Get access to Deci’s ultra-performant, NAS generated foundation models.
Simplify and shorten dev process. Accelerate inference and deploy to production in no time.
Get access to Deci’s ultra-performant, NAS generated foundation models.
Ideal for cost efficiency at scale and for handling sensitive data.
For developers looking to accelerate inference and deploy to production in no time.
For deep learning teams looking to achieve better than SOTA accuracy & inference performance.
For deep learning experts looking to meet specific performance goals for highly customized use cases.
Hardware Benchmarking
Compilation & Post Training Quantization (FP16 / INT8)
Inference Engine
AutoNAC Engine Runs
Quantization Aware Training
Supported
Supported Frameworks
Support
Legal Terms
A wide range of hardware including edge devices
Standard
Support Team / 24 hours
Standard
A wide range of hardware including edge devices
Standard
Dedicated DL expert / 12 hours
Standard
Any hardware
Any framework
Dedicated DL expert / custom SLA
Custom
“Using Deci, we swiftly developed a model that enabled us to expand our offering and further scale our solution on existing CPU infrastructure with significant cost-efficiency.”


“Controlling our inference cloud spend without compromising on performance is key for our business success. Deci enabled us to scale our workloads while reducing costs and improving our users’ experience.”

“At Adobe, we deliver excellent AI-based solutions across a wide range of cloud and edge environments. By using Deci, we significantly shortened our time to market and transitioned inference workloads from cloud to edge devices. As a result we improved the user experience and dramatically reduced our spend on cloud inference cost.”


“Our advanced text to videos solution is powered by proprietary and complex generative AI algorithms. Deci allows us to reduce our cloud computing cost and improve our user experience with faster time to video by accelerating our models’ inference performance and maximizing GPU utilization on the cloud.”

“Applied Materials is at the forefront of materials engineering solutions and leverages AI to deliver best-in-class products. We have been working with Deci on optimizing the performance of our AI model, and managed to reduce its GPU inference time by 33%. This was done on an architecture that was already optimized. We will continue using the Deci platform to build more powerful AI models to increase our inspection and production capacity with better accuracy and higher throughput.”

“Deci delivers optimized deep learning inference on Intel processors as highlighted in MLPerf, allowing our customers to meet performance SLAs, reduce cost, decrease time to deployment, and gives them the ability to effectively scale.”

“At RingCentral, we strive to provide our customers with the best AI-based experiences. With Deci’s platform, we were able to exceed our deep learning performance goals while shortening our development cycles. Working with Deci allows us to launch superior products faster.”

“By collaborating with Deci, we aim to help our customers accelerate AI innovation and deploy AI solutions everywhere using our industry-leading platforms, from data centers to edge systems that accelerate high-throughput inference.”

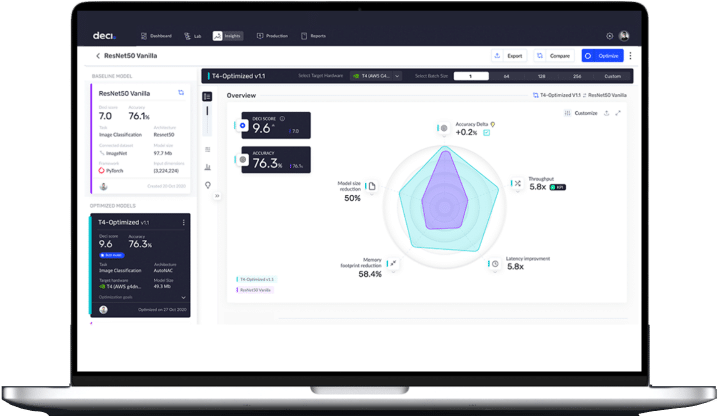
With Deci’s deep learning development platform, developers can accelerate inference performance by up to 5x, for any hardware, without compromising accuracy; cut up to 80% on compute costs; and reduce time-to-production of models.

Selected as one of the top 100 AI startups in the world
Recognized as a tech innovator for edge AI

Achieved 11.8x acceleration in collaboration with Intel

Recognized as a tech innovator for edge AI
Yes, the Basic, Professional, and Enterprise Plans are all annual subscriptions.
Absolutely. The basic plan allows you to quickly start optimizing your deep learning models. You can upgrade your plan at any time by contacting us.
AutoNAC, short for Automated Neural Architecture Construction, is Deci’s proprietary optimization technology. It is a Neural Architecture Search (NAS) algorithm that provides you with end-to-end accuracy-preserving hardware-aware inference acceleration. AutoNAC considers and leverages all components in the inference stack, including compilers, pruning, and quantization.
Deci’s deep learning development platform enables you to push models from the Deci Lab, optimized or not, directly to our inference engine for seamless deployment and ultra-fast serving. Quickly run inference on your models with Infery, a Python inference runtime engine that simplifies deep learning model inference across multiple frameworks and hardware using only 3 lines of code.
Absolutely. You can easily integrate Deci’s deep learning acceleration platform using our API access. Read more about our API access.


Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")