Optimize Your Models to maximize the utilization of any cloud instance, and gain Cost Efficient Inference at Scale without compromising accuracy.

Stop relying on expensive cloud instances to support your applications’ inference at the cost of product profitability. With Deci, you can boost your models’ performance and maximize hardware utilization to cut down inference time and cost.
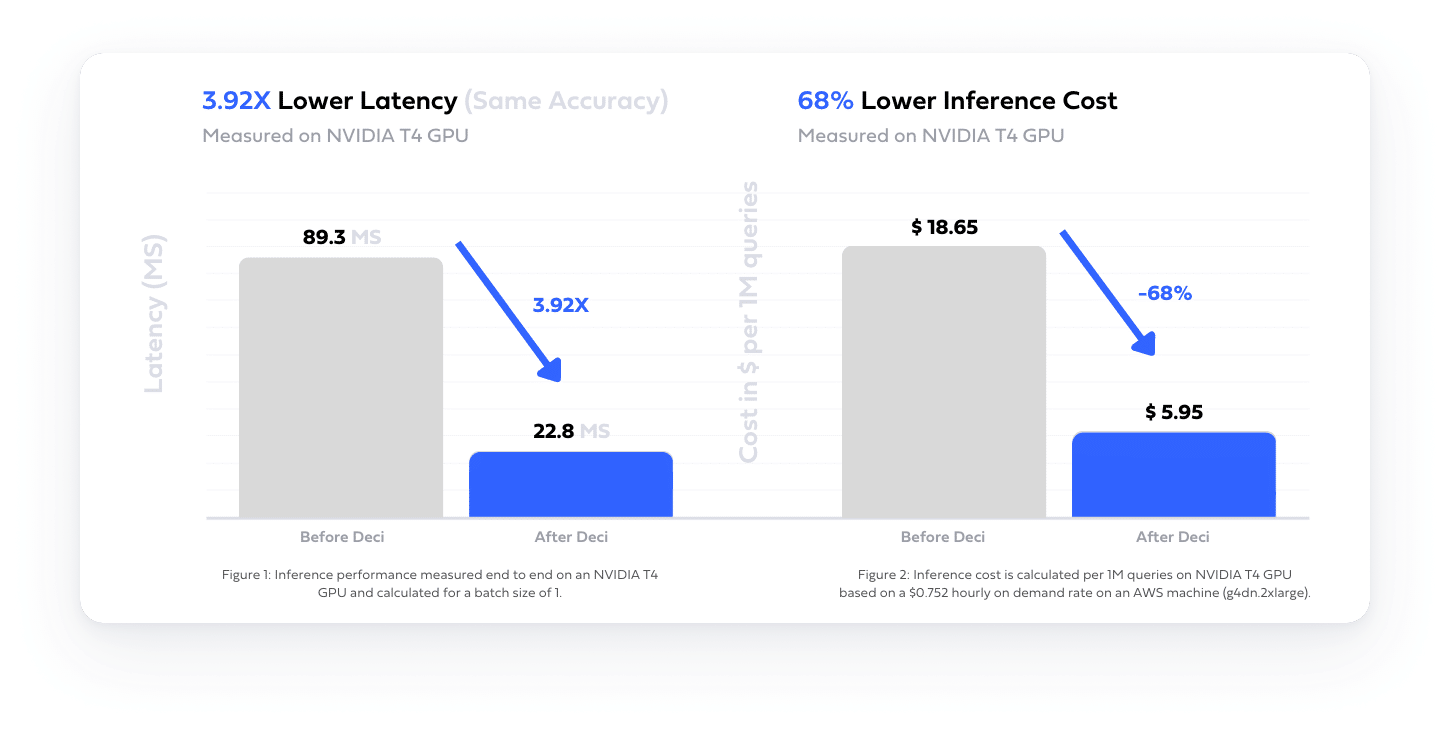
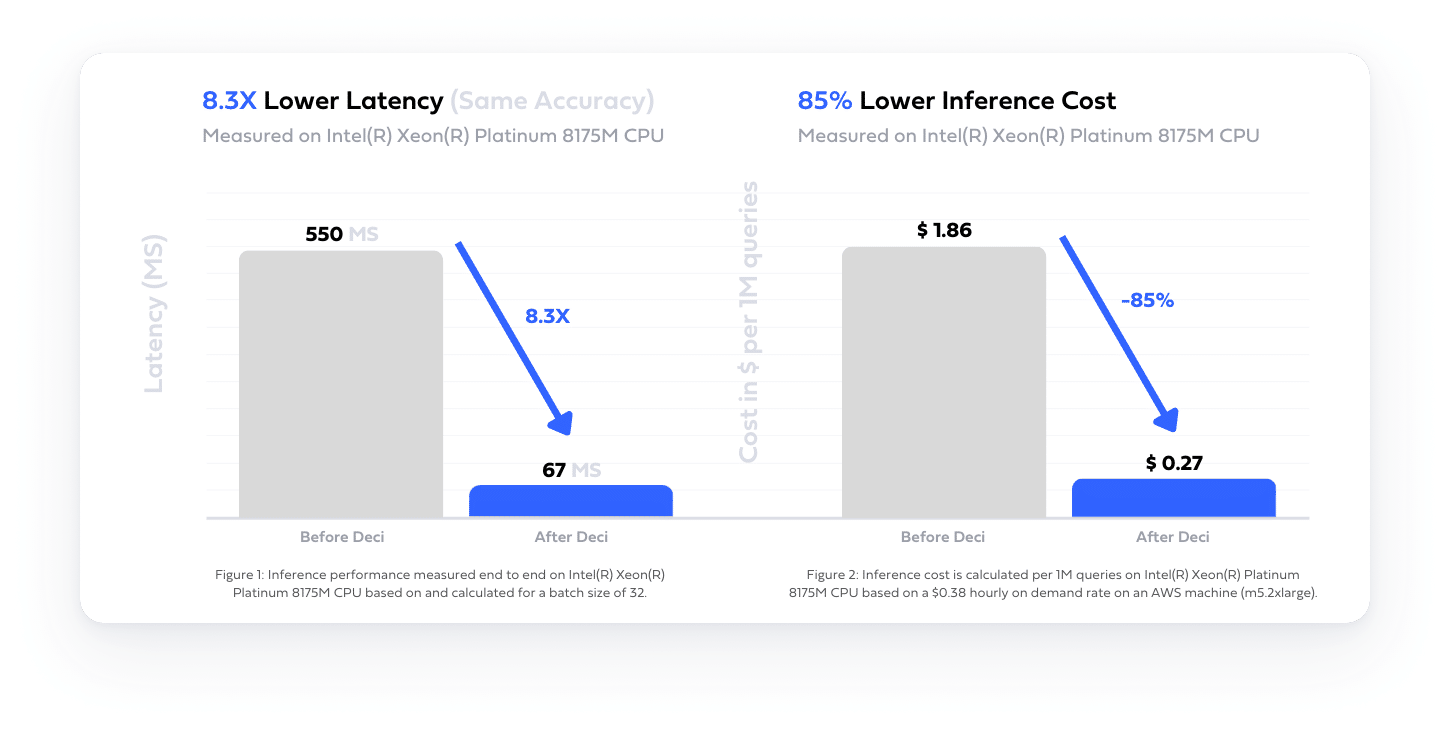
Average reduction in Inference Cloud Cost
Boost in Model Accuracy
Average Throughput Acceleration
Average reduction in Model Size

Daniel Shichman, CEO
WSC Sports Technologies

Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")



