

Object detection is a key component of many deep learning models, and has undergone a number of revolutionary transformations in recent years. Object detection refers to the process of identifying objects in an image and extracting a bounding box for each object. These object detection algorithms are being used in applications for fields such as autonomous driving, security cameras, robotics, and almost any application that involves vision–including medical imaging or new trends like Amazon Go cashierless grocery store.
Over the years, the main challenge has revolved around the fact that many applications require object detection in real-time. Some of the newer implementations have faster inference and have allowed different areas of computer vision to develop and mature. Each new version improved upon the performance of its predecessor and we are now seeing the enablement of real-time object detection.
Despite the exciting advances, one of the biggest barriers in object detection is that the models are very large and heavy. It takes a lot of time and computing power to run them. The challenges in modeling object detection with deep learning are two-fold. First, since the size and number of the objects can vary, the network must be able to cope with this variability. Second, the number of possible combinations for bounding boxes is huge, and these networks tend to be computationally demanding. It has become a struggle to compute the output at real-time speed.
To understand this barrier, and perhaps what can be done to overcome it, we take a look at the different techniques available for object detection and how the field has matured through recent history. As you will see, there is no one model that is the fastest and most accurate. We have to deal with a tradeoff between speed and accuracy: some models that are faster achieve lower accuracy and vice versa. Let’s delve into the history a bit so you can understand where each model sits on this spectrum.
Basic types of object detection algorithms
There are a number of deep learning algorithms that solve the object detection problem. These object detectors have three main components:
- Backbone for extracting features from the image
- Feature network that takes features from the backbone and outputs features to represent the characteristics of the image
- Final (class/box) network that uses these features to predict the class and location of an object
Before we get too far, it’s important to mention how object detectors are evaluated. The two common evaluation metrics are intersection over union(IoU) and average precision (AP). The IoU is the overlap between ground truth bounding boxes and the predicted bounding boxes. It is computed as the area of intersection between the ground truth bounding boxes and predicted bounding boxes, divided by the area of their union. The resulting value is a number between 0 and 1. The higher the number, the higher the overlap. The average precision is the area under the precision-recall curve (AUC-PR). In some cases, you might see the metric defined as AP50, where the 50 subscript means that the average precision is computed at an IoU threshold of 50%. When the average precision is computed for many classes and their mean is taken, it is referred to as the mean average precision.
Now we’re ready to explore the more recent and common deep learning algorithms you can use for your next object detection project.
Region-based models
Region-based convolutional neural networks use a set of region proposals to detect objects. Faster R-CNN is the latest model in this family of object detector algorithms. It is a successor to R-CNN and Fast R-CNN. Let’s take a moment to consider these predecessors before taking a look at Faster R-CNN.
R-CNN
The R-CNN model works by combining convolutional neural networks for bottom-up region proposals to localize objects. R-CNN takes an image and extracts up to 2000 bottom-up region proposals. A region proposal is a location in which there is a high likelihood of finding the target objects. R-CNN then uses a large CNN to compute features for each proposed region. Next, it classifies each region using class-specific linear support vector machines (SVMs).

R-CNN Object detection system overview (Source)
R-CNN has a couple of drawbacks:
- Training uses a multi-stage pipeline that first obtains object proposals, fits an SVM to the ConvNet features, and finally learns the bounding box regressors. This multi-stage training is slower than single-stage training.
- Training uses deep networks that consume a lot of time and space. This means more time as well as more computational power.
- Object detection is slow because it performs a ConvNet forward pass for each object proposal.
Fast R-CNN
The Fast R-CNN is a ConvNet-based object detector that learns to classify object proposals. It then takes an image and the set of object proposals as input. The Fast R-CNN processes the image using convolutional and max-pooling layers, and generates a convolutional feature map. A region of interest pooling layer then uses max-pooling to extract a fixed-layer vector from each feature map for each region proposal.
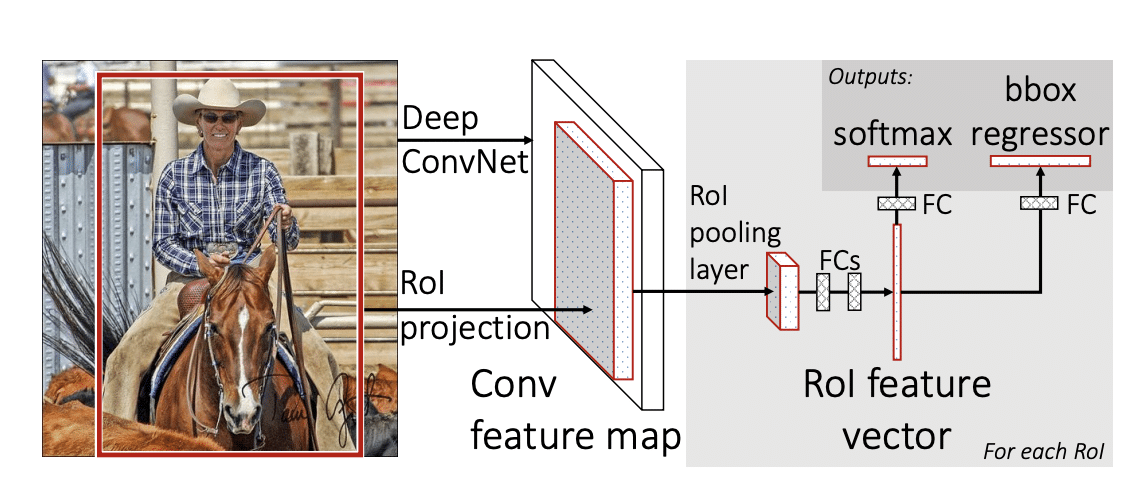
Fast R-CNN architecture (Source)
The feature vectors are then fed to fully connected layers, which branch into two outputs. One produces four values representing the object’s bounding box, while the other output is the softmax probabilities of the object classes. The bounding box numbers represent two numbers for the upper left and right, and two for the bottom side.
Fast R-CNN improves upon R-CNN. It has a higher mean average precision, it is a single training model, and it doesn’t require disk storage to cache its features.
Fast R-CNN
The Faster R-CNN model is made up of two modules:
- Deep convolutional network responsible for proposing the regions (Region Proposal Network)
- Fast R-CNN detector that uses the regions
The Region Proposal Network shares the full-image convolutional features with the object detection network. The object detection network then predicts the objects’ bounding boxes and scores. Next, the Fast R-CNN model uses the region proposals from the Regional Proposal Network for object detection. The Regional Proposal Network and Fast R-CNN are then merged into a single network by sharing their convolutional features. Generally speaking, the Faster R-CNN model receives an image and outputs rectangular object proposals. Each rectangle has an objectness score.

Faster R-CNN Network (Source)
The TensorFlow documentation provides a Faster R-CNN object detector API that you can use to build object detection models with minimal effort. You can also use the pre-trained Faster R-CNN models to run predictions immediately. TensorFlow provides the pre-trained models via TensorFlow Hub.
Single Shot Detector (SSD)
In this model, objects in an image are detected by one forwardpass. During the training stage, SSD uses input images and the ground truth bounding boxes for each object. The SSD predicts objects in the image using a single neural network. It uses a feed-forward convolutional neural network that produces bounding boxes and scores for the presence of objects. Convolutional feature layers enable the detection of objects at multiple scales.
SSD starts by evaluating a small set of default bounding boxes at different scales. The offsets of the shape and the confidence for categories are then predicted for each box. The default boxes are matched with ground truth boxes during training. Matching boxes are treated as positives, while non-matching ones are treated as negative. SSD, therefore, starts by producing a fixed set of bounding boxes via a feed-forward convolutional neural network. It then scores for the presence of objects in those boxes. The model’s loss is computed by weighting the localization loss and the confidence loss.

An SSD model (Source)
As with other object detection models, SSD uses a base model for feature extraction. It uses the VGG-16 network as the backbone network by default.
SSD is faster because it requires a single forwardpass. This is different from the Region Proposal Network, which requires two shots:
- One to generate the object proposals
- The other to detect objects from these proposals
On the VOC2007 dataset, SSD achieves a mean average precision score of 74.3% at 59 flops per second on an Nvidia TitanX.
There is a PyTorch implementation of SSD that you can use for your projects. The code is open source and available on Github.
YOLO Models
YOLO models are also single-shot models. The first YOLO model, short for You Only Look Once, was introduced in 2016. The original proposal was to predict bounding boxes and class probabilities from an image, in a single evaluation using a single neural network. This first model would process 45 frames per second in real-time using features from the entire image to predict bounding boxes.
The initial implementation of YOLO had two main challenges:
- It could only predict one class
- It didn’t perform well on small objects
Subsequent versions of YOLO have been aimed at overcoming these limitations and improving the performance of the models.

The YOLO object detection system (Source)
Let’s take a minute to look at more recent and popular versions of YOLO. We’ll get the ball rolling with YOLO version 4.
YOLO V4
YOLO V4 was proposed in 2020, and its official Darnet-based implementation is available on Github. The model’s network is made up of 24 convolutional layers and two fully-connected layers. The output of the network is a bounding box and its confidence score.
YOLO V4 consists of:
- CSPDarknet-53 backbone for feature extraction
- Spatial pyramid pooling (SPP) and path aggregation network(PAN) to collect features from different stages
- YOLO V3 head for predicting classes and bounding boxes
The object detector (Source)
Let’s take a closer look at these components.
CSPDarknet-53 is a convolutional neural network that is used as a backbone for object detectors. It is based on DarkNet-53, a convolutional neural network that uses residual connections and is the backbone for the third version of YOLO. CSPDarknet-53 uses a cross stage partial network (CSPNet) that partitions feature maps of the base layer into two parts. This partitioning reduces the computation time by merging the two parts.
SPP is a convolutional neural network architecture that uses spatial pyramid pooling to remove the fixed-size constraint of the network. The output of the SPP layers is fed to a fully-connected layer or other classifiers. The PANet is a network that pools features with the aim of reducing the distance among the lower and topmost feature levels for reliable information passing.
YOLO V4 introduces two new methodologies to increase accuracy:
- Bag of freebies – These are strategies that are applied to improve the performance of a model without increasing its latency at inference. One such strategy is data augmentation, whose goal is to expose the model to various images, hence making the model more robust. Photometric distortions and geometric distortions are two examples of augmentations on images that improve the object detector’s performance. Photometric distortions include adjusting contrast, hue, saturation, and brightness in images. Some geometric distortions that are applied to object detectors include random scaling, rotating, and cropping images.
- Bag of Specials – These are plugin modules and post-processing methods that increase the inference cost by a small amount while improving the object detector’s accuracy. The aim of the plugin modules is to enhance some model attributes such as enlarging the receptive field or strengthening feature integration capability. The post-processing methods are used to monitor the prediction results.
There are also several data augmentation strategies proposed by YOLO V4.
- CutOut – Combines images by cutting out part of one image and pasting it onto an augmented image
- Mosaic data augmentation – Mixes four training images. This enables the detection of objects outside their normal context.
- Self-Adversarial Training (SAT) – A new augmentation strategy that operates in two forward-backward stages. In the first stage, the network alters the original image instead of the network weights. The second stage involves training the neural network to identify an object in the altered image.
YOLO V4 achieves a 65.7% average precision(AP50 ) for the MS COCO dataset at a real-time speed of 65 frames per second on Tesla V100.
YOLO V5
A lot of controversies have arisen from the release of YOLO V5. Essentially, it is not a new YOLO version but an implementation of YOLO V4 in PyTorch. Another bone of contention with this version is that the developer did not release any paper that can be peer-reviewed. Alexey, one of the authors of YOLO V4, took a stab at this and responded to the release of YOLO V5. You can read his comments on this Github issue.
YOLO V5’s page on Github claims that this version is faster than previous YOLO versions. The page also provides pre-trained checkpoints that you can download and start using right away.
CenterNet
CenterNet is built upon the one-stage keypoint-based detector known as CornerNet. CornerNet produces heatmaps for the top-left corners and the bottom-right corners. The heatmaps are locations of key points for different objects. Each keypoint is assigned a confidence score.
CornerNet also generates embeddings that are used to determine whether two corners belong to the same object. It generates offsets that can be used to learn how to remap the corners from the heatmaps to the input image.
CenterNet is a one-stage detector that detects each object as a triplet of keypoints, resulting in improved precision and recall. It explores the central part of a proposal. The idea is that if a bounding box has a high intersection over union with the ground truth box, then there is a high probability that the center key point in its central region is predicted as the same class. At inference, a proposal is determined to be an object, based on whether there is a central key point of the same class that falls within the proposal’s central region. The determination is done after a proposal is generated as a pair of corner points.
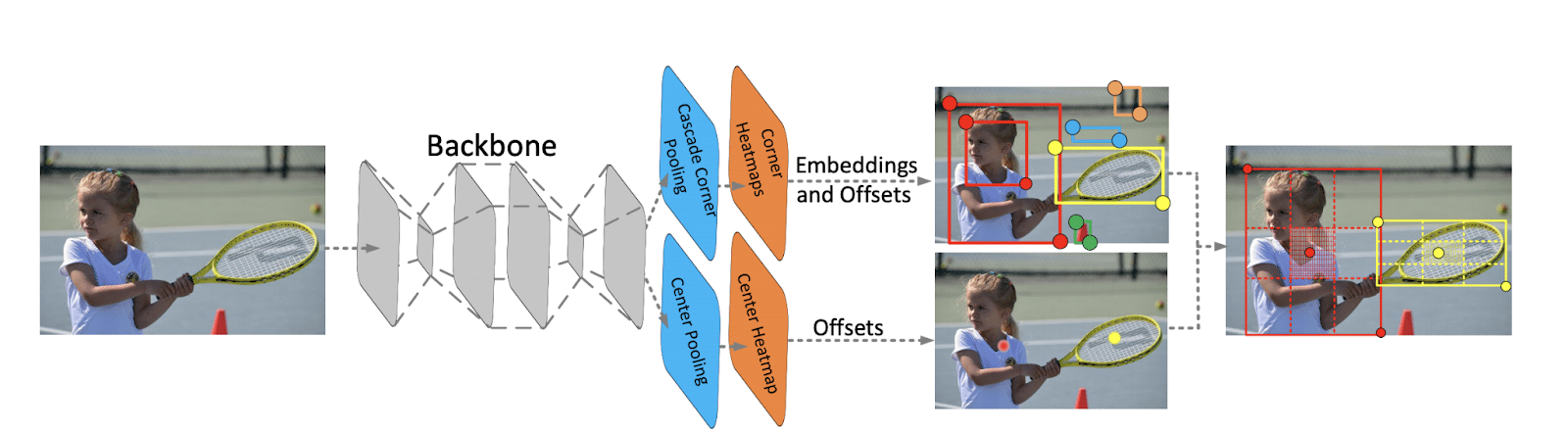
Architecture of CenterNet (Source)
CenterNet is made up of two modules: cascade corner pooling and center pooling. The center pooling module provides more recognizable information in the central regions, making it easier to determine the center of the region proposal. This module is responsible for predicting center keypoints. It uses the maximum values in both horizontal and vertical directions of the object to predict the center keypoints.
The cascade corner pooling module is responsible for enriching the information collected by both the top-left and bottom-right corners. Cascade corner pooling takes the maximum values in both boundary directions of the objects along with the internal directions of the objects to predict the corners.
CenterNet achieves an average precision of 47% on the MS-COCO dataset, a 4.9% increase compared to existing one-stage detectors.
EfficientDet
EfficientDet is an algorithm introduced by Google. It builds on EfficientNet and introduces a new bi-directional feature network (BiFPN) and new scaling rules. EfficientDet optimizes the components of the object detector to improve performance and efficiency. The optimizations result in small models that use less computation. These optimizations include:
- Employing EfficientNet for the backbone. Applying EfficientNet-B increases accuracy by 3% while reducing computation by 20%.
- Improving the efficiency of the feature networks. This is done using a bi-directional feature network (BiFPN) that allows information to flow top-down and bottom-up while using regular and efficient connections. BiFPN is a type of feature pyramid network that allows fast and easy multi-scale feature fusion. It uses regular and efficient connections to allow information to flow in both top-down and bottom-up directions.
- Improving efficiency further through a fast normalized fusion technique. The observation is that since images have different resolutions, they contribute unequally to the final output features. This is addressed by weighting each input and allowing the network to learn the importance of each input feature.
- Introduction of a new compound scaling method for object detectors that leads to better accuracy. This is done using a simple compound coefficient that jointly scales up all resolution/depth/width of backbone, BiFPN, and class/box network.
On the COCO dataset, EfficientDet-D7 achieves a mean average precision of 52.2.
Get started using these models
In this article, we covered various object detection algorithms alongside their technical implementations. You should now be more familiar with the latest models developed to address the challenges of their predecessors and improve their performance. The next step is to grab their code implementations on GitHub and start training your object detectors. You can also download the pre-trained models and start using them right-away. Or, just use the Deci platform to improve the inference performance of those models.









