
The customer sought to improve the latency of a person segmentation model (“Stacked-Hourglass”) which was trained on Face Synthetics, an animated dataset of facial images. The model powered a conference room application that was not achieving the targeted real time latency on their desired hardware, a Qualcomm® Snapdragon™ 888 board. The customer wanted to reduce the model’s latency to achieve the required performance while also preserving the model’s accuracy level.

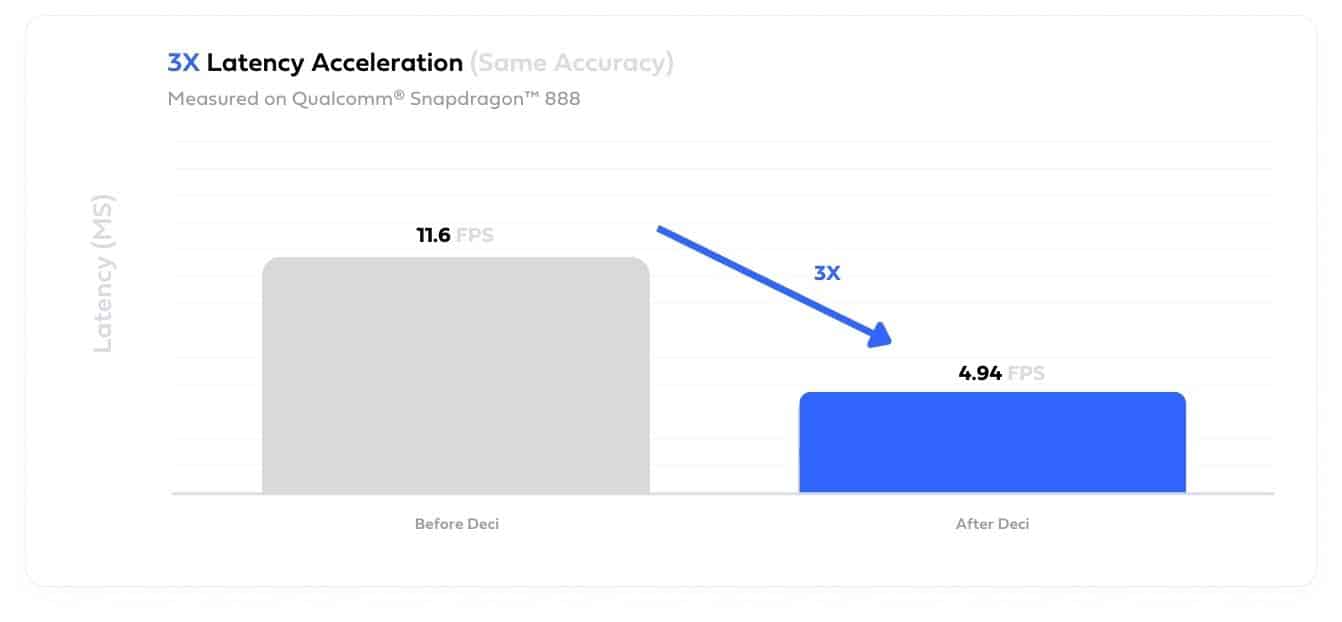
By leveraging the Deci platform the customer generated a custom model architecture that was tailored for the use case and the Qualcomm board. The new segmentation model reduced the latency by 3x from 11.6ms to 4.94 ms. In addition, the model file size was reduced by 4.47x and the memory footprint was reduced by 22%, all while preserving the original model accuracy.
Improve latency and throughput and reduce model size by up to 5X while maintaining the model’s accuracy.
Maximize hardware utilization and cost-efficiently scale your solution at the edge.
Eliminate inference cloud compute cost and avoid data privacy issues by running your models directly on edge devices.
Tell us about your use case, needs, goals, and the obstacles in your way. We’ll show you how you can use the Deci platform to overcome them.


Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")