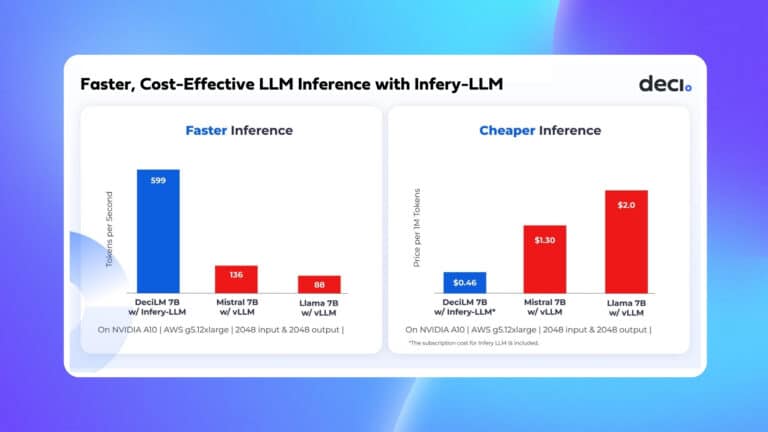
Our mission is to help AI developers easily build, optimize, and deploy deep learning models. As part of this mission, we developed Infery, a Python runtime engine that transforms running inference on optimized models into a light and easy process. It involves just three lines of code and supports major frameworks and hardware types. Imagine having the power of all frameworks at your fingertips with one friendly yet powerful API. That’s exactly what Infery is all about.
We took the best practices of all APIs and bundled them in a single, always-up-to-date Python library. It simplifies running inference for deep learning models–whether for quick experiments or for production purposes. In this post, you’ll learn about Infery: what makes it so exciting, what you can use it for, and how to get started using it right away.
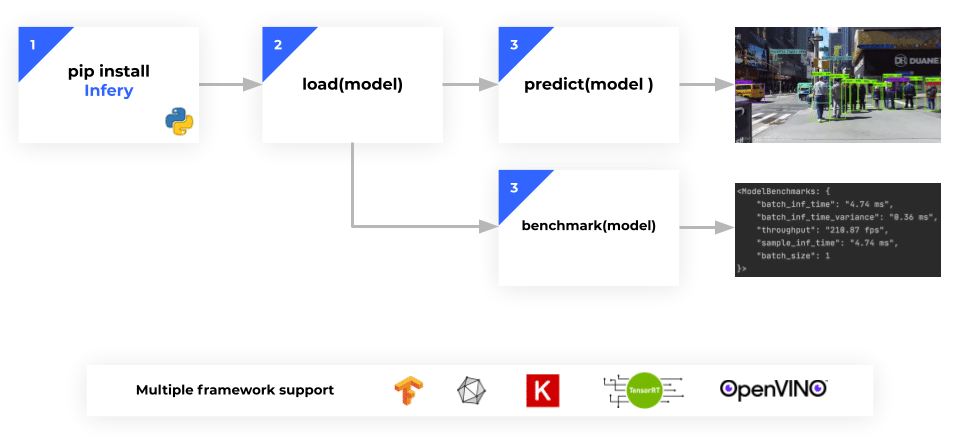
Figure 1: Infery is a Python runtime engine that lets you quickly run inference locally with only 3 simple commands. Infery supports all major deep learning frameworks with a unified and simple API.
Why Infery?
1. Support for multiple frameworks makes your life easier ⚡
Straightforward and unified API that simplifies your code –
- The constant evolution of deep learning frameworks and libraries means we often get bogged down trying to learn and integrate the APIs of different libraries. What’s more, error handling is not always user-friendly, leaving you in a situation where you don’t really understand what you did wrong or how to fix your code and move on.
Infery manages dependencies for you –
- Installing several deep learning libraries or runtimes together often results in a struggle with broken environments.
For example, to install Torch, ONNX and TensorFlow libraries together, developers need to hunt for the correct version of a mutual dependency, like NumPy, that will enable them to coexist in the same environment, without breaking or affecting other installed packages. - Infery’s versions are designed and tested to be installed successfully under multiple environments and edge cases. Whether it is an existing environment or a new one, Infery will make sure the installation is successful and that the versions were tested together. Infery’s distributions are optimized (the business logic is compiled into .dll/.so file), unleashing the best performance for your Python code.
No more headaches installing drivers –
- Python deep learning libraries require special drivers to work. Precompiled binary artifacts such as .whl files or C/C++ compiled drivers (.dll or .so files, etc.) can force you to use very specific versions of dependencies. Finding the right versions of packages and drivers that can coexist can take a lot of time.
- Infery’s installation makes this process as easy as possible, sometimes installing these drivers for you in a cross-platform solution, and reducing the installation and environment setup burden.
2. Works seamlessly with the Deci Lab model optimization ⚙️
Infery is a stand-alone library, but when coupled with the Deci Lab, you can optimize and deploy your models in a matter of minutes to boost inference performance on your preferred hardware, while maintaining the same accuracy. Once you optimize your model in the Deci Lab, only three simple copy-pastes separate you from running local inference for your optimized model.
“The classification model I uploaded and integrated using Infery achieved a 33% performance boost, which is very cool for 10 minutes of work!” – Amir Zait, Algorithm Developer, Sight Diagnostics
3. It’s super easy – only 3 lines of code ????
Why not give it a try?
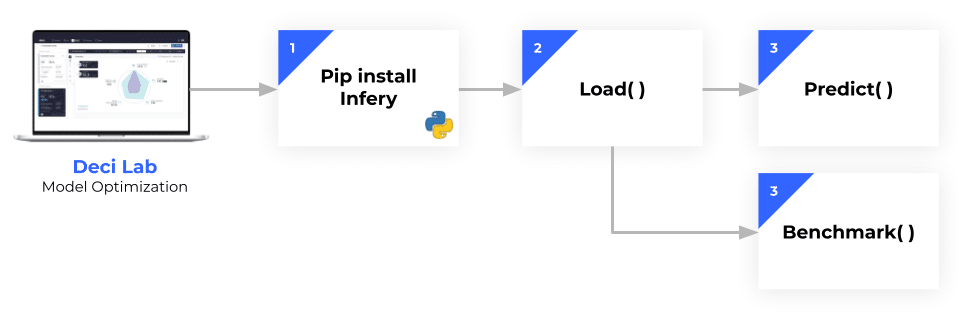
Figure 2: Coupled with the Deci Lab, you can optimize and run inference for your models in a matter of minutes–and gain a substantial boost in inference runtime performance, with the same model accuracy
What can Infery do for you?
Infery is a runtime Python library that is framework and hardware-agnostic. You can use it to easily run model inference on your hardware—whether the model is optimized or compiled with a graph compiler, or whether it’s a base vanilla version. Using Infery is much lighter and easier than installing a dedicated inference server.
Because Python is cross-platform, Infery can run on any environment that supports it such as Windows, Mac, or Linux. You can use Infery in various environment setups such as an edge server or a laptop, or on the cloud. Infery has two versions: one for GPU and one for CPU. Just keep in mind that if you’re using NVIDIA’s GPU, you’ll need to have the CUDA library installed.
With Infery, you’ll be leveraging an abstraction layer for inference across all popular frameworks. Infery has built-in support for multiple deep learning frameworks, including:
- TensorFlow
- Keras
- ONNX Runtime
- TorchScript
- Intel OpenVino
- NVIDIA TensorRT
You can find a list of dependencies and prerequisites at https://docs.deci.ai/infery/docs/quick_start/installation.html.
Infery has a very simple, robust, and unified API. Simply “pip install”, load(), predict() or benchmark() – and you’re good to go.
How to use Infery in 3 simple steps
Infery is all about being developer-friendly. This is accomplished thanks to its unified API, which is a combination of all the industry best-practices, simplified to the max. Another point is its error-handling interface, which tells you the error and what actions need to be taken to resolve the issue. For example, this might include changing the batch size because of the way the model is compiled.
Here’s the flow for working with Infery and why it’s so easy:
1. Load the model
First, you can check whether the model will load on certain hardware from a certain framework. Let’s say you have an OpenVino model that works on an Intel CPU, and you want to run inference on a MacBook. More often than not, an optimized model is hardware-aware, such that not every model can be loaded on any hardware.
For example, optimization on GPU often leverages the hardware architecture and memory, taking these factors into account when carrying out the compilation. Sometimes the GPU can’t load the model because of how it was compiled, or the way in which it was optimized for different hardware.
Infery checks and validates the compatibility of the model for certain hardware much faster. It lets you know whether you can load a model successfully on the type of machine that you prefer. And, if there are errors, it helps you understand exactly what you have to do next to progress.

Figure 3: Loading a TensorFlow 2.0 model with Infery
2. Run Inference
Infery lets you easily run inference for a model based on any of the major frameworks and on any hardware. For example, say you have a YOLO object detection model with an image that is already loaded in memory, and you want to run inference on this image. All you have to do is to run three lines of code, and you’ll get the output image with bounding boxes. There’s no need for any extra configuration file. You can optionally pre-process the image according to your needs, before calling model.predict().
What’s more, you can evaluate changes in inputs quickly and see how your model performs on different batch sizes of pictures and video streams. Sometimes, if the model supports dynamic input sizes (changing the input shape), you can measure the effect it has on the inference and the runtime.
As long as the framework is supported, and the model is valid and loaded, Infery will work. The task of the model doesn’t matter. Whether it’s computer vision, natural language processing, or voice recognition, Infery is a pure engineered framework that wraps the model for seamless inference.
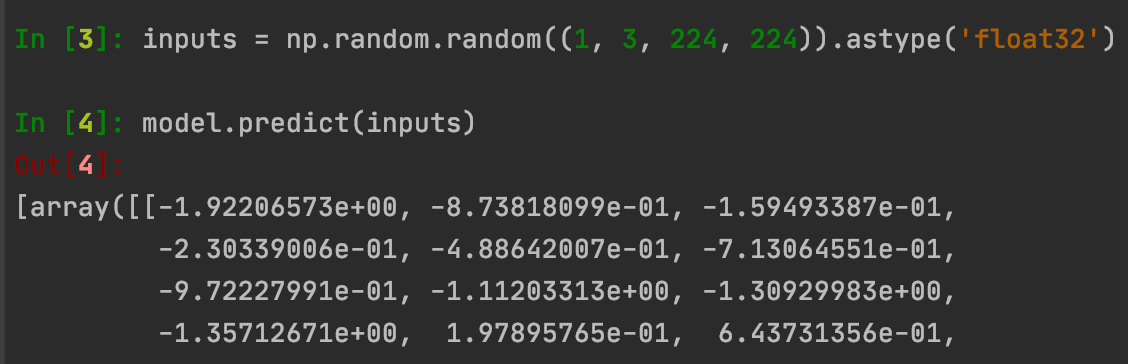
Figure 4: After loading a TensorFlow 2.0 model (previous section) simply run the predict() command to run inference on the model.
3. Benchmark the model
Benchmarking lets you understand the model’s true performance measurement on your hardware. To prevent incorrect measurements often caused by bugs, Infery provides an easy, out-of-the-box, interface to benchmark models.
All you have to do is enter a batch size and input dimensions. You’ll see that the benchmark changes significantly as you modify these factors.
Infery provides a unified and standard way to benchmark models consistently across your team.
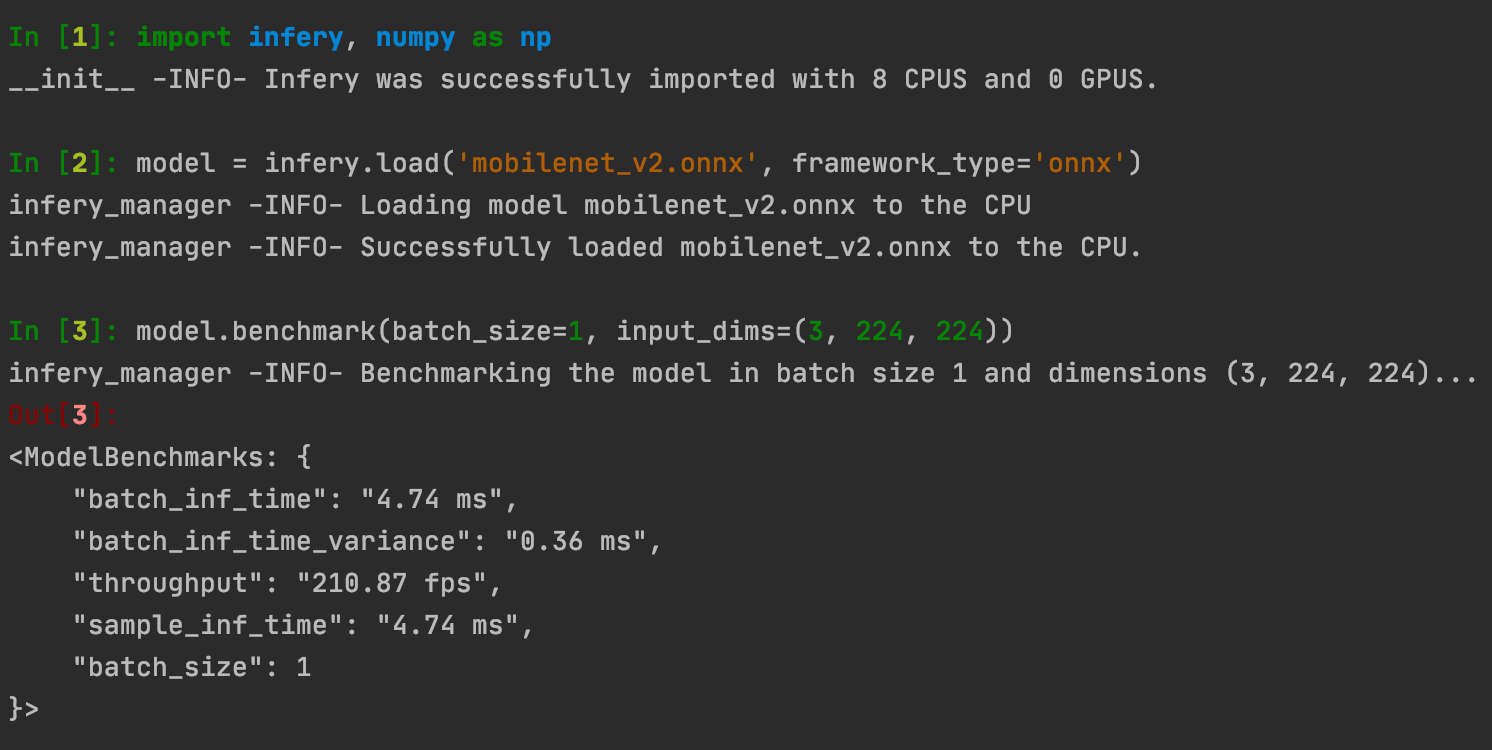
Figure 5: Code example for loading and benchmarking an ONNX model.
Why not get started now?
Infery is a great tool for deep learning practitioners at all levels of proficiency, from beginners to experts. It helps you run inference with minimum effort, no matter what model framework or hardware type. You don’t have to waste time learning APIs and hardware-related quirks — we’ve got you covered with a unified, simple, and up-to-date API.
To get started, just follow these steps:
- pip install infery OR pip install infery-gpu.
- Optimize your model with the Deci Lab. Infery is a standalone library but if you’re a user of the Deci platform, you can optimize your model’s inference performance while maintaining its accuracy. After that, you can simply download the model file that will work seamlessly with Infery.
- Run your optimized model with Infery! (Check out the documentation)
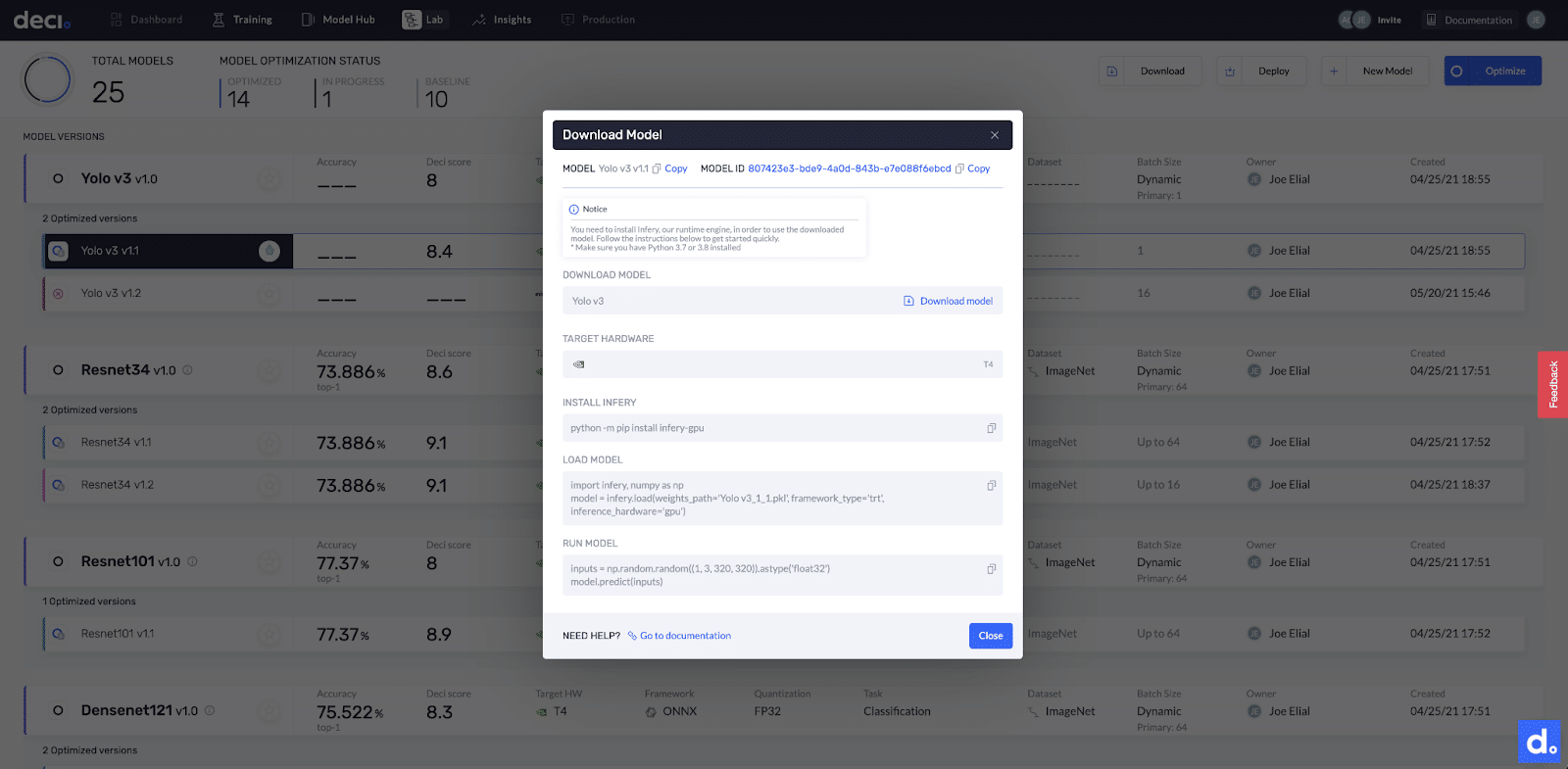
Figure 6: After optimizing your model with the Deci Lab, simply download the optimized model file and with 3 copy-pastes you are ready to run inference with Infery.
As frameworks and hardware ecosystems continue to evolve, we’ll support more frameworks and keep this library active and updated. With Infery, you’re guaranteed to be working with the most efficient code and with a vast support matrix.
Give Infery a try!