
A customer developing an AI platform for text summarization was struggling to achieve satisfactory latency performance on a model powering their application. This led to a poor user experience as well as high cloud costs. The model was deployed on NVIDIA T4 GPU.

The customer used Deci’s compilation and quantization tools to easily optimize the model performance and significantly reduce cloud cost as well as improve the user experience.
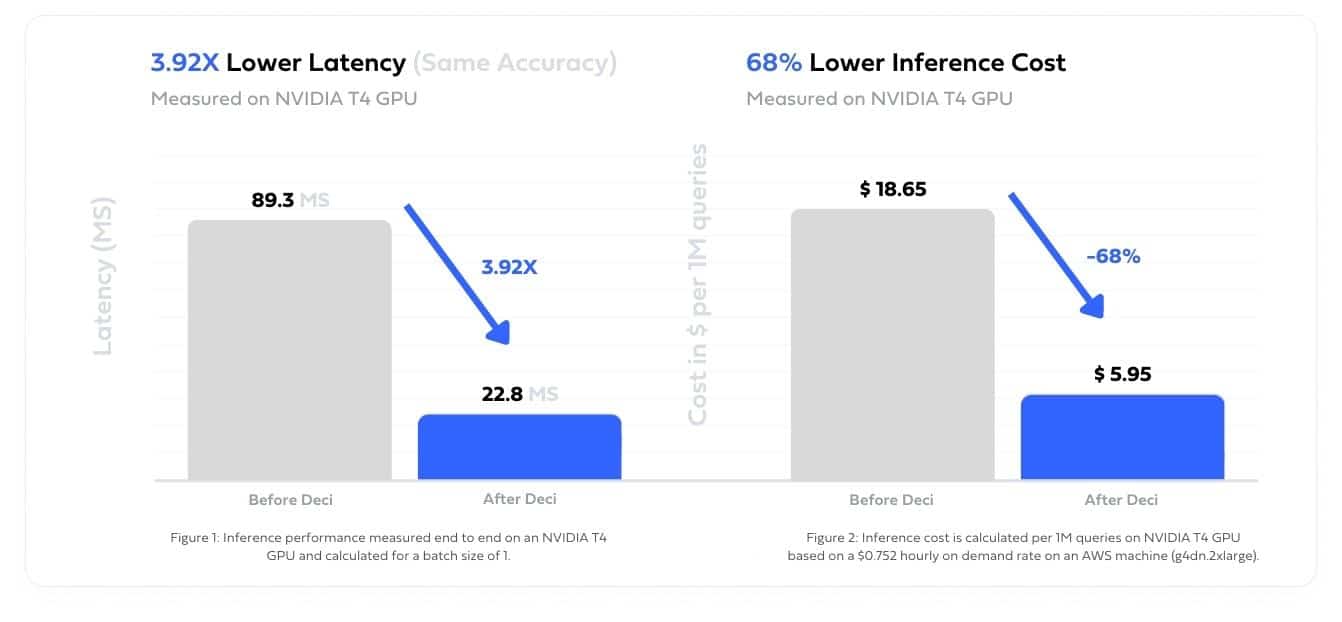
Lower your cloud bill by maximizing the throughput of your models.
Run your models on affordable and widely available GPUs by improving inference efficiency.
Improve inference speed without compromising on accuracy.
Tell us about your use case, needs, goals, and the obstacles in your way. We’ll show you how you can use the Deci platform to overcome them.


Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")