Ultra efficient Generative AI and Computer Vision models, easily deployed across various environments while keeping your data secure and your inference cost under control.












Achieve accuracy & runtime performance that outperform SoTA models for any use case and inference hardware.
Reach production faster with automated tools. No more endless iterations and dozens of different libraries.
Maximize hardware utilization to enable new use cases on resource-constrained devices or cut up to 80% of your cloud compute costs.

Choose an ultra performant model or generate a custom one.
AutoNAC
Neural Architecture Search Engine
DataGradients™
Dataset Analyzer



Use Deci’s library & custom recipe to train on-prem.
SuperGradients™
PyTorch Training Library

Apply acceleration techniques. Run self-hosted inference anywhere.
Infery
Optimization & Inference Engine SDK
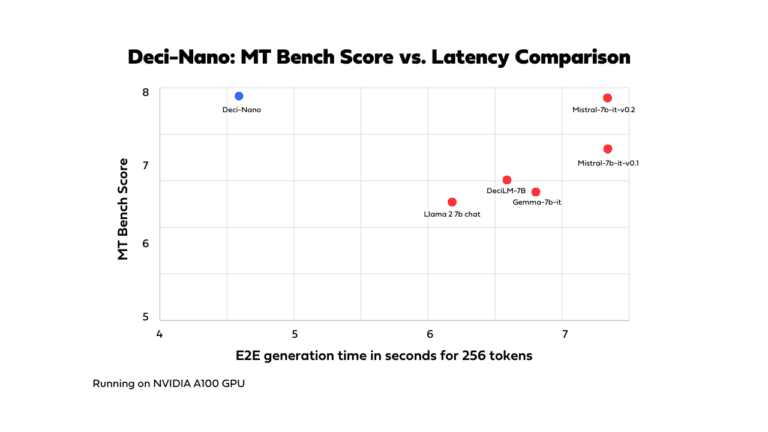

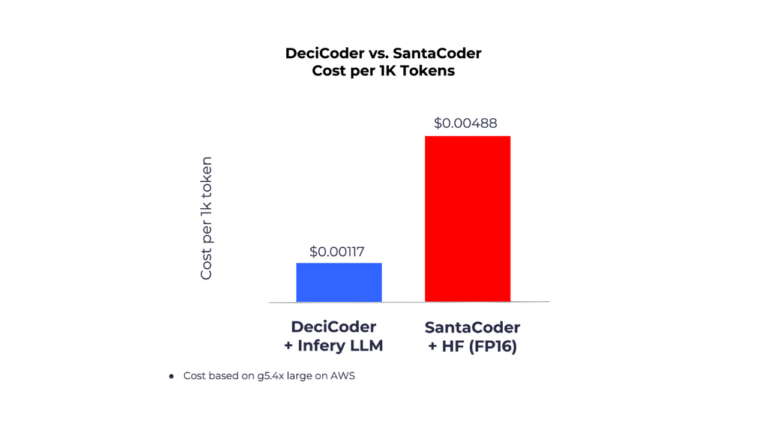
Shorter development process. Go from data to production ready model in days.
Lower development costs per model on average.
Inference
acceleration
Inference cost reduction

The world's most efficient and cost effective foundation models.

Gain a competitive edge through advanced model customizations.

Self-hosted inference. No vendor lock-in. Ideal for enterprises and for handling sensitive data.







Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")