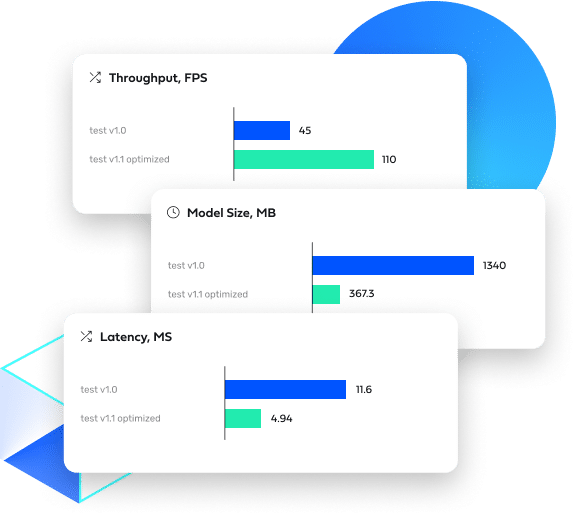
Deci’s hardware-aware models, custom generated with the AutoNAC engine, enable AI developers to achieve GPU-like AI inference performance on CPUs in production for both computer vision and NLP tasks.
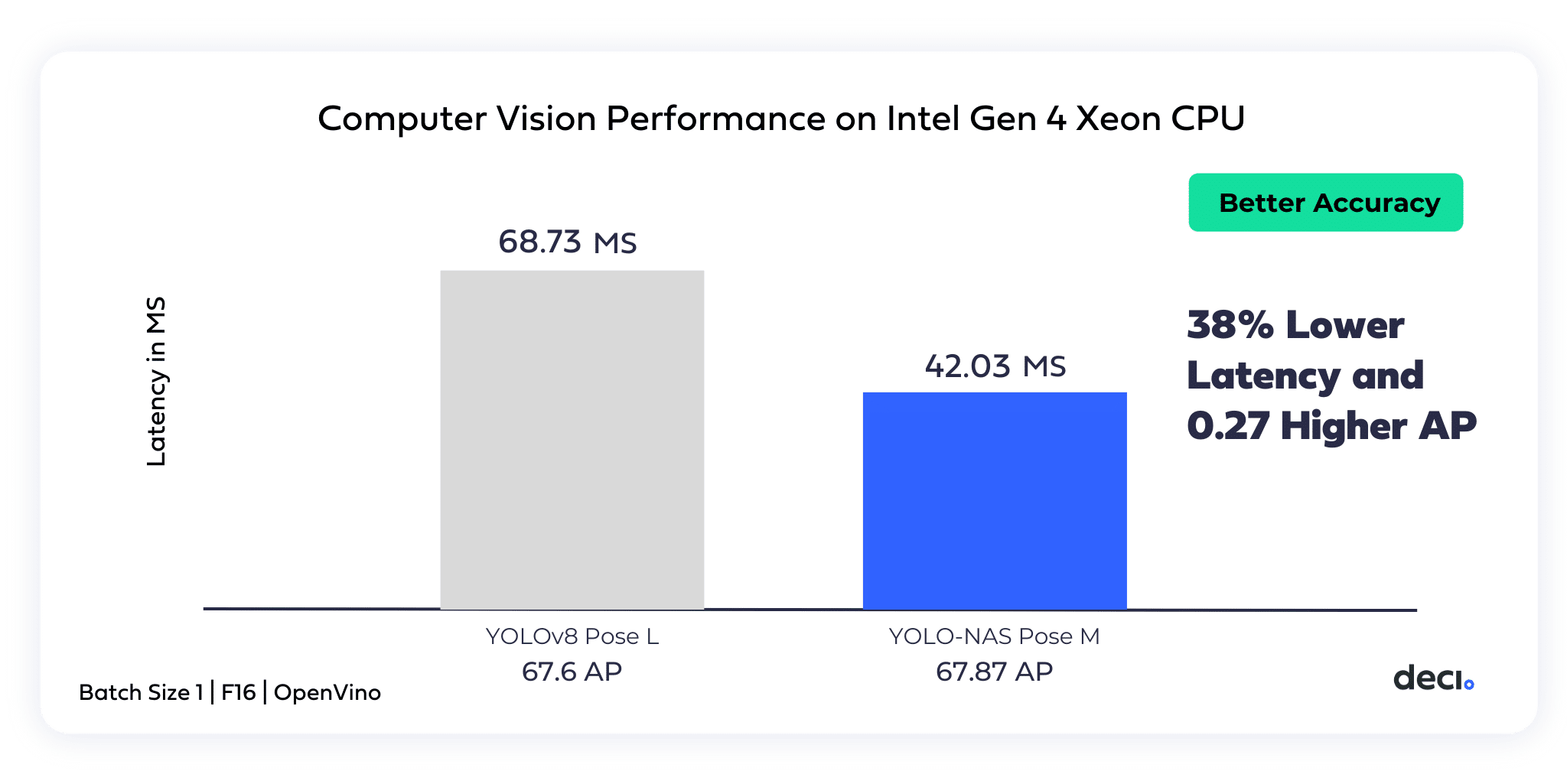
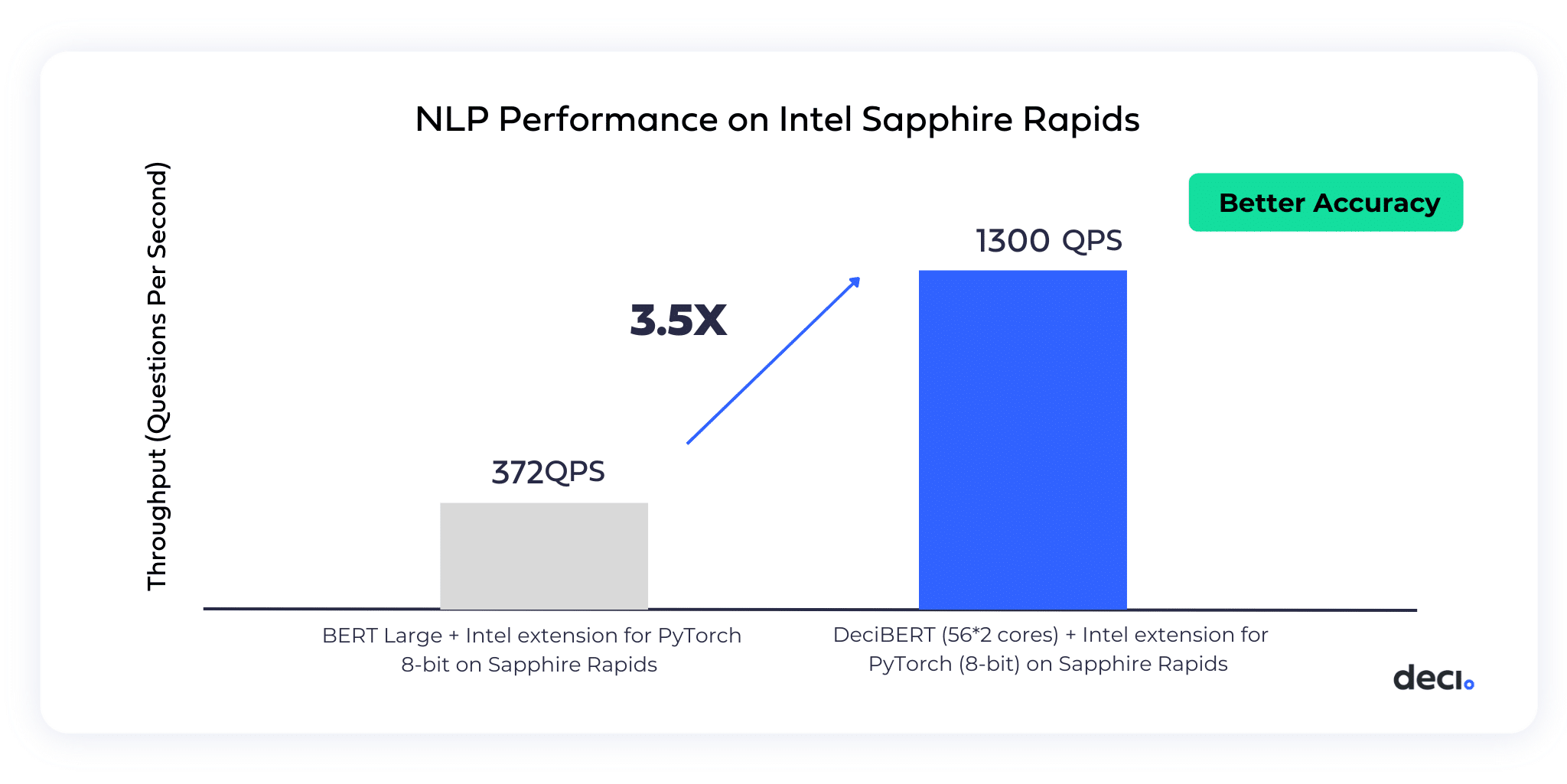
Choose an ultra performant model or generate a custom one.
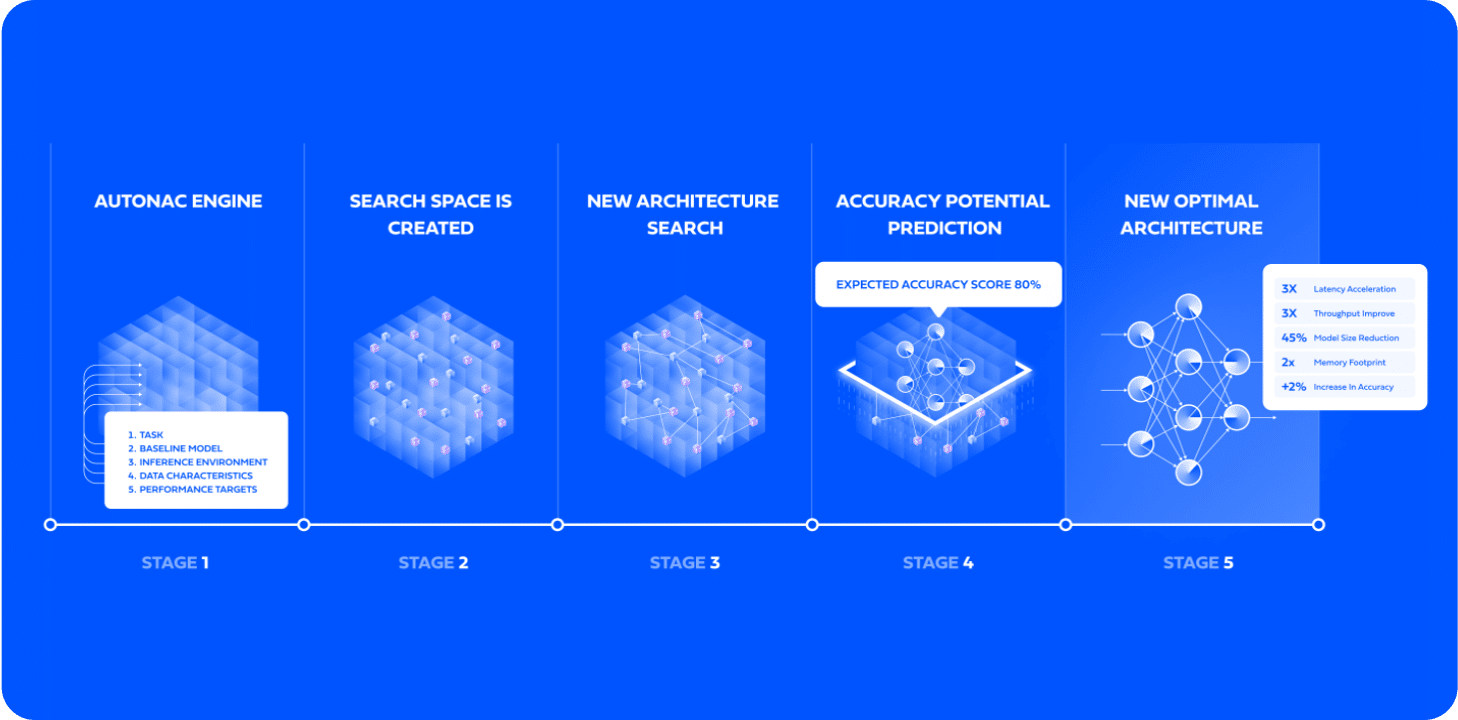
AutoNAC
Neural Architecture Search Engine
DataGradients™
Dataset Analyzer



Use Deci’s library & custom recipe to train on-prem.
SuperGradients™
PyTorch Training Library

Apply acceleration techniques. Run self-hosted inference anywhere.
Infery
Optimization & Inference Engine SDK

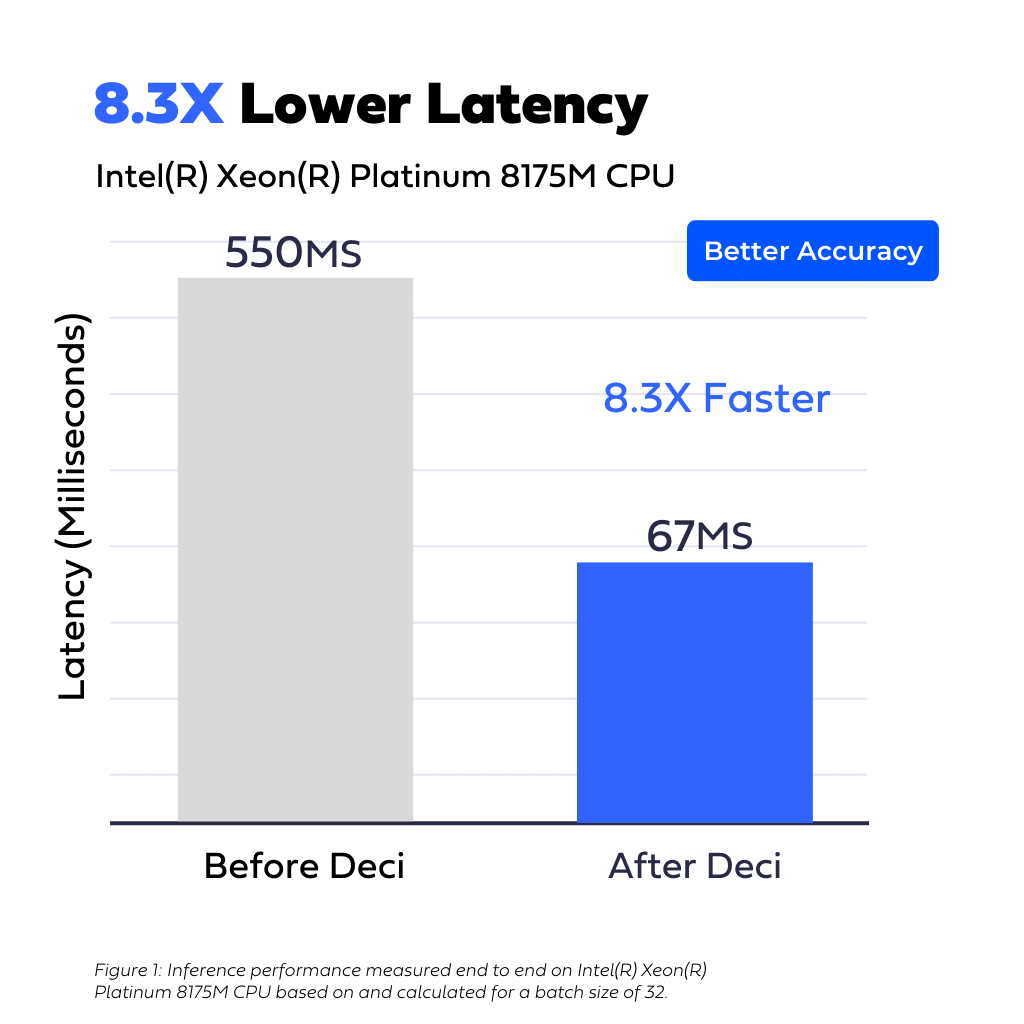
A multinational manufacturer and distributor of electricity and gas was looking to improve the latency of an automatic extraction of text from documents and images using OCR and NLP.
Using Deci’s AutoNAC engine the customer was able to gain 8.3x faster latency compared to its original model while also improving the accuracy from 77.17% to 80.21% (word-level).
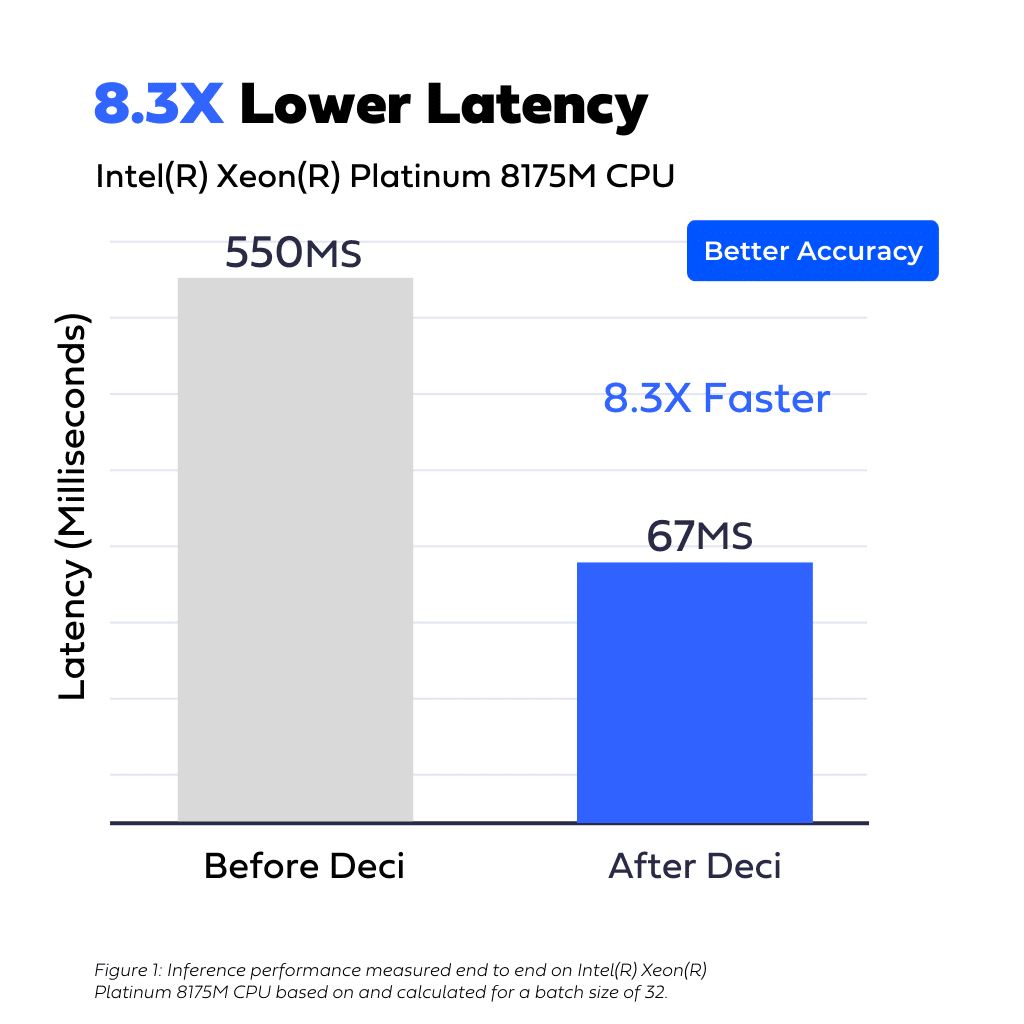
A multinational manufacturer and distributor of electricity and gas was looking to improve the latency of an automatic extraction of text from documents and images using OCR and NLP.
Using Deci’s AutoNAC engine the customer was able to gain 8.3x faster latency compared to its original model while also improving the accuracy from 77.17% to 80.21% (word-level).
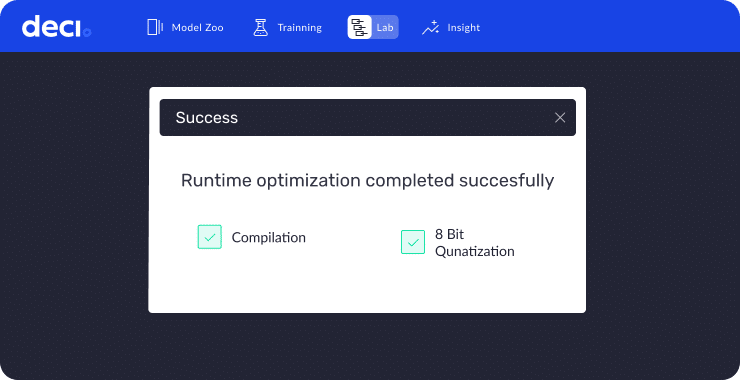
Easily compile and quantize your computer vision and NLP models with to improve runtime on your Intel CPUs using Intel OpenVINO.
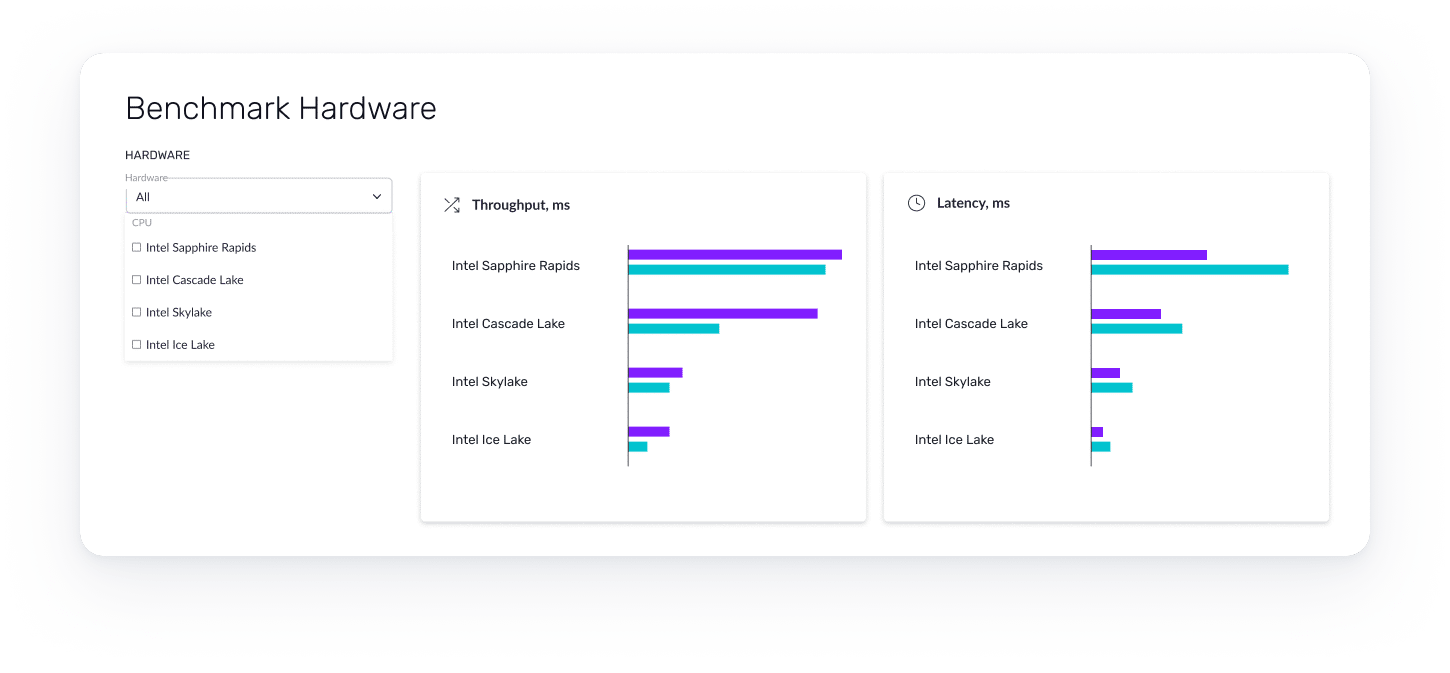
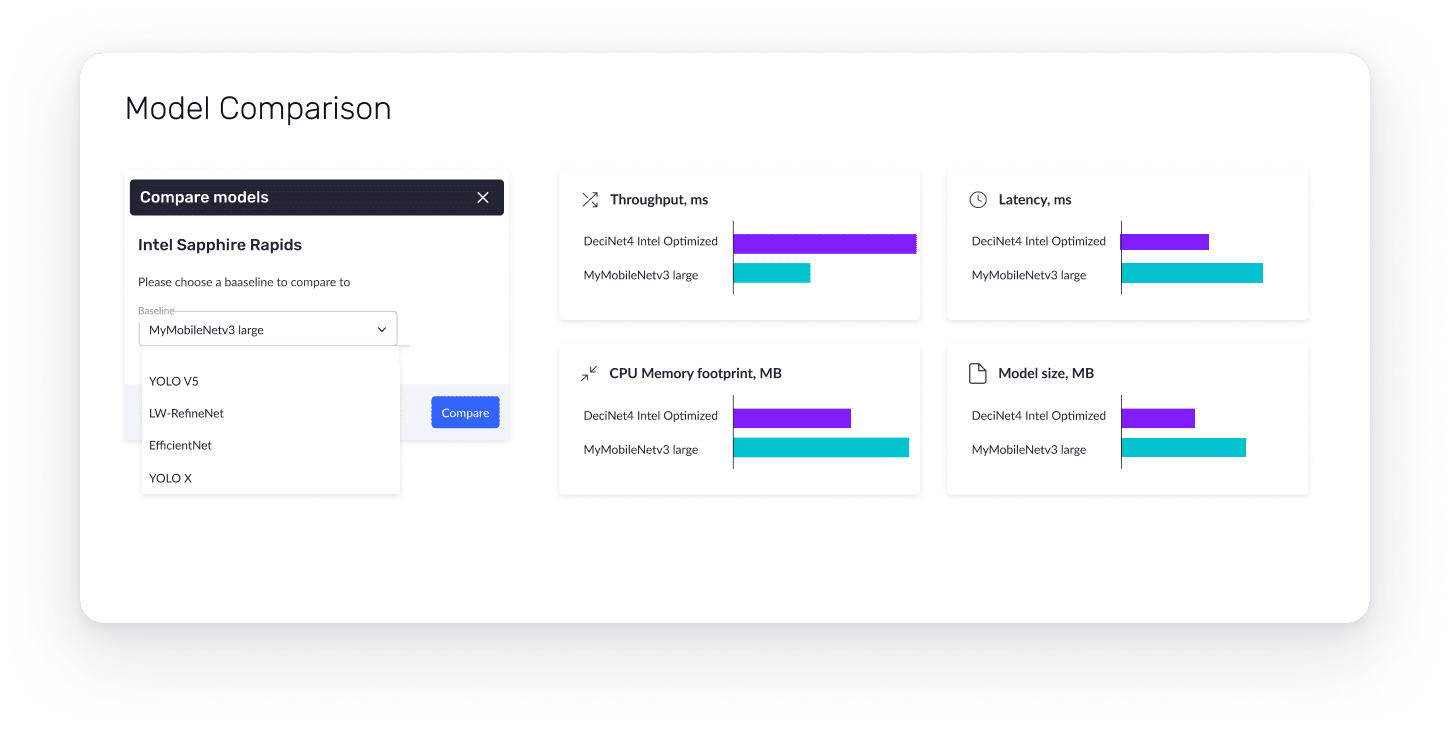
Measure inference time of different models on various Intel CPUs directly on Deci’s cloud-based hardware fleet.

Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")



