

Deep neural networks can achieve state-of-the-art performance on many machine learning tasks. Unlike classical machine learning models, which are prone to overfitting when their size is increased, deep networks are often easier to train when very large and over-parameterized. As a result, today’s successful neural architectures tend to be very large–sometimes even huge–making them extremely slow and sluggish. In contrast, many commercial use cases call for very fast inference time. For example, machine vision applications demand real-time performance, with dozens of samples requiring inference every second. Many other applications rely on cloud inference computing, which can lead to overwhelming costs.
This inference computation barrier opens a massive gap between the success of neural networks and their ability to handle real-world scenarios. In this blog series, we overview different methods that bridge this gap. We dive into different deep learning acceleration schemes and focus on how model changes can accelerate the inference process, aka algorithmic acceleration. We’ll define the different concepts, highlight the pros and cons in each of them, and describe how this acceleration can be applied in practice. In this post, we begin by introducing the different components that play a role in inference computation, starting with the hardware itself. We then move on to graph compilers, compression techniques, and neural architecture search. We refer to all these computation elements as the acceleration stack.
The Inference Acceleration Stack
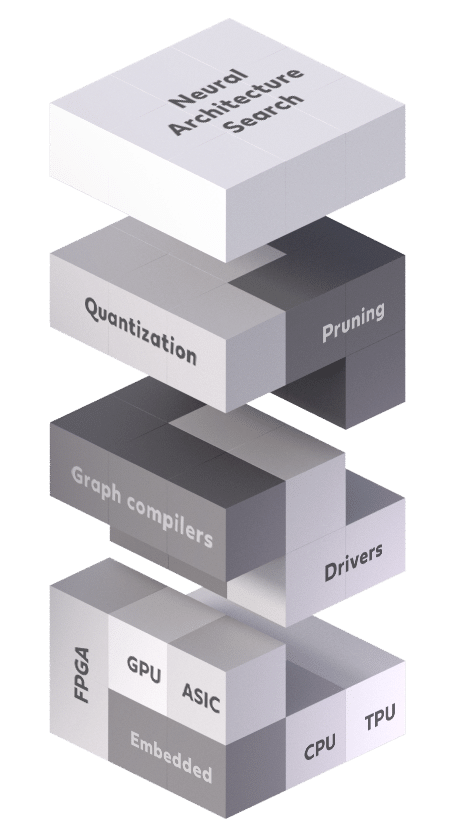
Figure 1: The inference acceleration stack
The acceleration stack, depicted in Figure 1, is composed of various levels and elements. At least one of these levels must be used to accelerate the inference process. By wisely employing several levels in conjunction, a significant speed-up can be achieved. As shown in Figure 2, the acceleration stack can be divided into three different types of levels: hardware, software, and algorithmic. Let’s take a closer look at each of the elements and see how they are incorporated in the acceleration stack.

Hardware devices are located at the lower level of the acceleration stack. These are the units that perform the computation, such as CPUs, GPUs, FPGAs, and some specialized ASIC accelerators like Google’s TPU. The acceleration technique here is clear: stronger computation units lead to faster deep learning inference. The hardware device is of paramount importance to the acceleration stack; for instance, a GPU can increase throughput by an order of magnitude over a CPU device. Notwithstanding, the speed-up from hardware devices is limited. As the well-known Moore’s law states, hardware capacity doubles itself every 1.8 to 2 years. That said, in the years between the 2012 launch of AlexNet and the 2018 introduction of Alpha-Go, the amount of computation needed by large AI systems has doubled itself every 3 to 4 months.
Software accelerators refer to any acceleration that is performed without changing the model itself. The software accelerator can be thought of as computer programs that translate the deep model’s computation graph into actual operations on the hardware device. Software accelerators can be divided into two types:
Low-level libraries that include cuDNN, MKL-DNN, and others. These libraries are generally used for GPU computation and provide highly-tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers that fully exploit the parallelism of the GPU.
Graph compilers include TVM, Tensor-RT, XLA OpenVino, and more. The graph compilers get a computation graph of a specific model and generate an optimized code adjusted for the particular target hardware. For example, they can optimize the graph structure by merging redundant operations, perform kernel auto-tuning, enhance memory reuse, prevent cache misses, etc.
The software acceleration methods are extremely efficient. They can sometimes accelerate inference time by a large factor and at others provide no acceleration whatsoever. Looking to the future, it is believed that software acceleration has its limit and further optimizations of this kind are expected to be incremental.
Algorithmic accelerators refer to any method that changes the model or architecture itself. Since neural networks often contain many redundancies, it is essential to exploit these redundancies to accelerate the inference process. The three most commonly used methods for this are:
Pruning is a relatively straightforward approach that prunes less important weights or filters from a trained model. It can compress the weights of shallow and simple networks, such as LeNet-5 and AlexNet, by an order of magnitude, without forfeiting accuracy. Other techniques, such as the Alternating Direction Method of Multipliers and end-to-end pruning, overcome the need for fine-tuning. However, filter pruning will reduce accuracy when it is used on deeper, more contemporary architectures. Weight pruning effectively removes connections between neurons, making the weight tensors sparser in an irregular manner but not smaller, offering only a minimal impact on latency.
Network quantization aims to substitute floating-point weights and/or activations with low precision compact representations. Extreme quantization, called binarization, constrains both the weights and activations to be binary numbers. Quantization can produce substantially smaller networks and more efficient computation, but it has its own challenges. Low bitwidth weights and activations result in information loss, distort the network representation, and circumvent the normal differentiation required for training. Several contemporary hardware inference accelerators already provide mixed precision quantization, which defines and applies different bit widths to each layer individually.
Neural architecture search (NAS) automates neural architecture engineering by selecting an appropriate architecture from a space of allowable architectures; it does this using a search strategy that depends on an objective evaluation scheme. NAS can produce outstanding results, but it’s incredibly challenging to implement effectively. A NAS search requires the evaluation of many architectures for their validation set performance; this demands a massive amount of computational power. Many ideas have been considered to reduce evaluation time, including low-fidelity performance estimation, weight inheritance, weight sharing, learning-curve extrapolation, network morphism, and single-shot training, which is one of the most popular options.
There is broad agreement that the future of deep learning acceleration lies in acceleration via architecture modifications. Many researchers are trying to find the golden formula to exploit the redundancies in neural networks. The main concern here is that reducing the model size usually comes at the cost of accuracy. Preventing significant deterioration in accuracy requires using a highly sophisticated method.
Deci’s Inference Acceleration
Now that we accurately defined the acceleration stack, it’s easier to explain what we really do. Deci’s platform has two acceleration modules: one is an algorithmic accelerator and the other is a software accelerator. Our software acceleration solution is called the Run-time Inference Container (RTiC). Our algorithmic solution is the Auto Neural Architecture Construction (AutoNAC) technology. Let’s dive into some details:
AutoNAC – Although the three components of the acceleration stack are complementary, each of them can be used independently to accelerate the inference process. Algorithmic acceleration does not generally take into account the other two components. Nevertheless, a significant gain can be achieved by exploiting the hidden dependency between the three. For example, when it comes to GPU, its parallelization power means that removing layers instead of filters will lead to a higher gain in inference time. For CPU, the opposite is usually the case. Another example, even more significant, is that different architectures are compiled differently, and the inference ratio between two architectures can flip after compilation. A model accelerator that is aware of the other levels in the acceleration stack is more amenable to accelerating deep learning inference.
Deci’s Auto Neural Architecture Construction was designed to solve this challenge. We use hardware- and compiler-aware NAS to fully utilize all levels in the acceleration stack. Our unique technology, which is incorporated in the Deci platform, can achieve this with only a negligible loss of accuracy. We have already achieved remarkable results in many use cases, which you are invited to read about in the Intel-Deci MLPerf submission and our white paper.
RTiC – Software accelerators are an important part of the stack. That’s why we built RTiC as part of the Deci platform. Deci’s RTiC is a containerized deep-learning runtime engine that lets you insert your models in a standardized inference server, ready for deployment and scaling in any environment. RTiC leverages best-of-breed graph compilers such as TensorRT or OpenVino while enjoying close-to-zero server latency overhead. With RTiC you can serve your DL models on any hardware and cloud with well-padded run-time surroundings, turning any model into a blazing fast inference server. Deploying your models through RTiC offers your data-scientists the flexibility to work in any framework while giving your DevOps team operational-transparency to the actual contents of the container.
Learn more about Deci’s platform
Conclusion
In this first post in our series about deep learning acceleration, we introduced the inference stack and discussed the inference acceleration techniques. We highlighted the importance of architecture accelerators and, specifically, the role different building blocks play in achieving maximal acceleration.
In our next posts, we’ll dive into the different components of the algorithmic acceleration scheme, define the related concepts, highlight their pros and cons, and describe how the scheme can be applied in practice. Stay tuned.
You can find the rest of the series below:
- An Introduction to the Inference Stack and Inference Acceleration Techniques – This!
- Hardware for Deep Learning Inference: How to Choose the Best One for Your Scenario
- Graph Compilers for Deep Learning: Definition, Pros & Cons, and Popular Examples








