
The demand for high-quality visual content continues to grow across industries. Visual Generative AI foundation models such as Latent or cascaded diffusion models, SAM and others, provide the ability to generate or customize realistic images. This is opening up new possibilities for many new applications. These foundation models have the potential to streamline and automate tasks that would otherwise require significant time and resources to complete manually.
BRIA provides engineers, AI teams, and researchers with safe and legal Visual Generative AI capabilities. With an access to trained models, source code, and comprehensive API suites, companies can enhance their products and services using BRIA’s Visual Generative AI Platform. BRIA’s solutions, having been trained on the world’s largest, fully licensed, high-quality training set, eliminate all legal risks for commercial enterprise use.
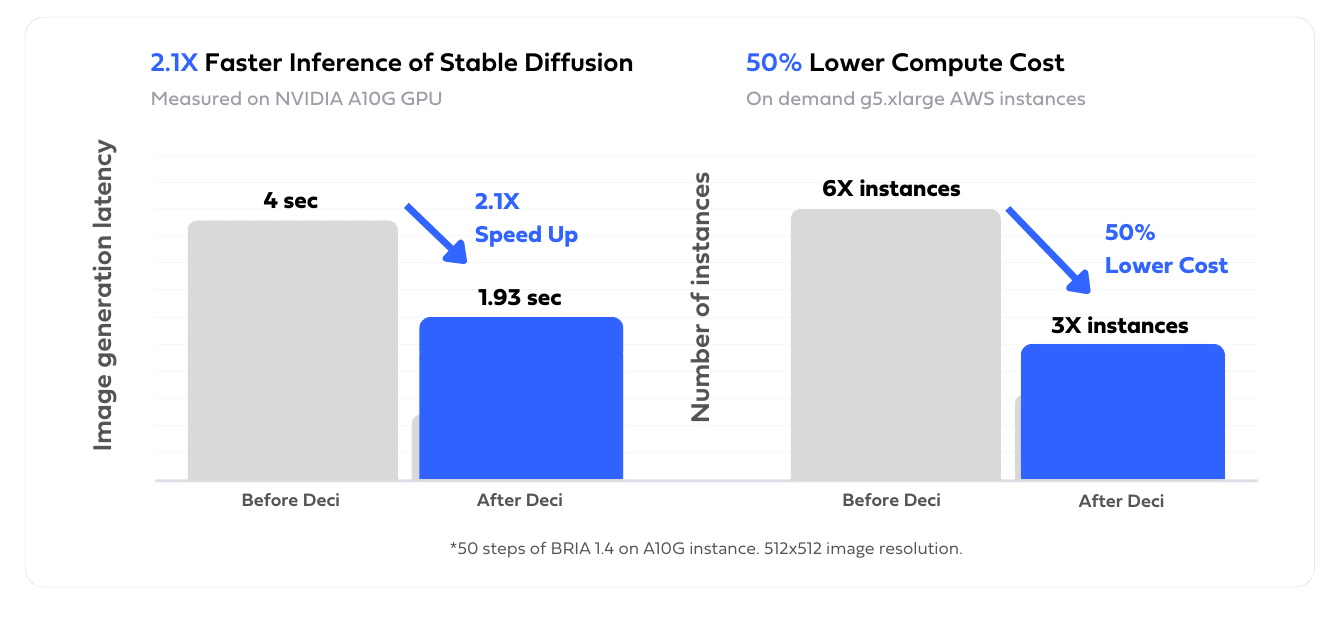
Cloud cost reduction is also a top priority for BRIA. Foundation models are larger and their inference process is more complex compared to classical AI models. To generate a new sample, a model performs several inference iterations. The combination of extremely large models and the iterative nature of the inference results in a significantly higher demand for compute power and overall inference costs. In order to run inference at a high scale, BRIA aims to reduce its cloud expenditure by optimizing inference time and increasing GPU utilization. Moreover, faster models are not only more cost-effective, but they also increase client satisfaction by reducing the latency of inference.
Using the Deci’s platform, BRIA’s team was able to optimize the inference performance of their BRIA 1.4 and Segment Anything models and reduce their inference cloud cost by 50%.
BRIA’s team used Deci’s Infery library to easily perform a hybrid compilation and selective quantization in their complex diffusers and transformers based architectures.
Infery automatically profiles the architecture’s sub-components and layers and then leverages the optimal production orientated framework and quantization level for each one, all while taking into account the inference hardware characteristics. With Infery, BRIA’s team was able to maximize the acceleration potential of their complex models while saving valuable time and effort.
Infery’s optimization module was easily integrated into BRIA’s CI/CD pipeline. In its production environment, BRIA’s uses Infery’s deployment module, which includes advanced inference capabilities, integrated as a backend inference engine with NVIDIA Triton server.
Use enterprise-grade models. Lower risk, shorten dev time from months to days.
Save up to 80% on your inference cost. Migrate workloads to affordable & widely available HW.
Ship better products and delight users with low latency performance.
Choose an ultra performant model or generate a custom one.
AutoNAC
Neural Architecture Search Engine
DataGradients™
Dataset Analyzer



Use Deci’s library & custom recipe to train on-prem.
SuperGradients™
PyTorch Training Library

Apply acceleration techniques. Run self-hosted inference anywhere.
Infery
Optimization & Inference Engine SDK
Tell us about your use case, needs, goals, and the obstacles in your way. We’ll show you how you can use the Deci platform to overcome them.


Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")