
Computer vision (CV) is already transforming manufacturing processes, with numerous applications such as quality inspection, safety monitoring, defect detection, supply chain management, and more. Computer vision based solutions deliver the intelligence to simplify processes, drive new efficiencies, and empower faster decision-making. However, AI developers are still facing challenges in the development and deployment of such solutions. Inability to run real-time inference, high false alarms due to low model accuracy, and inability to deploy on CPUs or edge devices are just some of the barriers to production faced by AI teams today. With Deci, you can boost your models’ performance and maximize hardware utilization to deliver accurate and cost-efficient inference on cloud or edge devices. Below is a case study of a manufacturing solutions provider that was able to significantly improve its model’s accuracy and latency resulting in better inspection quality and scalable deployment on edge devices.
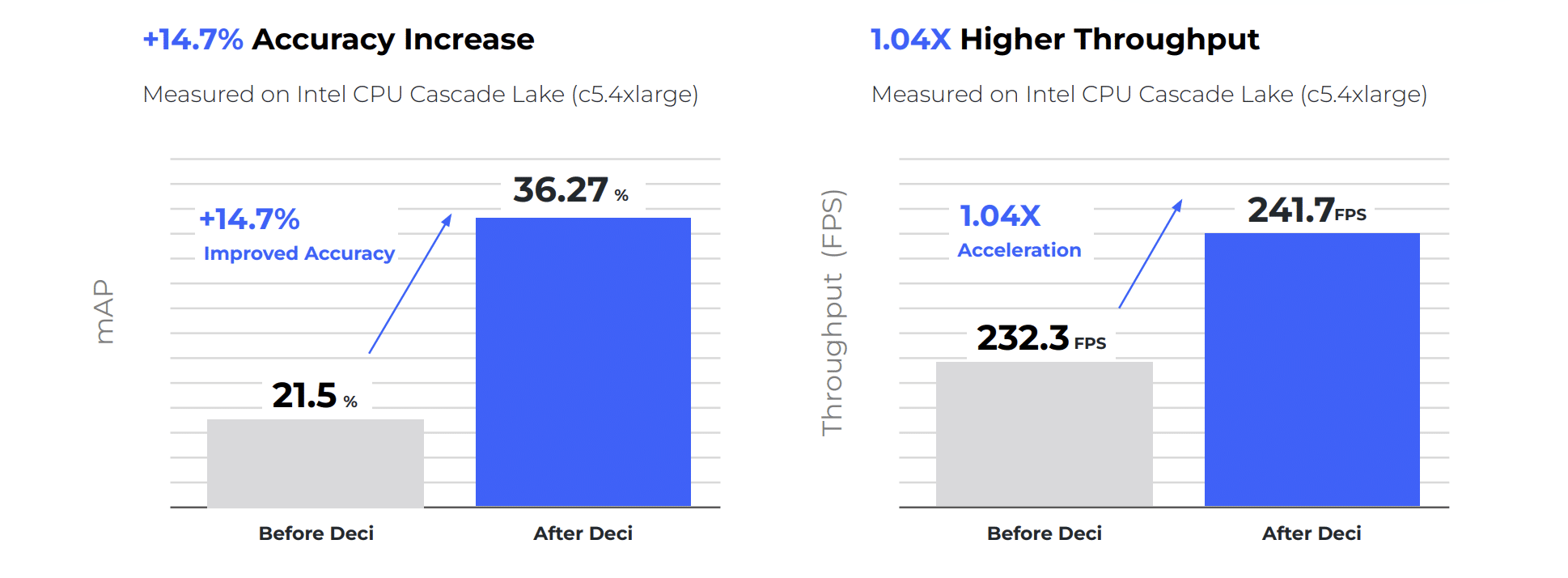
A company enabling manufacturers to digitally transform operations with a connected, IoT-native, no-code platform sought to enhance the safety personal protective equipment (PPE) identification offering of their platform by improving the model’s accuracy and latency on CPUs and other resource constrained edge devices. The company’s needed to deploy their models on a wide range of old generation CPUs such as Intel Cascade Lake CPU and Intel Tiger Lake CPU among others, in order to utilize existing server infrastructure. However, their object detection model was not achieving the desired accuracy and latency on such CPUs.
The team used the Deci platform and its Neural Architecture Search engine to develop a custom object detection model that delivered increased throughput and lower latency, while also significantly improving the accuracy. The company was able to deploy the model on a wide range of hardware environments and enhance its safety PPE identification solution. By using Deci the company minimized their development risk and effort and was able to expand its offering faster.
Improve latency and throughput, and reduce model size by up to 5x while maintaining or improving the model’s accuracy.
Make the most of your current hardware or move to one that’s more affordable. Enable inference on edge devices or cut up to 80% of your cloud compute costs.
Go from data to production in days. Automate model selection and optimization. Eliminate dev risks, guarantee success, and reach production faster.
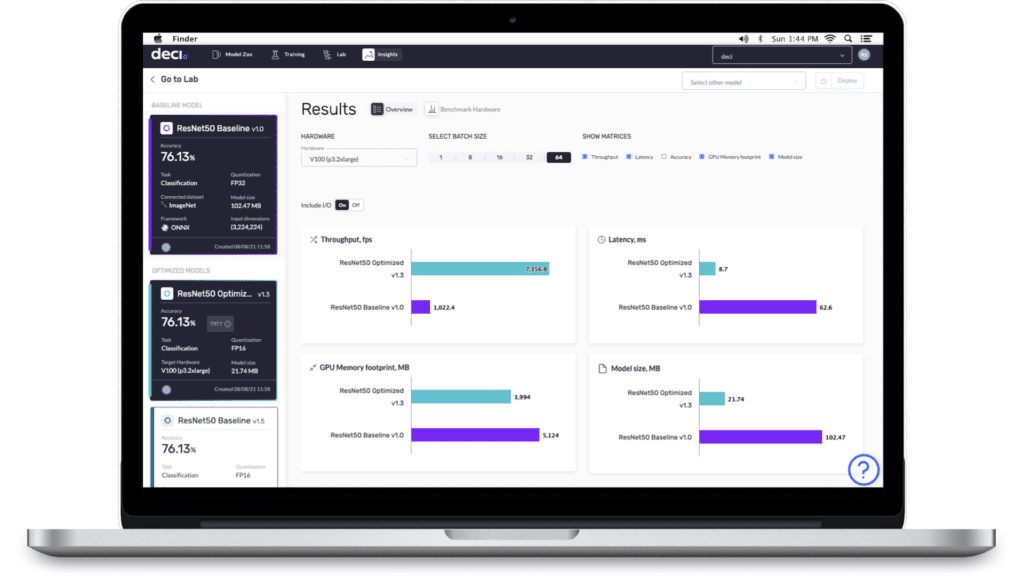
The Deci platform is used by data scientists and machine learning engineers to build, optimize, and deploy highly accurate and efficient models to production. Teams can easily develop production grade models and gain unparalleled accuracy and speed tailored for any performance targets and hardware environment. Deci is powered by AutoNAC (Automated Neural Architecture Construction), the most advanced and commercially scalable Neural Architecture Search engine in the market. AutoNAC performs a multi-constraints search to find the architecture that delivers the highest accuracy for any performance targets and hardware environment.
Build accurate & efficient architectures tailored to your hardware and application’s performance targets with Deci’s Neural Architecture Search engine (AutoNAC).
Train models with SuperGradients. Leverage custom recipes and advanced training techniques (e.g., knowledge distillation, quantization-aware training) with one line of code.
Easily compile and quantize your models (FP16/INT8) and evaluate different production settings with a click of a button.
Deploy your models with Infery, Deci’s simple-to-use, unified, model inference API. Streamline deployment and boost serving performance with parallelism and concurrent execution. Compatible with multiple frameworks and hardware types.
Easily measure and compare the performance of various models on your inference hardware.
Train models with SuperGradients. Leverage custom recipes and advanced training techniques (e.g., knowledge distillation, quantization-aware training) with one line of code.
Tell us about your use case, needs, goals, and the obstacles in your way. We’ll show you how you can use the Deci platform to overcome them.


Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")