Deci achieves the highest inference speed ever to be published at MLPerf for NLP, while also delivering the highest accuracy.
Tel Aviv, Israel, April 5, 2023 — Deci, the deep learning company harnessing Artificial Intelligence (AI) to build better AI, today announced results for its Natural Language Processing (NLP) model submitted to the MLPerf Inference v3.0 benchmark suite under the open submission track. Notably, the NLP model, generated by Deci’s Automated Neural Architecture Construction (AutoNAC) technology, dubbed DeciBERT-Large, delivered a record-breaking throughput performance of more than 100,000 queries per second on 8 NVIDIA A100 GPUs while also delivering improved accuracy. Also, Deci delivered unparalleled throughput performance per TeraFLOPs, outperforming competing submissions made on even stronger hardware setups.
Running successful inference at scale requires meeting various performance criteria such as latency, throughput, and model size, among others. Optimizing inference performance after a model has already been developed is an especially cumbersome and costly process, often leading to project delays and failures. Accounting for the inference environment and production constraints early in the development lifecycle can significantly reduce the time and cost of fixing potential obstacles to trying to deploy models.
“These results demonstrate once again the power of Deci’s AutoNAC technology, which is leveraged today by leading AI teams to develop superior deep learning applications, faster,” said Prof. Ran El-Yaniv, Deci’s chief scientist and co-founder. “With Deci’s platform, teams no longer need to compromise either accuracy or inference speed, and achieve the optimal balance between these conflicting factors by easily applying Deci’s advanced optimization techniques”. Deci’s model was submitted under the offline scenario in MLPerf’s open division in the BERT 99.9 category. The goal was to maximize throughput while keeping the accuracy within a 0.1% margin of error from the baseline, which is 90.874 F1 (SQUAD).
AI Inference Efficiency Translates into Bottom Line Results
For the submission, Deci leveraged its deep learning development platform powered by its proprietary AutoNAC engine. The AutoNAC engine empowers teams to develop hardware aware model architectures tailored for reaching specific performance targets on their inference hardware. Models built and deployed with Deci typically deliver up to 10X increase in inference performance with comparable or higher accuracy relative to state of the art open source models. This increase in speed translates into a better user experience and a significant reduction in inference compute costs.
In this case, AutoNAC was used by Deci to generate model architectures tailored for various NVIDIA accelerators and presented unparalleled performance on the NVIDIA A30 GPU, NVIDIA A100 GPU (1 & 8 unit configurations), and the NVIDIA H100 GPU.
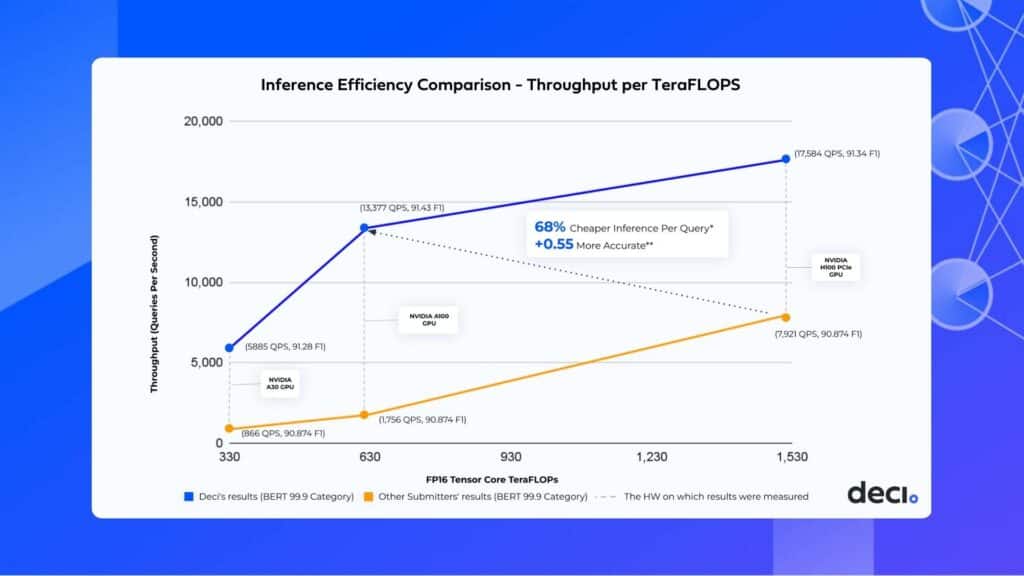
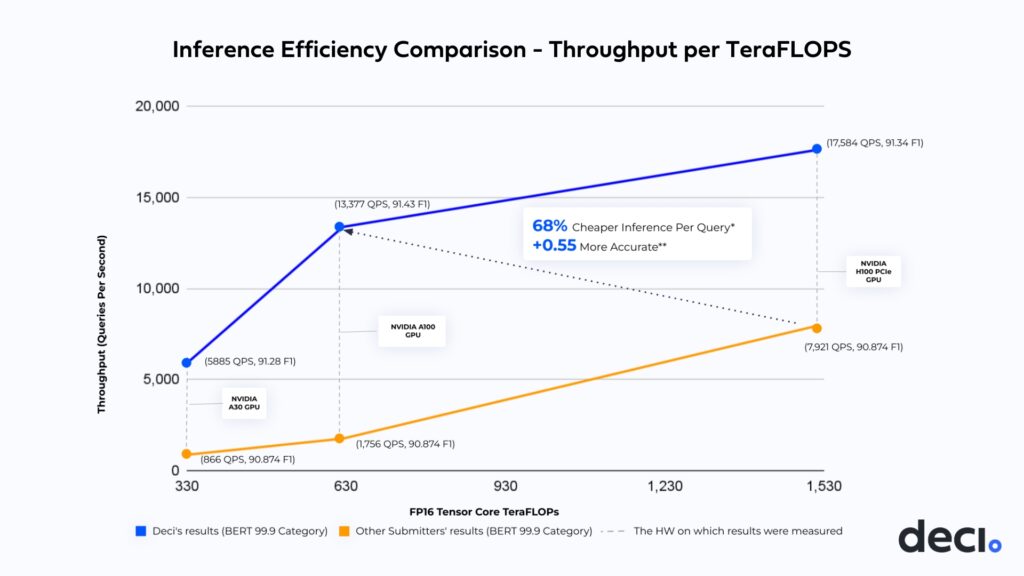
The below chart illustrates the throughput performance per TeraFLOPs as achieved by Deci and other submitters within the same category. Deci delivered the highest throughput per TeraFLOPs while also improving the accuracy. This inference efficiency translates into significant cost savings on compute power and a better user experience. Instead of relying on more expensive hardware, teams using Deci can now run inference on NVIDIA’s A100 GPU, achieving 1.7x faster throughput and +0.55 better F1 accuracy, compared to when running on NVIDIA’s H100 GPU. This means a 68%* cost savings per inference query.
*Inference cost savings are calculated per 1 million queries on NVIDIA A100 GPU & NVIDIA H100 GPU (PCIe) based on an hourly, on-demand rate.
** Under the open submission rules, submitters aim to maximize throughput performance while keeping the accuracy within a 0.1% margin of error from the baseline accuracy of 90.874. Deci delivered a 91.43 F1 accuracy.
Other benefits of Deci’s results include the ability to migrate from multi-gpu to a single GPU and lower inference cost and reduced engineering efforts. For example, ML engineers using Deci can achieve a higher throughput on one H100 card than on 8 NVIDIA A100 cards combined. In other words, with Deci, teams can replace 8 NVIDIA A100 cards with just one NVIDIA H100 card, while getting higher throughput and better accuracy (+0.47 F1).
On the NVIDIA A30 GPU, which is a more affordable GPU, Deci delivered accelerated throughput and a 0.4% increase in F1 accuracy compared to an FP32 baseline.
By using Deci, teams that previously needed to run on an NVIDIA A100 GPU can now migrate their workloads to the NVIDIA A30 GPU and achieve 3x better performance then they previously had for roughly a third of the compute price. This means dramatically better performance for significantly less inference cloud cost.
| Hardware | Other Submitters’ Throughput | Deci’s Throughput | BERT F1 Accuracy | Deci Optimized F1 Accuracy | Accuracy Increase |
| NVIDIA A30 GPU | 866 | 5,885 | 90.874 | 91.281 | 0.4076 |
| NVIDIA A100 GPU, 80GB | 1,756 | 13,377 | 90.874 | 91.430 | 0.5560 |
| 8 x NVIDIA A100 GPU | 13,967 | 103,053 | 90.874 | 91.430 | 0.5560 |
| NVIDIA H100 PCIe GPU | 7,921 | 17,584 | 90.874 | 91.346 | 0.4722 |
Recently, Deci launched a new version of its deep learning platform, supporting generative AI model optimization and continuing to help developers further simplify the AI lifecycle.
This announcement was originally published on Cision PRWeb.