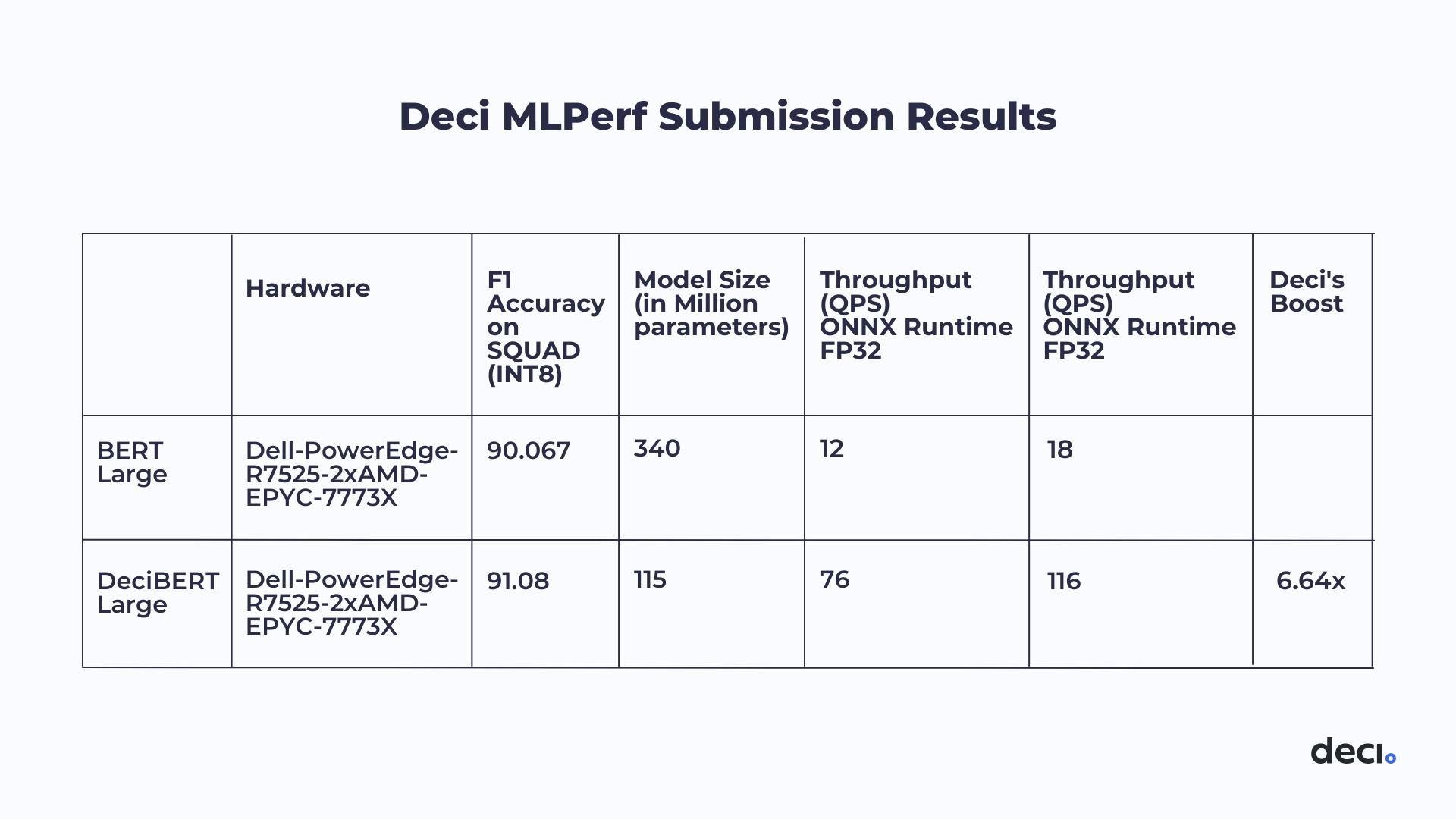
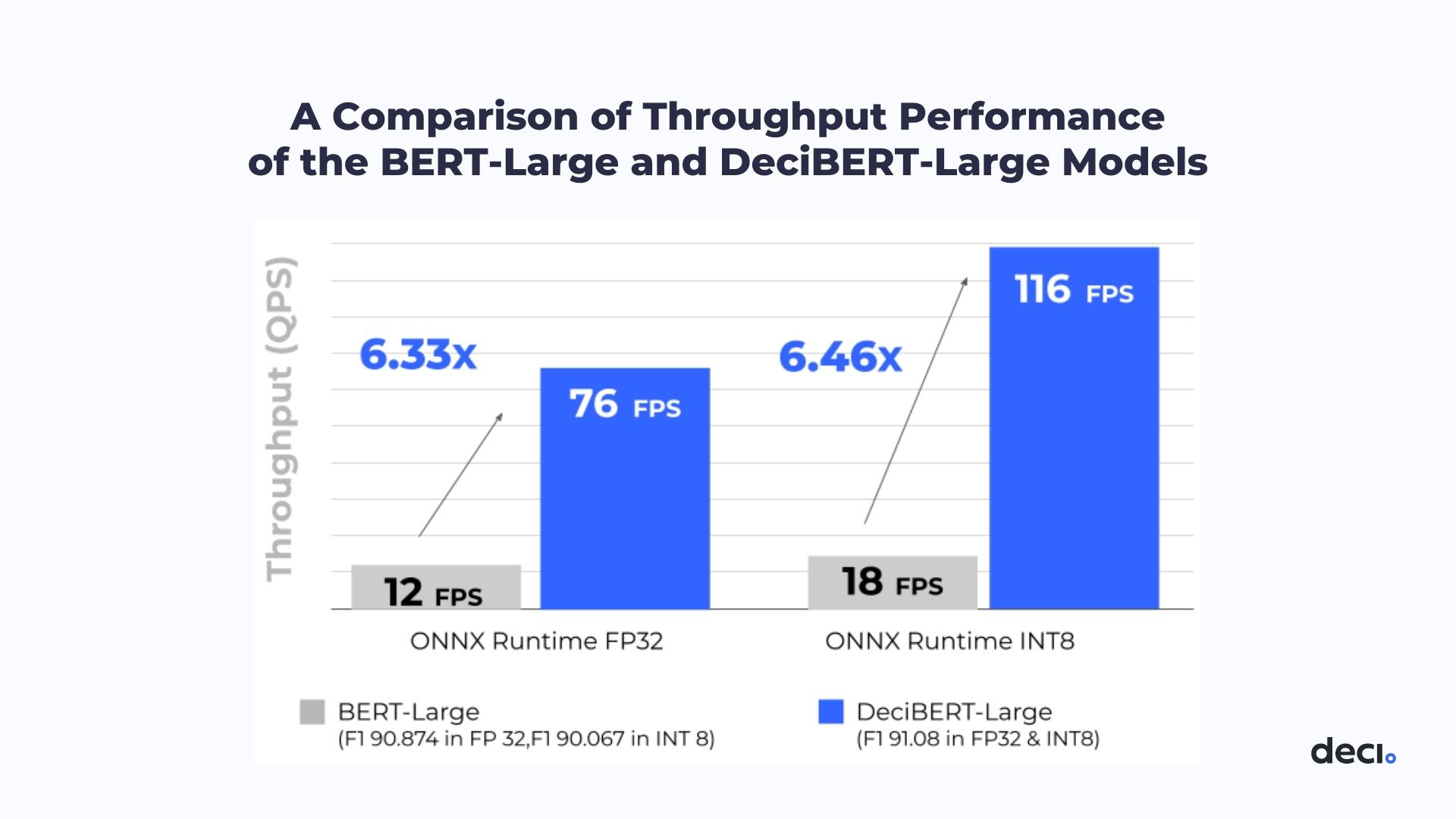
DeciBERT-Large substantially improved throughput performance & accuracy while also significantly reducing model size
Tel Aviv, Israel, September 8, 2022 – Deci, the deep learning company harnessing Artificial Intelligence (AI) to build better AI, announced results for its Natural Language Processing (NLP) inference model submitted to the MLPerf Inference v2.1 benchmark suite under the open submission track. Generated by Deci’s Automated Neural Architecture Construction (AutoNAC) technology, the NLP model, dubbed DeciBERT-Large, ran on Dell-PowerEdge-R7525-2 hardware using the AMD-EPYC-7773X processor. The resulting model outperformed both the throughput performance of the BERT-Large model by 6.46x and achieved a 1% boost in accuracy.
The model was submitted under the offline scenario in MLPerf’s open division in the BERT 99.9 category. The goal was to maximize throughput while keeping the accuracy within a 0.1% margin of error from the baseline, which is 90.874 F1 (SQUAD). The DeciBERT-Large model far exceeded these goals, reaching a throughput of 116 QueriesPer Second (QPS) and an F1 score of 91.08 for accuracy.
“While the key optimization objective when generating the DeciBERT model was to optimize throughput, AutoNAC also managed to significantly reduce the model size – an important accomplishment with a number of benefits including the ability to run multiple models on the same server and better utilize cache memory.” – Prof. Ran El-Yaniv, Deci’s chief scientist and co-founder of Deci
For the submission, Deci leveraged its proprietary automated Neural Architecture Construction technology (AutoNAC) engine to generate a new model architecture tailored for the AMD processor. AutoNAC, an algorithmic optimization engine generating best-in-class deep learning model architectures for any task, data set, and inference hardware, typically powers up to a 5X increase in inference performance with comparable or higher accuracy relative to state-of-the-art neural models.
“While the key optimization objective when generating the DeciBERT model was to optimize throughput, AutoNAC also managed to significantly reduce the model size – an important accomplishment with a number of benefits including the ability to run multiple models on the same server and better utilize cache memory,” said Prof. Ran El-Yaniv, Deci’s chief scientist and co-founder. “These results confirm once again the exceptional performance of our AutoNAC technology, which is applicable to nearly any deep learning domain and inference hardware”.
MLPerf gathers expert deep learning leaders to build fair and useful benchmarks for measuring training and inference performance of ML hardware, software, and services.
The Impact of Faster NLP Inference
Deci’s NLP inference acceleration directly translates into cloud cost reduction as it enables more processes to run on the same machine in less time or alternatively it enables teams to use a more cost efficient machine while retaining the same throughput performance. For some NLP applications such as question answering, higher throughput also means better user experience as the queries are processed faster and insights can be generated in real time.
This announcement was originally published on Cision PRWeb.