
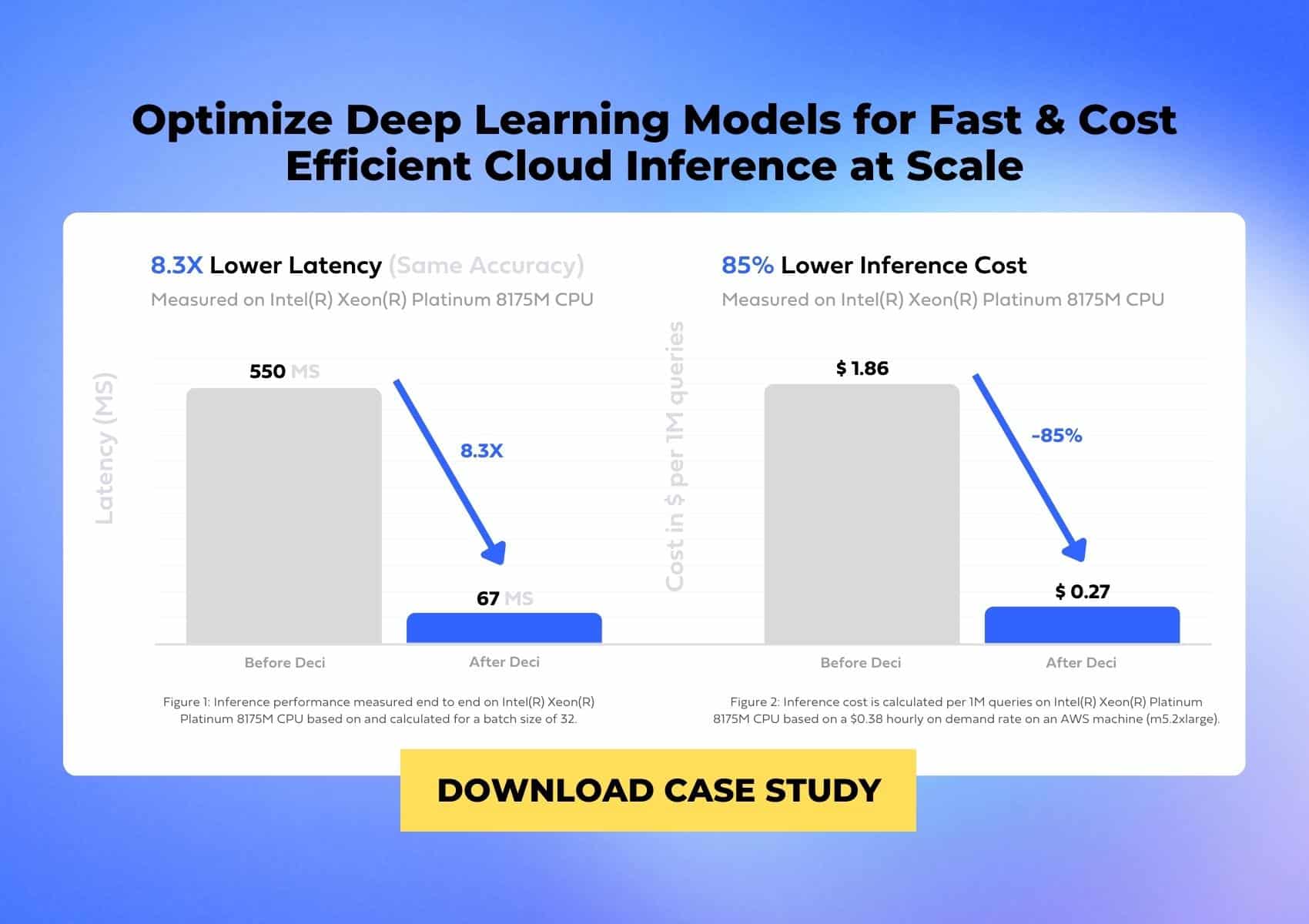
Running your deep learning models in cloud environments is a costly matter. High inference costs can dramatically cut down your product’s profitability. To win, you need to ensure that your AI infused applications can be highly accurate, fast, and cost efficient. Achieving a sweet spot among these three parameters is often a struggle for AI teams who end up relying on more powerful and expensive cloud instances to support their applications’ inference.
At the end of the day, companies face the dilemma of executing model inference at a lower operating margin but with high performance, or sacrificing the user experience with poorly-performing deep learning models.
Learn how you can boost your models’ performance and maximize hardware utilization to cut down inference time and cost on existing hardware as well as migrate workloads to more affordable cloud instances.
Fill up the form and discover three case studies that demonstrate how companies were able to improve performance and cut their cloud cost by optimizing their models.
