Get Your Copy

With deep learning models becoming more prevalent not only in academia and research but also in industry applications, there is a need to focus not only on training and reaching the desired accuracy but also on overall inference performance and cost efficiency.
In this guide, you’ll gain a deeper understanding of deep learning inference, explore different ways to improve inference performance, learn from various industry use cases, and discover actionable tips to apply to your existing applications.
Explore the outline below to glimpse the contents of our guide. For a complete understanding and to access all the lessons, download the full guide.
Fast and efficient inference is central to powerful deep-learning applications. It is critical to user experience and has significant cost reduction implications. Today, there are five primary challenges that AI teams face when trying to get their models to run fast and efficient inference in production:
Different components play a role in inference acceleration, and optimizing each of them can boost the inference performance of deep learning-based applications.
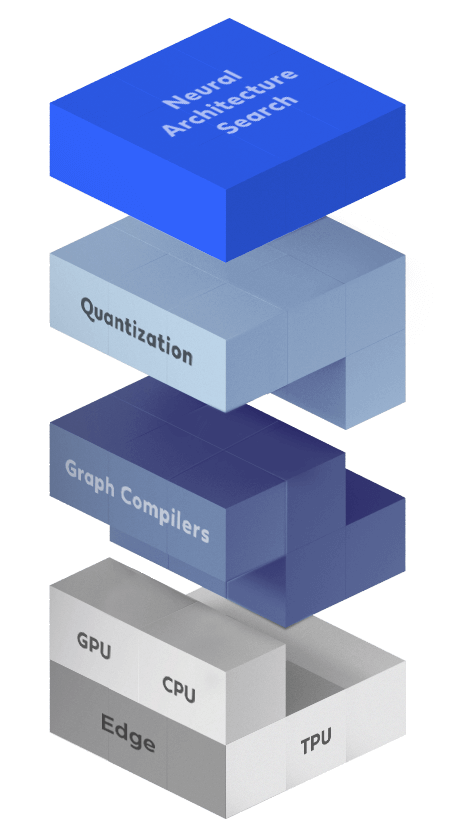
The inference acceleration stack comprises various layers – from the selected deep neural architecture used to the hardware selected for inference. All of these components are inextricably linked and changes to any of these layers can accelerate the inference process. By wisely improving several layers together, you can achieve a significant speed-up.
Hardware devices for AI inference vary in capabilities and cost, with factors like parallelism, memory size, and power consumption affecting neural network runtime. It’s essential to choose a model architecture aligned with the target hardware’s attributes for optimal performance.
Discover best practices for optimal architecture-hardware alignment:
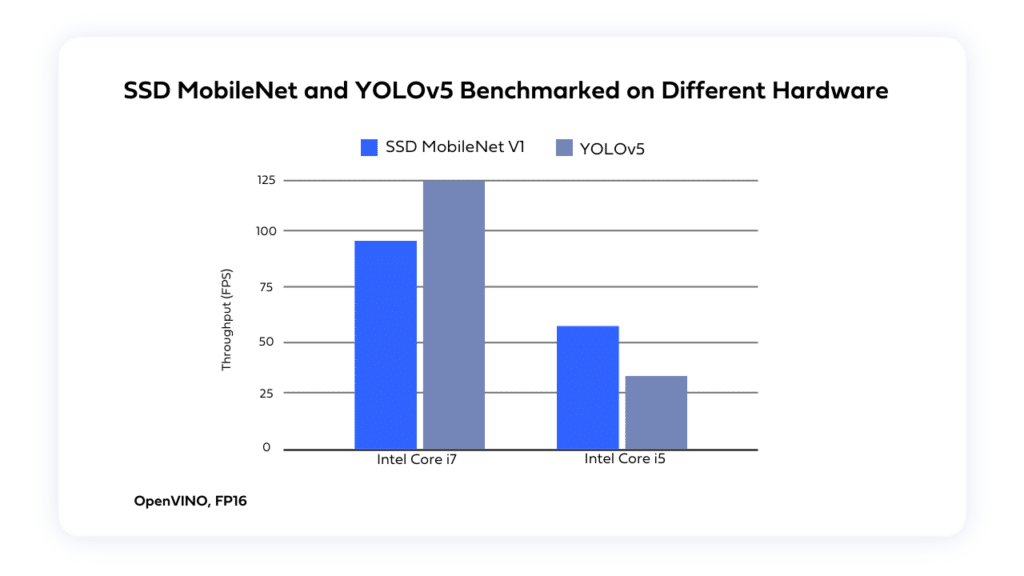
While training frameworks like PyTorch and TensorFlow may not be optimized for inference runtime, runtime frameworks like TensorRT, OpenVino, TFLite, TFJS, SNPE, and CoreML are designed to fill this gap. Learn how you can use these frameworks to optimize inference at the runtime level:
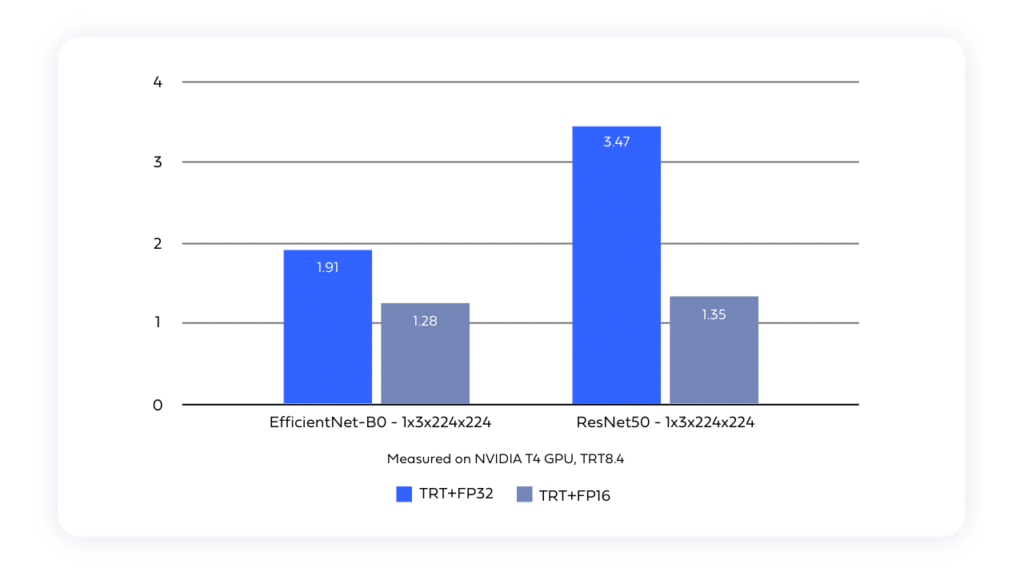
Algorithmic-level optimization involves refining the structure and design of neural networks to boost their efficiency during inference.
Learn what you can do to optimize inference at the algorithmic level:
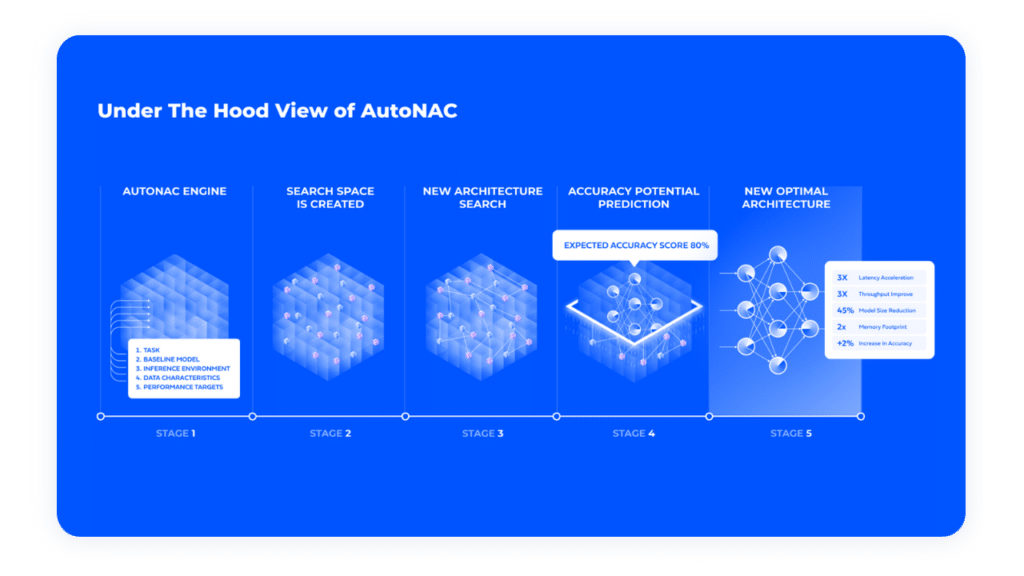
A model is only as good as its deployment, and real-world deployment involves intricate pipelines. Dive deep into how to streamline this process, from data transformation to the critical server-side decisions that can make or break your application’s performance. Discover how tools such as G-Streamer and NVIDIA DeepStream can help you design complex inference pipelines and face the challenges of scalability and performance.
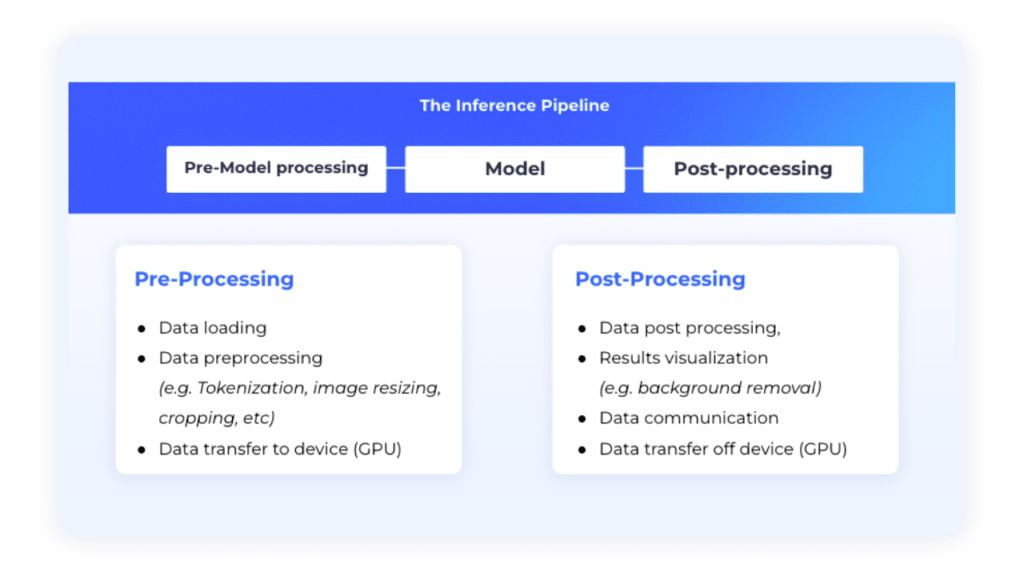
Get acquainted with effective pre/post-processing optimization techniques:
Dive into key server-related optimizations that can significantly enhance the efficiency and performance of your deep learning deployments.
The Ultimate Guide to Inference Acceleration of Deep Learning-Based Applications
Gain expert insights and actionable tips to optimize deep learning inference for performance and cost.
Deci’s Deep Learning Development Platform, is a comprehensive solution that enables AI professionals to efficiently design, optimize, and deploy top-tier models on any hardware. With tools that streamline every step, from model selection to deployment, Deci ensures a swift transition from data to production-ready models. The platform’s features include:
By using Deci’s suite of inference acceleration solutions, companies with computer vision and NLP applications from industries such as manufacturing, consumer applications, automotive, security, smart city, and energy, among others, have gained unparalleled inference performance.
Discover their success stories
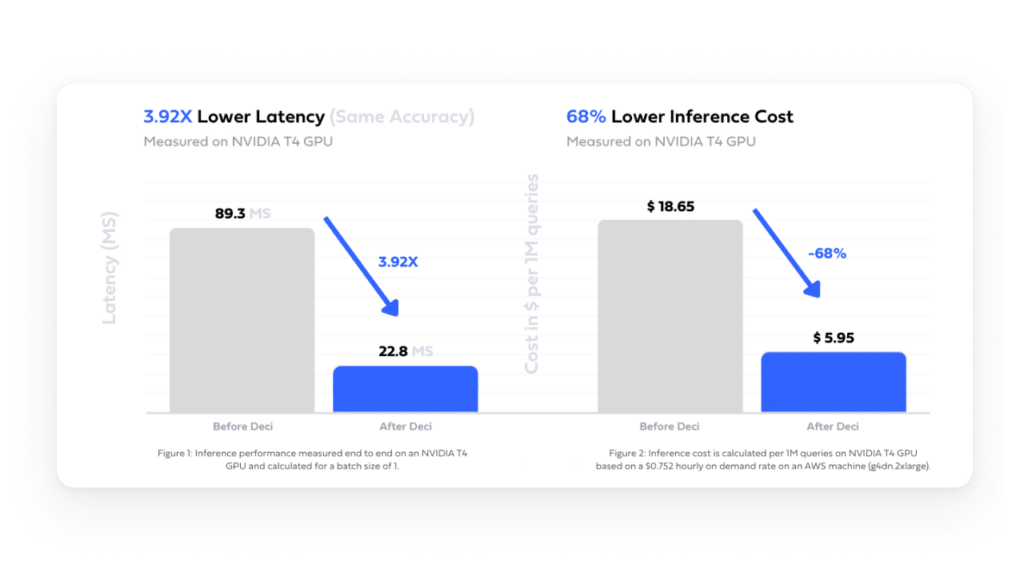
Learn how, using Deci’s compilation and quantization tools, an AI company improved their text summarization platform’s latency, enhancing user experience and substantially cutting cloud costs.
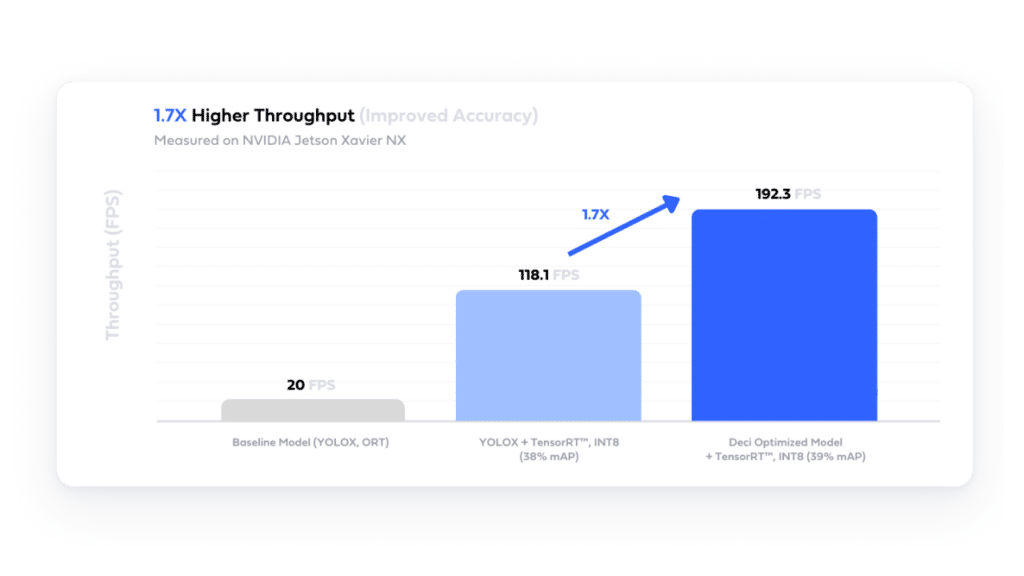
Using Deci’s AutoNAC engine, a security company enhanced their YOLOX model’s performance, achieving 192 FPS and better accuracy, enabling them to process double the live video streams on their NVIDIA Jetson Xavier NX hardware.
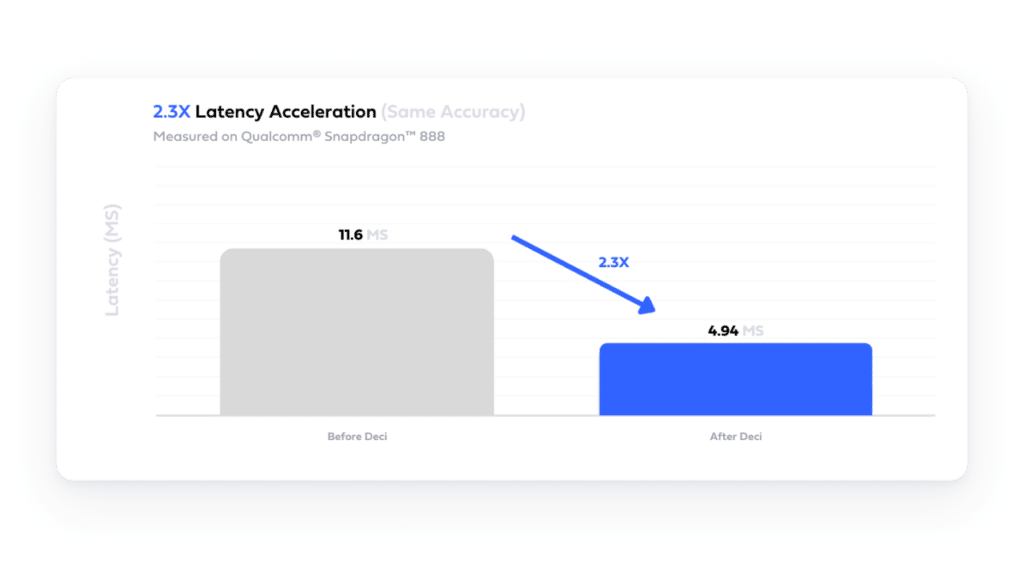
Using Deci’s platform, a company tailored a person segmentation model for a Qualcomm® Snapdragon™ 888 board, achieving 3x latency reduction, 4.47x smaller file size, and a 22% reduced memory footprint without compromising accuracy.
In deep learning inference, many components come into play, including the hardware, software, algorithms, and pipeline, as well as the different techniques that you can implement to optimize each of them. What also affects inference performance are the constraints of real-world production, such as resource availability, application requirements, and operational cost.
To reach the full inference potential of your deep learning applications, it is important to consider all these factors. End-to-end solutions like Deci take a holistic approach to inference acceleration, resulting in the best possible performance that is specific to your needs. Dive deeper into accelerating the inference of your deep learning application and explore Deci’s solution. Download the guide.
The Ultimate Guide to Inference Acceleration of Deep Learning-Based Applications
Gain expert insights and actionable tips to optimize deep learning inference for performance and cost.
Share

Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")