Neural Architecture Search (NAS) holds the power to streamline and automate the cumbersome deep learning model development process, as well as quickly and efficiently generate deep neural networks that are tailored to meet specific production requirements.
This article provides the ultimate introduction to NAS, with a short background on AutoML, which NAS is a subfield of.
Let’s first define what artificial neural networks (ANNs) are to better understand deep neural networks. ANNs are computing systems based on artificial neurons that are designed to resemble a biological brain. These neurons can transmit and process signals. ANNs are built in three layers: input, for receiving data, hidden, for processing them, and output, for producing the results.
Deep neural networks can be defined as ANNs with additional depth, featuring multiple hidden layers of units, at least three or more, between the input and output layers. DNNs can learn more complex patterns by extracting features at different levels.
Training DNNs is based on the backpropagation algorithm which can be considered one of the most fundamental foundations of neural networks. DNNs compute parameters after each forward pass. Then they iteratively adjust and refine them during a backward pass to improve input data features extraction.
More complex tasks typically translate into long inference time, huge compute costs, and large memory requirements, all of which are barriers for successful commercialization of deep learning based applications.
RECORDED WEBINAR
How to Improve Model Efficiency with
Hardware-Aware Neural Architecture Search
Quickly generate deep neural networks to specific production constraints
Neural Architecture Search is a subfield of automated machine learning (AutoML), so let’s first understand what that is. Also referred to as automated ML, AutoML is an overarching term that relates to the process of automating the different tasks involved in applying machine learning to real-world problems.
Starting from a raw dataset to deploying a production-ready model, every stage of the traditional machine learning model development has components that are time-consuming, resource-intensive, complex, and iterative.
Using AI-based methods to automate the process of machine learning development, can significantly shorten the time to production. When it comes to classical machine learning algorithms ( e.g. random forests and neural networks), AutoML tools are used to simplify the model selection and choice of training hyperparameters. Examples of AutoML libraries include AutoWEKA, auto-sklearn, and AutoML.org.
Deep Neural Networks (DNNs) are powerful architectures but they are hard and time consuming to develop. There are numerous ways to structure and modify a neural network. In order to achieve the ultimate performance, there are various elements to consider including layer types, operations, and activation functions as well as the training data and deployment considerations (runtime, memory, and the inference hardware and its computational constraints).
Finding the most suitable deep learning architecture is a process that involves many trial and error iterations. Neural Architecture Search (NAS) provides an alternative to the manual designing of DNNs.
The general idea behind NAS is to select the optimal architecture from a space of allowable architectures. The selection algorithm relies on a search strategy, which in turn depends on an objective evaluation scheme. The popular convolutional neural network EfficientNet is an example of an architecture generated by NAS.

Neural architecture search is a growing area in deep learning research that aims to deliver better performing models and applications. However, it can still be challenging to implement. To further understand how NAS works, let’s dive into its components.
Neural Architecture Search has three main building blocks that can be categorized in terms of search space, search strategy/algorithm, and evaluation strategy (Elsken et al., 2019). Each of these components can utilize different methods.
01
Search space
Defining the operations used to design DNNs.
02
Search strategy
Optimizing metrics according to the approach used to explore the search space is essential for search strategy and performance estimation.
03
Evaluation strategy
Evaluating the performance of the DNN, prior to construction and training.
The NAS search space determines what type of architecture can be discovered by the NAS algorithm. It is defined by a set of operations that specify the overall structure (skeleton) of the network, the type of units or blocks that define the layers, as well as the allowable connectivity between layers to create architectures.
The more elements the search space has, the more complex and versatile it gets. But naturally, as the search space expands, the costs of finding the best architecture also increase. Types of operations used in defining the search space include sequential layer-wise operations, cell-based representation, hierarchical structure, and more.
The search strategy determines how the NAS algorithm experiments with different neural networks. How does it work in general? From a sample of the population of network candidates, the algorithm optimizes the child model performance metrics as rewards to create the output of high performance architecture candidates.
There are various methods that optimize search strategies to make the process deliver better results faster and with consistency. Types of search algorithms include random search, neuro-evolutionary methods (Elsken et al., 2019), Bayesian approaches (Mendoza et al., 2016), and reinforcement learning (Zoph and Le, 2016).
Some recent evidence suggests that evolutionary techniques perform just as well as reinforcement learning (Real et al., 2019). Moreover, the evolutionary methods tend to have better “anytime performance” and settle on smaller models. While earlier NAS techniques were based on discrete search spaces, a continuous formulation of the architecture search space has introduced differentiable search methods, which opened the way for gradient based optimization (Liu et al., 2019).
Here’s how some of the search methods work.
Random search is composed of a NAS algorithm that randomly selects a neural network architecture from the search space. It is an expensive process. Because instead of using a more efficient approach, it brute forces its way through the search space. It can take a large number of GPU days (up to hundreds to thousands) in one search depending on the complexity of the search space.
A type of search technique that trains machine learning models to make a sequence of decisions. The model seeks a solution to a problem that maximizes rewards. It does this based on trial and error and getting rewards and penalties. This enables making decisions in a complex environment, and learning to choose configurations that produce better neural networks for NAS.
An important contribution with reinforcement learning to combat the major bottlenecks in NAS, specifically, computational and memory resources, was introduced in 2018 by Hsu et al. called Multi-Objective Neural Architecture Search (MONAS) with Reinforcement Learning. It optimizes for scalability while ensuring accuracy and minimizing power consumption.
Bayesian optimization is a suite of techniques that are often used to speed up the search process. It is a popular approach for hyperparameter optimization. At a high level, it starts with choosing and evaluating architectures at random, then gradually tuning its search direction based on the evaluation results and information gathered about the performance of different architectures.
Bayesian optimization is expensive for NAS, but in 2020, White et al. achieved success through Bayesian Optimization with Neural Architectures for Neural Architecture Search (BANANAS), by coupling it to a neural predictor. Recent accomplishments include Neural Architecture Search with Bayesian Optimisation and Optimal Transport (NASBOT) by Kandasamy et al. (2018) for multi-layer perceptrons. There are also convolutional networks and A Bayesian Approach for Neural Architecture Search (BayesNAS) by Zhou et al. (2019) for one shot architecture search.
During a NAS search, the algorithm trains, evaluates, validates, and compares performance before choosing the optimal neural network. Full training on each neural network typically requires a long time and high compute demand – thousands of GPU days.
To reduce the costs of evaluating deep learning models, several strategies can be used (Jin et al., 2019), including:
It’s expensive to run search and evaluation independently for a large population of child models. To address this, another group of NAS methods, under the umbrella of one-shot architecture search, include a search space of sub-architectures belonging to a single super-architecture with trained weights that are shared among all sub-models (Xie et al., 2019). One-shot methods differ according to how the one-shot model is trained.
Efficient Neural Architecture Search (ENAS) by Pham et al. (2018) is a prominent example of a single-shot algorithm that achieves a 1000X speedup of the search relative to previous techniques. One of the prominent results in this venue is the “once for all” technique (Cai et al., 2019).
Faster NAS methods have mostly shown promising results over the smaller benchmark datasets (e.g., Cifar-10, MNIST, or reduced versions of ImageNet). It is crucial to improve NAS efficiency to make it commercially available to users who don’t have Google-scale computational resources.


Here are some examples of models generated with NAS and their uses on architectures:
Transfer learning is another AutoML approach that reuses a pre-trained model that was developed for one task as a starting point for working on a new problem. The intuition behind it is that neural architectures trained on a large enough dataset can serve as generic models that generalize for similar types of problems. Transfer learning is popular in deep learning as the learned feature maps can be used to train DNNs with a small amount of data.
In contrast, the underlying idea of NAS is that every dataset and its accompanying hardware and production environment, has a specific and unique architecture that performs best with it. Unlike transfer learning, there’s flexibility and customization in NAS that requires data scientists and developers to learn and train weights for the new architecture.
So, which AutoML approach is better? At the end of the day, it highly depends on the specific use case and available resources.
The need to be able to efficiently implement DNNs grows as they are increasingly used across multiple industries. However, this is a tiresome task that requires unique engineering expertise and multiple resources.
NAS allows to:
WHITEPAPER
Accelerate Deep Neural Network Inference
with AutoNAC
How to improve inference performance and efficiency with advanced Neural Architecture Search technology
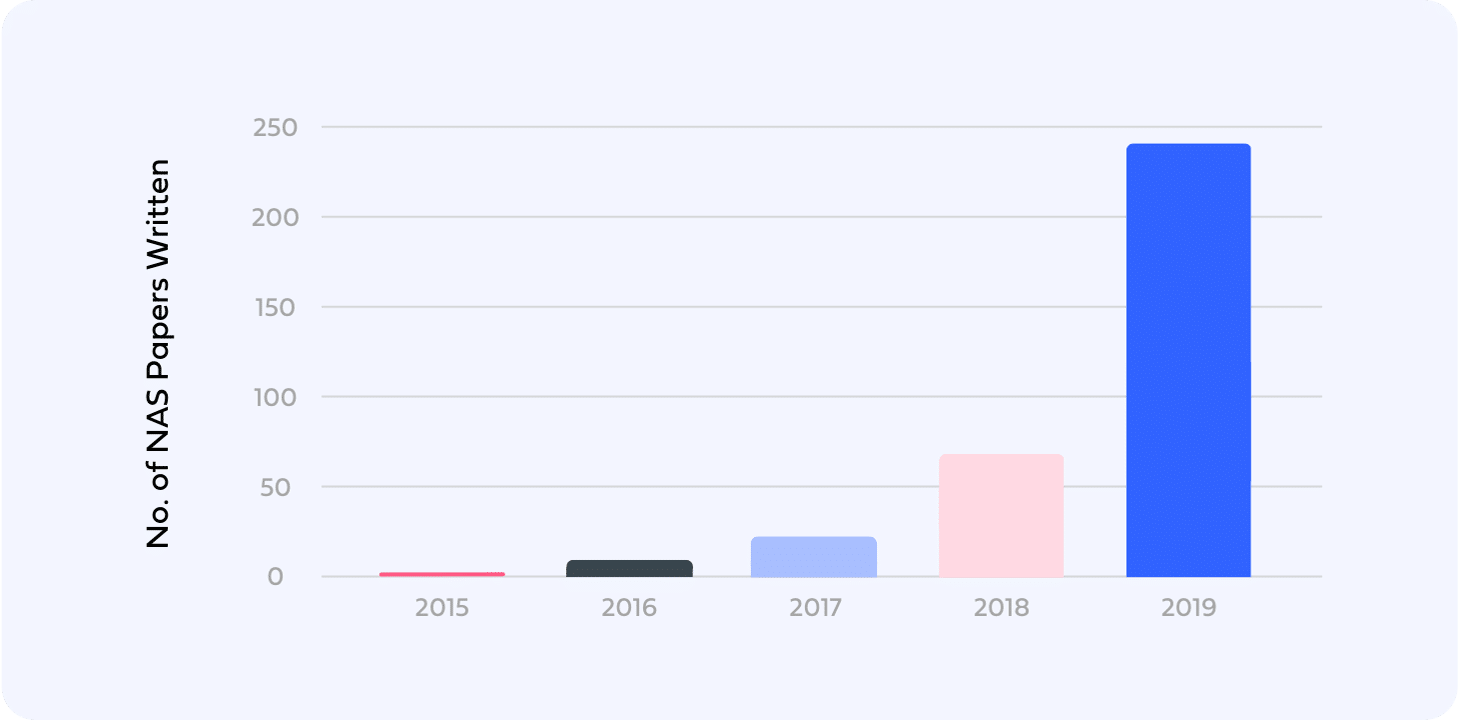
The growing interest in deep learning and AutoML accelerated the development of a variety of papers, techniques, and implementations for neural architecture search. More research is geared toward making it more efficient and less computationally expensive.
Using NAS involves a lot of moving parts. Here is a list of selected work from AutoML.org, a group of academic researchers at the University of Freiburg, led by Prof. Frank Hutter, and the Leibniz University of Hannover, led by Prof. Marius Lindauer.
Open-Source Libraries
NAS Benchmarks to Improve Efficiency
Best Practices for Using NAS
As mentioned above, NAS provides many benefits for data scientists looking to optimize DNNs and make them more efficient. But they still possess quite a few limitations:
Resource Intensive
NAS methods are computationally expensive because it can take many days and vast computational power to find the best model.
Real-time Blindness
NAS models are trained on offline data. It can be difficult to predict how they will perform on architectures with real data.
Time
While modern models run much faster than before, some models can take a long time to find the optimized architecture. Zoph et al.’s famous reinforcement learning / object detection method from 2017 took 28 days to run!
Deci is advancing and democratizing NAS technology. The Deci platform, powered by its proprietary NAS engine called AutoNAC (Automated Neural Architecture Construction). It is the most advanced and commercially scalable NAS solution in the market.
With Deci’s AutoNAC engine AI developers can easily and affordably build efficient computer vision models that deliver the best accuracy-latency trade-off.. Models generated by Deci outperform other known state-of-the-art (SOTA) architectures by a factor of 3x-10x.
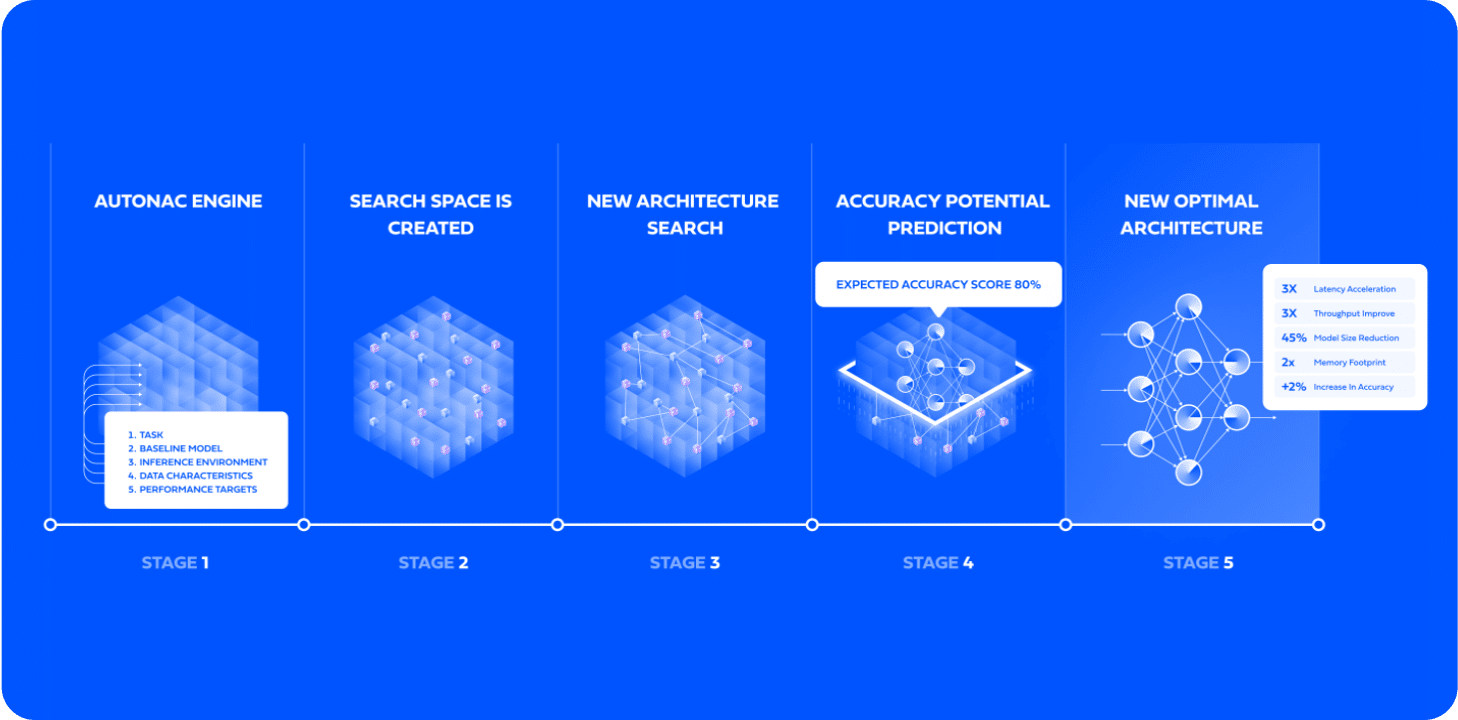
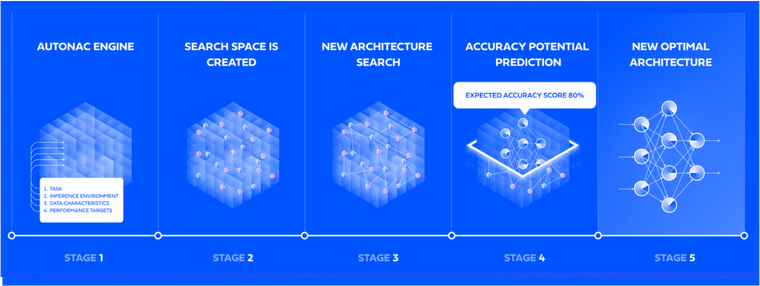
AutoNAC performs a multi-constraints search to find the architecture that delivers the highest accuracy for any dataset, speed (latency / throughput), model size and inference hardware targets. AutoNAC engine uses a very fast and powerful search strategy that can predict the accuracy of a neural network model without having to train it.
By using Deci’s platform, AI developers achieve improved inference performance and efficiency to enable deployment on resource constrained edge devices, maximize hardware utilization and reduce training and inference cost. The entire development cycle is shortened and the uncertainty of how the model will deploy on the inference hardware is eliminated.
To learn more about AutoNAC, visit here.
WHITEPAPER
Accelerate Deep Neural Network Inference
with AutoNAC
How to improve inference performance and efficiency with advanced Neural Architecture Search technology
Share

Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")