Deci is powered by groundbreaking Automated Neural Architecture Construction (AutoNAC™) technology. Deci’s AutoNAC™ engine democratizes the use of Neural Architecture Search for every organization and helps teams quickly generate fast, accurate and efficient deep learning models.
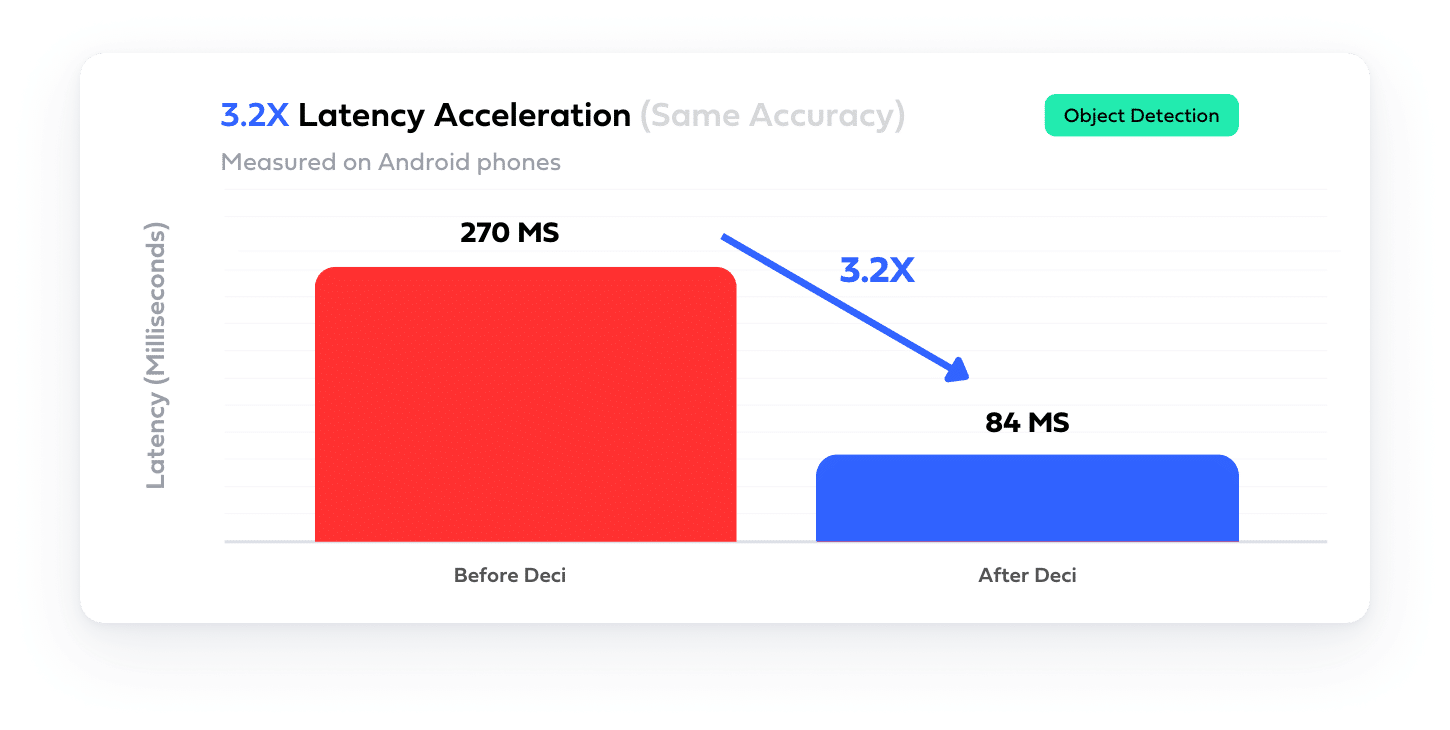
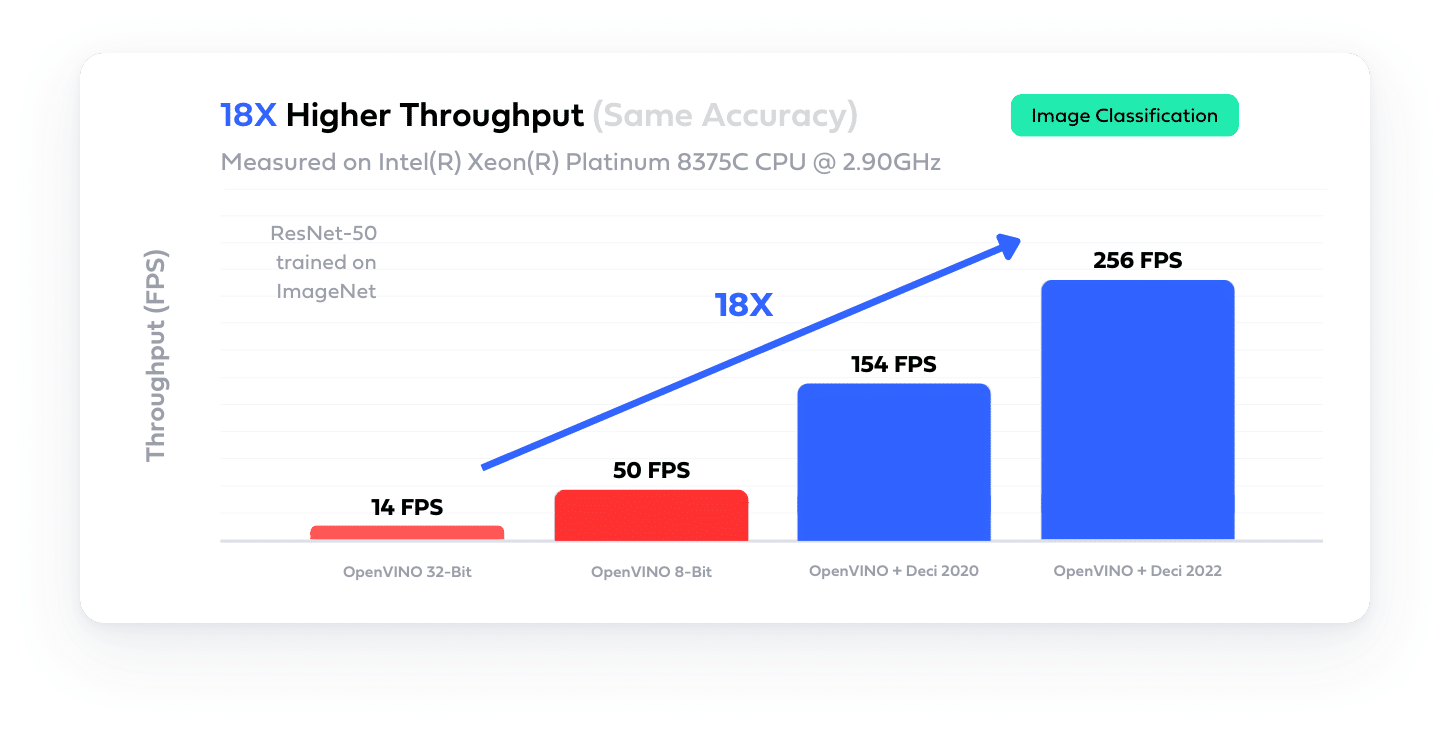
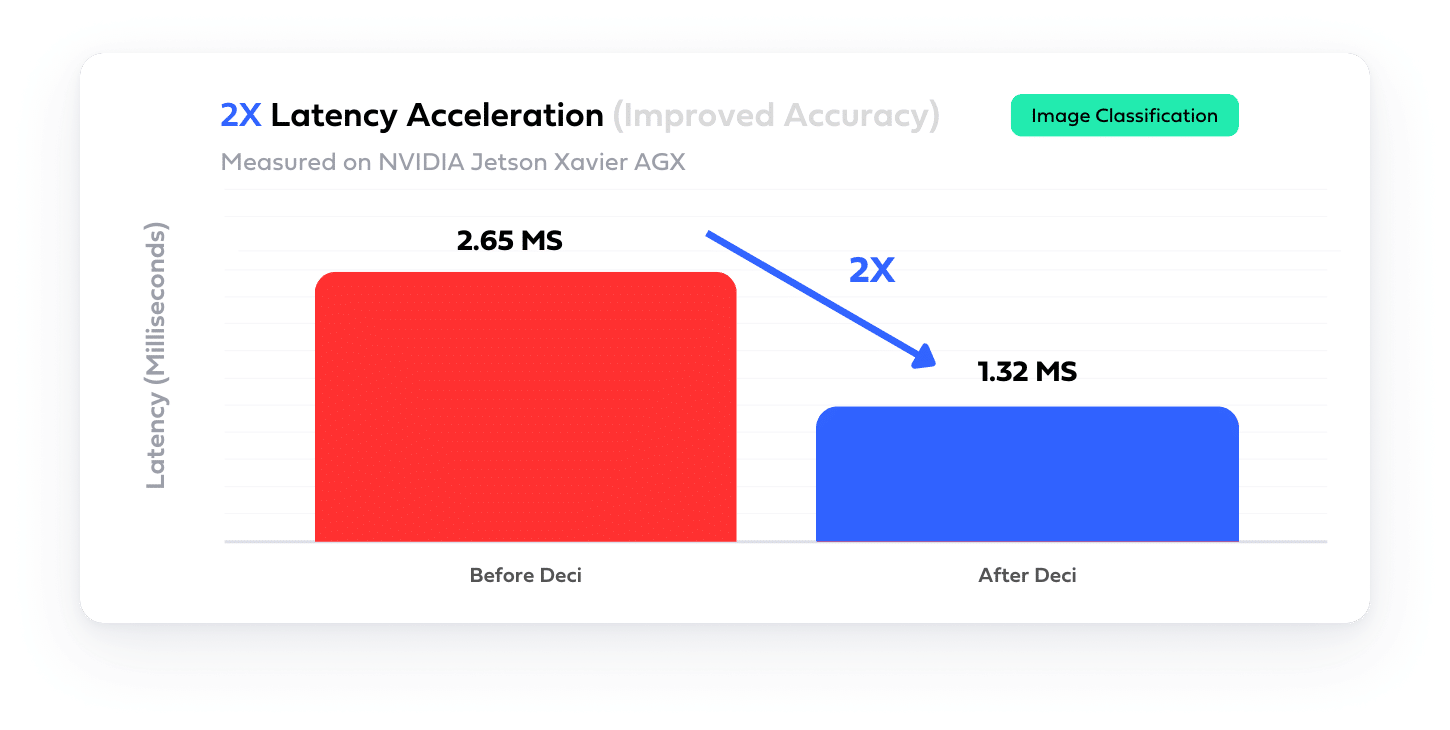
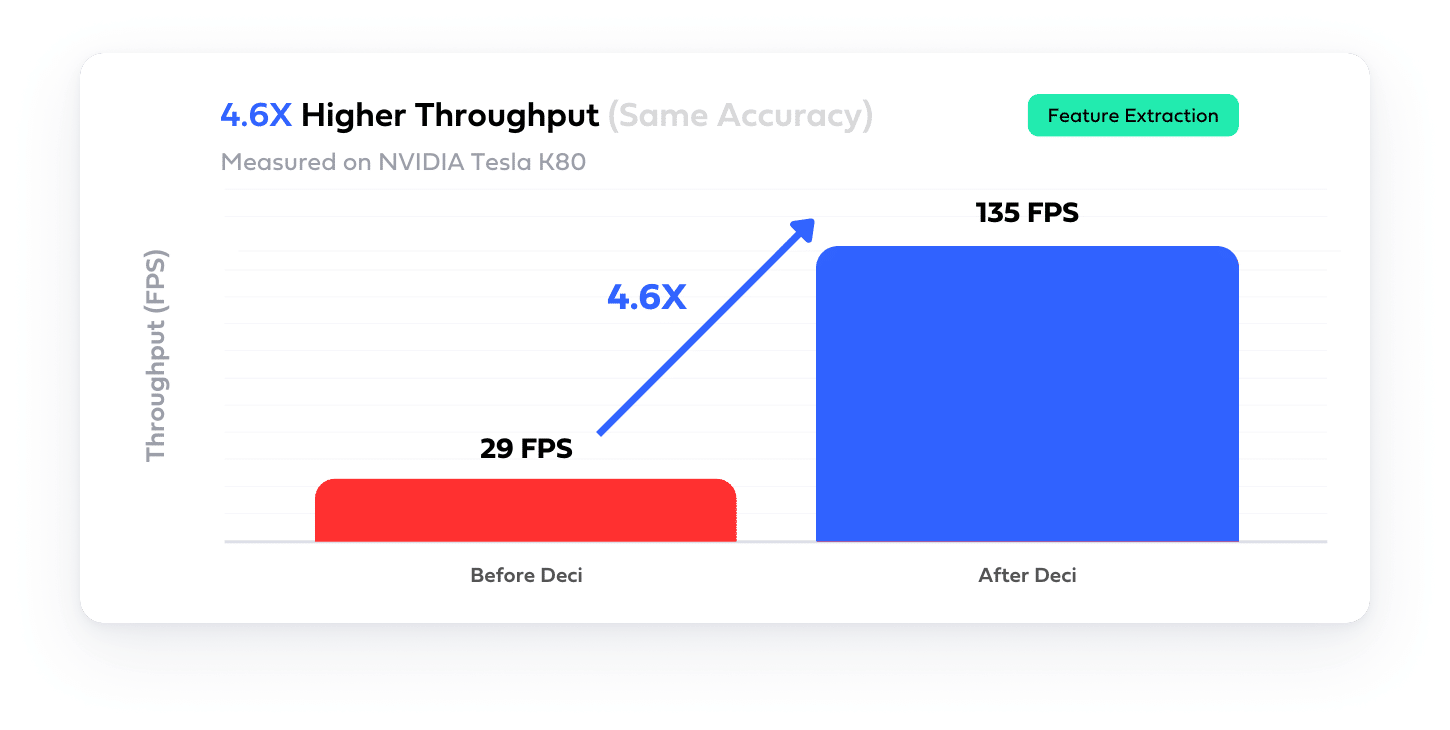





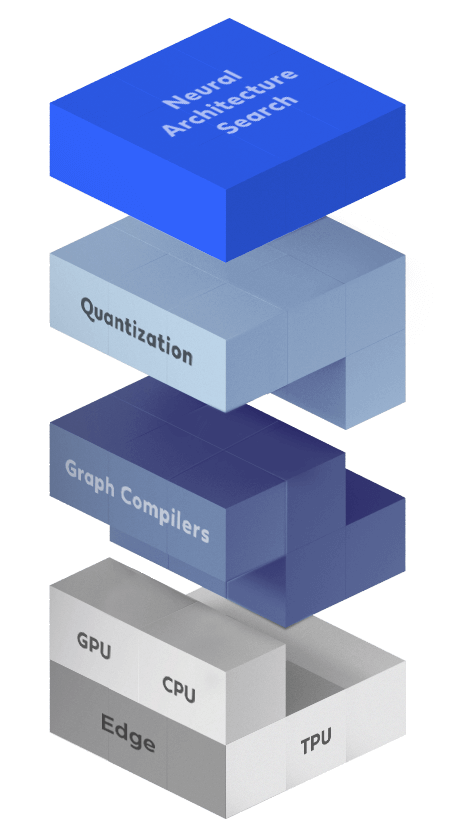
The most ambitious algorithmic acceleration technique for aggressive speedups is neural architecture search (NAS). To use NAS one should define an architecture space and use a clever search strategy to search this space for an architecture that satisfies the desired properties. NAS optimizations are responsible for monumental achievements in deep learning. For instance, MobileNet-V3 and EfficientNet(Det) were found using NAS.
NAS algorithms typically require huge computational resources and therefore, applying them in a scalable manner in production is extremely challenging and expensive. Deci’s, AutoNAC brings into play a new, fast and compute efficient generation of NAS algorithms allowing it to operate cost effectively and at scale. The AutoNAC engine is hardware and data aware and considers all the components in the inference stack, including compilers and quantization.
Quantization refers to the process of reducing the numerical representation (bit-width) of weights and activations, and can be used to speed up runtime if it is supported by the underlying hardware. With Deci you can easily qunatize your models to FP16 or INT8 while preserving your models accuracy.
The essential runtime components include drivers and compilers. Drivers implement neural network layers and primitives typically found within deep learning frameworks, such as TensorFlow(Keras), Pytorch, MXNet, and Cafe. These drivers must be programmed and tailored for each specific target hardware device.
Deep neural networks (DNNs) are represented as directed acyclic graphs (DAGs), called computation graphs. A compiler optimizes the DNN graph and then generates optimized code for a target hardware. The main techniques used by compilers are vertical and horizontal operator fusion, caching tricks, and memory reuse across threads. There are many compilers around and the more popular ones are NVIDIA’s Tensor-RT (TRT) and Intel’s OpenVino. With Deci you can automate the compilation of your models for your target inference hardware.
Inference hardware devices for neural networks have many forms and characteristics. Among the important factors are parallelism, shared memory size, virtual memory efficacy, and power consumption. These factors crucially affect the runtime of a given neural network. No less important is the maturity of the supporting software stack and the existence of a community of developers. Therefore, selecting the right model architecture for your target inference device is key for ensuring good performance. With Deci, you can easily benchmark and compare various models on different devices using our online hardware fleet to gain visibility into the potential performance and make data driven decisions.

Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")