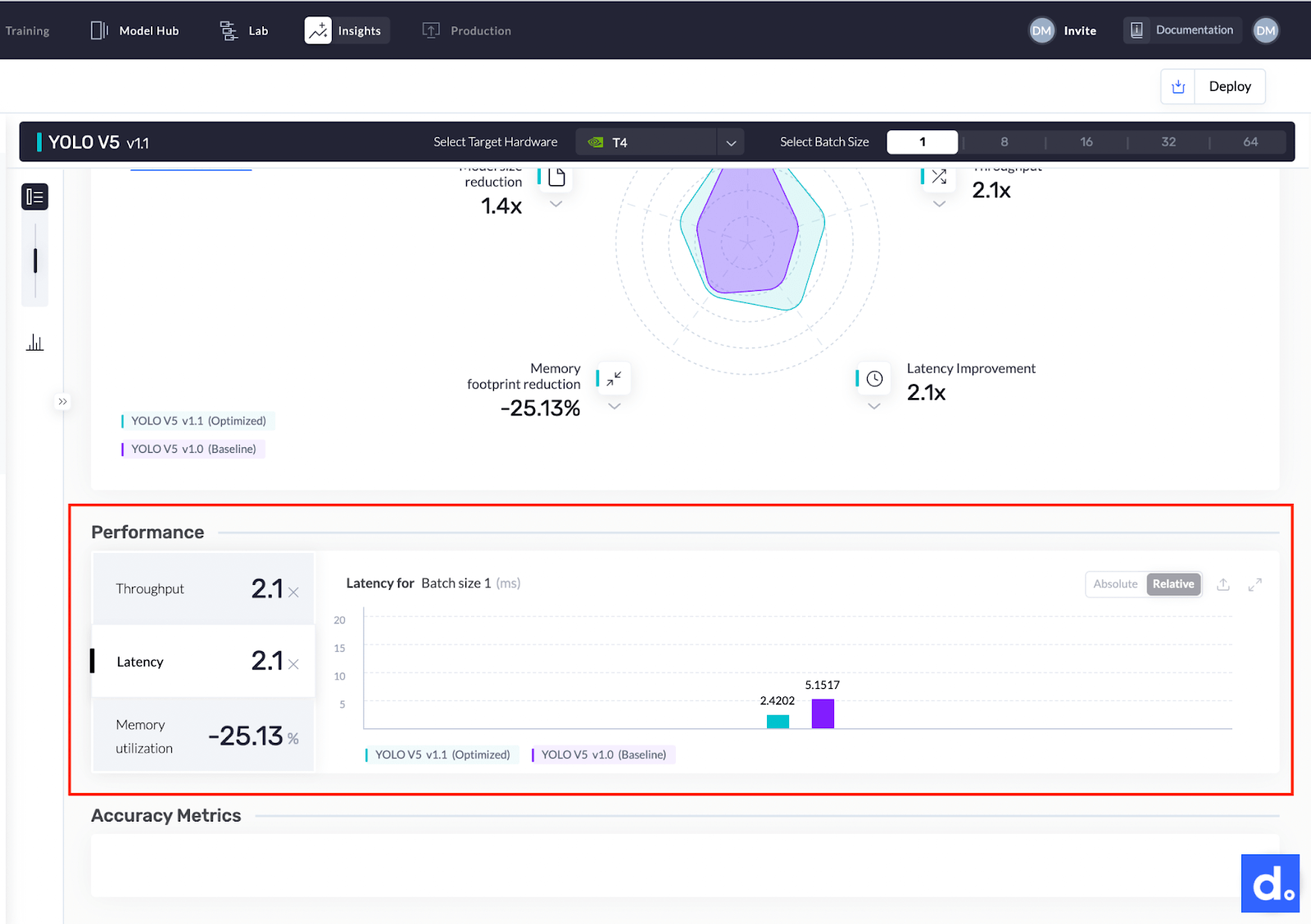
Before and after model latency.
The image below shows a comparison of the throughput for the two YOLO models.
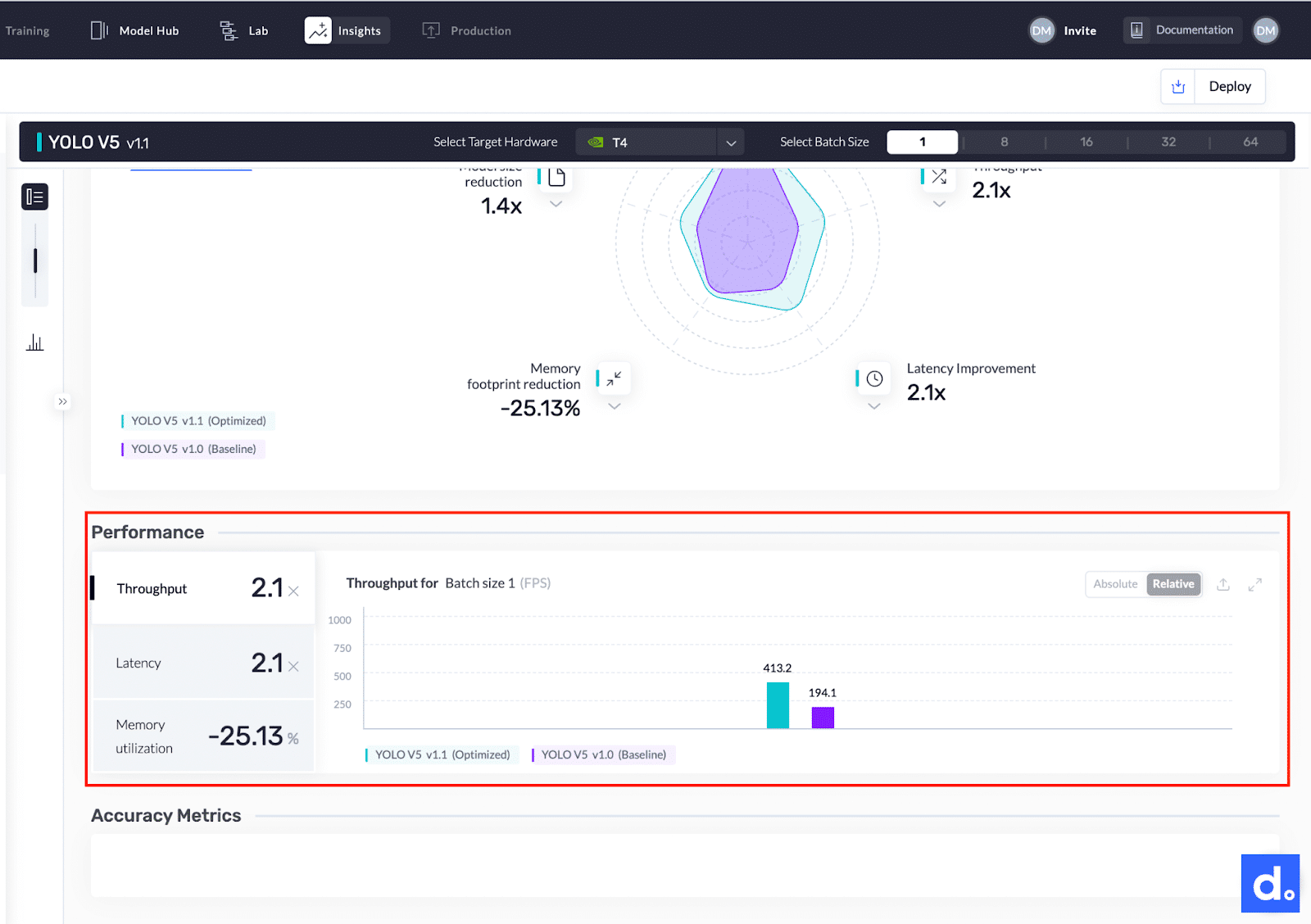
Throughput comparison of the two YOLO models.
Before wrapping up, let’s discuss some of the advantages Deci offers:
- Optimize your model’s inference throughput and latency without compromising accuracy
- Allows you to optimize models from all the popular frameworks
- Supports models targeted at any deep learning task
- Supports deployment on popular CPU and GPU machines
- Benchmarks the fitness of your model on different hardware hosts and cloud providers
- Gets uploaded models ready for serving, inference, and deployment
In another blog, we’ll cover the Deci features that enable seamless deployment to production environments. In the meantime, why not try optimizing your own models?









