

The ongoing collaboration between Intel Corp. and Deci AI has already achieved two milestones. The first was a joint submission to MLperf and the latest is the acceleration of three off-the-shelf models: ResNet-50, ResNeXt101, and SSD MobileNet V1.
The ML-perf submission, which we previously covered, demonstrated the incredible acceleration of the ResNet-50 model by up to 11.8x on several CPUs[*]. This post describes the second milestone, which leveraged both Deci and Intel core technologies to successfully boost the throughput of three off-the-shelf neural models by up to 3.7x1.
The objective of this second milestone was to accelerate ResNet-50, ResNeXt101, and SSD MobileNetV1 on two Intel CPU cores: the Intel Core i5-7260U and the Intel Core i7-1065G7. These cores are of special interest because they are used for many different small edge devices. Since we already tackled image classification in the MLPerf submission, the added task here was object detection (SSD MobileNetV1), which is significantly more challenging. ResNeXt101, one of our target architectures, is considerably larger and more accurate than ResNet-50. ResNeXt101 has 84M parameters with 78.1% top-1 accuracy on ImageNet, while ResNet-50 has 25.6M parameters with 75.3% top-1 accuracy.
As a first step, we applied Deci’s AutoNAC optimization on the target models. The AutoNAC receives as input a baseline model a0, a dataset D, and access to the specific target hardware device H. It then performs a constrained optimization to find the optimal architecture a* that solves the objective:
a*=argmina∈A LatH,C,Q(a,D)
subject to : AccQ(a,D)≥0.99⋅Acc(a0,D),
where A is the set of all possible architectures in the search space, and LatH,C,Q(a ,D) is the latency of a given network a on data D over hardware H, compiler C, and quantization level Q. More details about Deci’s AutoNAC can be found in Deci’s white paper.
The next part of the optimization involved compiling the optimized AutoNAC model with Intel’s OpenVINO toolkit. This great toolkit by Intel, performs computation-graph optimization, 8-bit/ 16-bit quantization and graph restructuring, all of which enable additional acceleration over Deci’s AutoNAC optimization.
Results (as of August 2021)
We measured the results for the ResNet and ResNeXt classification models on the ImageNet dataset, and used the Microsoft-COCO dataset for the detection task. The model sizes were measured in megabytes, and we calculated throughput (measured by number of images per second) on a NUC PC2 for the i-5 core and on Dell PC3 for the i-7 core. As discussed above, all the optimized models were compiled with Intel’s OpenVINO 8-bit.

Table 1: Optimization results for the three models. For each model we present accuracy, model size in megabytes, and throughput (Thrpt) in images per second, for the two hardware (NUC for the core i-5 and Dell for the core i-7). *The model could not be compiled into 8-bit while preserving sufficient accuracy.
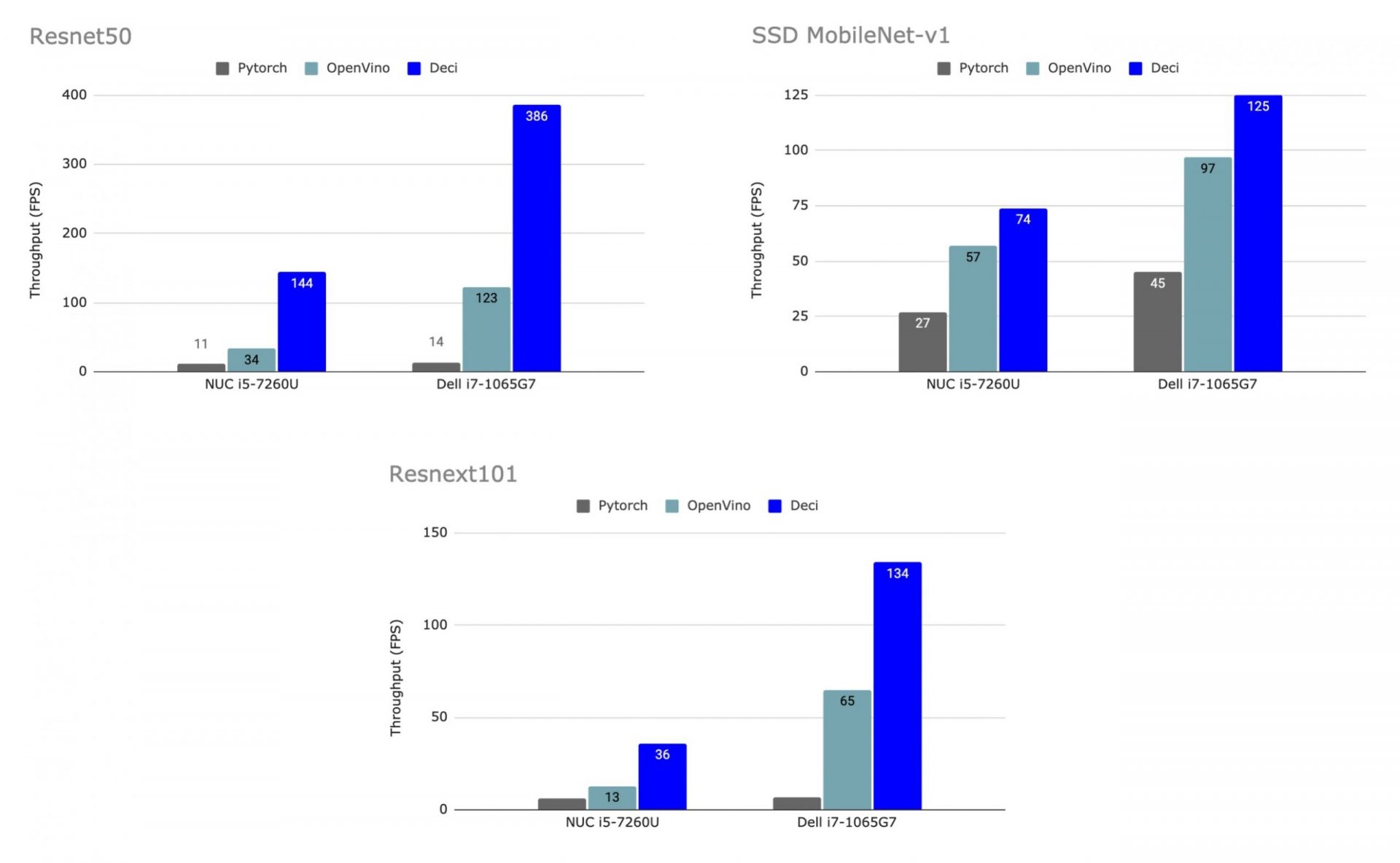
Figure 1: From left to right: Results of ResNet-50 ResNeXt101 and SSD MobileNetV1.
ResNet-50 – As can be seen in Table 1, AutoNAC successfully compressed the model by a factor of 4.4x over the 8-bit compilation, and by 23.1x relative to the PyTorch model. Moreover, AutoNAC boosted the throughput of the 8-bit model by 4.2x over the core i-5, and by 3.1x over the core i-7. It is worth noting that the AutoNAC engine completely changed the model’s backbone in this scenario.
ResNeXt101 – The model was compressed by a factor of 1.6x over the 8-bit model, and by 6.3x over the PyTorch model. For the core i-5, AutoNAC achieved a 2.8x throughput gain, while for the core i-7 case we boosted throughput by 2.1x. Remarkably, we also accelerated the model’s throughput by 19.1x relative to the vanilla PyTorch model. This is testimony to the enormous potential of algorithmic model acceleration.
SSD MobileNetV1– AutoNAC compressed the model by a factor of 1.7x over the vanilla OpenVINO model. Moreover, AutoNAC boosted throughput by a factor of 1.3x for the two types of hardware. We compared this model to the vanilla OpenVINO (16-bit) due to the difficulty of quantizing detection models to 8-bit while preserving accuracy, which is a well-known open problem in the industry.
Keep an eye out for quantization and hardware-aware optimization
We had some fascinating observations and insights that we’d like to share with you. Generally speaking, it is well known that some substitution exists between depth and width at least in terms of the expressiveness of the network. While running Deci’s AutoNAC engine to optimize different off-the-shelf models for different hardware, we saw a clear pattern. When the target hardware is GPU, AutoNAC tends to increase the width and decrease the depth. When the CPU is optimized, AutoNAC will usually decrease the width of the network.
1. Quantization is a powerful and significant technique. As can be seen in Figure 2, the 8-bit quantization computed by OpenVINO achieves striking results. It significantly speeds up throughput and compresses the model by a large factor, while almost fully preserving accuracy.
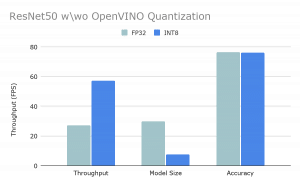
Figure 2: The effect of quantization on model size, throughput and accuracy
2. Being hardware aware is vital. It is crucial to choose a model that can be computed efficiently by the target hardware. A common wisdom in the industry is that it is sufficient to optimize models for the general families of AI chips such as GPUs, CPUs, etc. But, to really boost performance, you need to optimize for a particular chip. An example for this can be seen in Figure 3, which shows a comparison of three models on the two different hardwares, with similar CPUs. For the core i-7 machine, Model-1 has the highest throughput. However, this model has the lowest throughput on the core i-5.
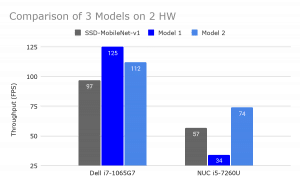
Figure 3: The importance of hardware-aware model optimization
The whole is greater than the sum of the parts.
Accelerating inference is a longstanding problem when it comes to real-world deep learning solutions.
Quantization alone delivers tremendous improvement in model performance, both in terms of throughput increase and model size reduction. That said, optimization that is hardware-aware and data-aware can deliver powerful incremental improvements as demonstrated in this experiment.
By combining quantization, computed by Intel’s OpenVino 1.3, and Deci’s powerful AutoNAC technology, we accelerated throughput for both detection and classification tasks by a large factor.
We would like to thank Guy Boudoukh from Intel-Labs Israel for driving the Intel-Deci collaboration and the joint work to prepare this blog.
1 Performance was compared to the original architectures on the same hardware
2 Specification: NUC7i5BNB Ubuntu 18.04. Intel (R) Core™ i5-7260U [email protected] fixed, GPU GT3e @0.95GHz fixed, DDR4/2133MHz.
3 Specification: ICL-U Ubuntu 18.04. Intel(R) Core™ i7-1065G7 [email protected] fixed, GPU G7, DDR4 2667MHz.
[*] MLPerf v0.7 Inference Open ResNet-v1.5 Single-stream, entry Inf-0.7-158-159,173; Retrieved from www.mlperf.org 21 October 2020
Configuration details: 1.4GHz 8th-generation Intel quad core i5 Macbook Pro 2019, 1 Intel Cascade Lake Core, and 8 Intel Cascade Lake Core









