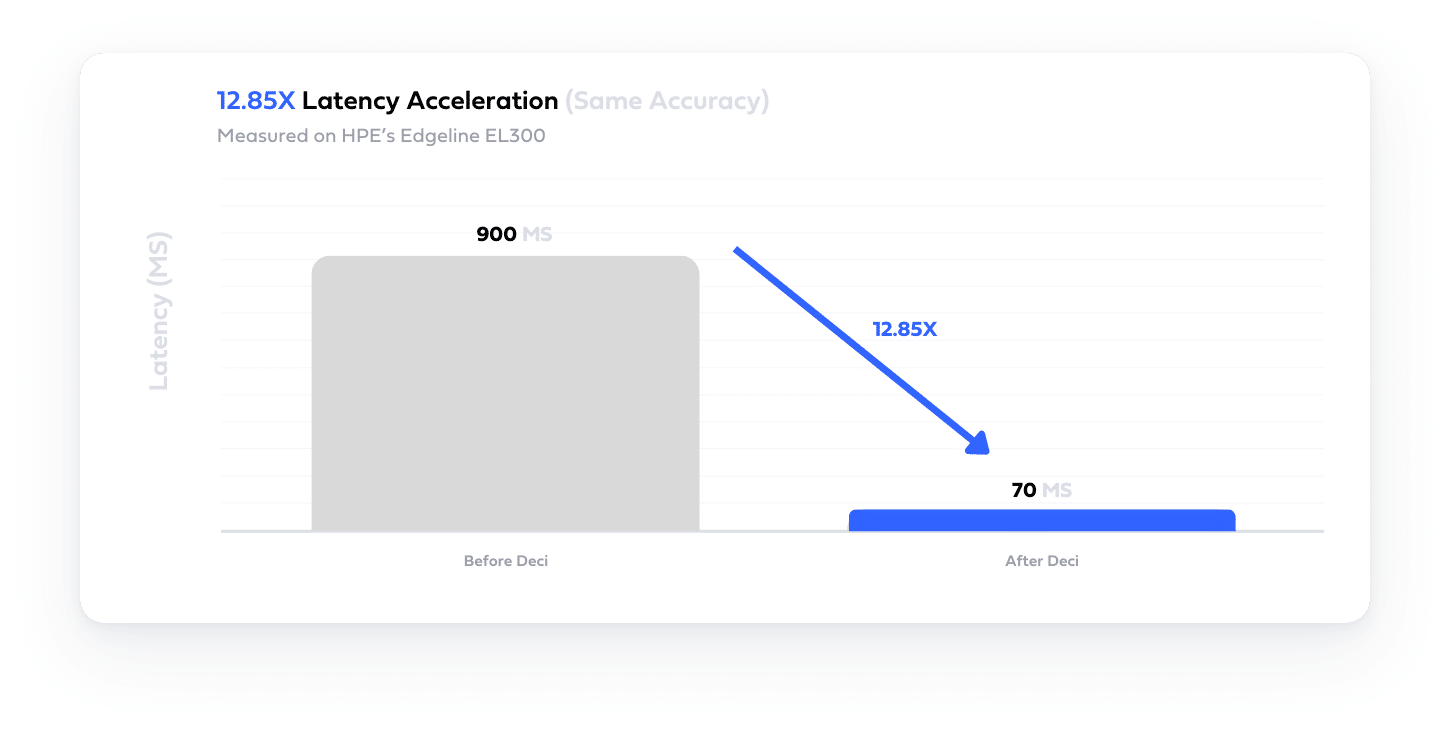
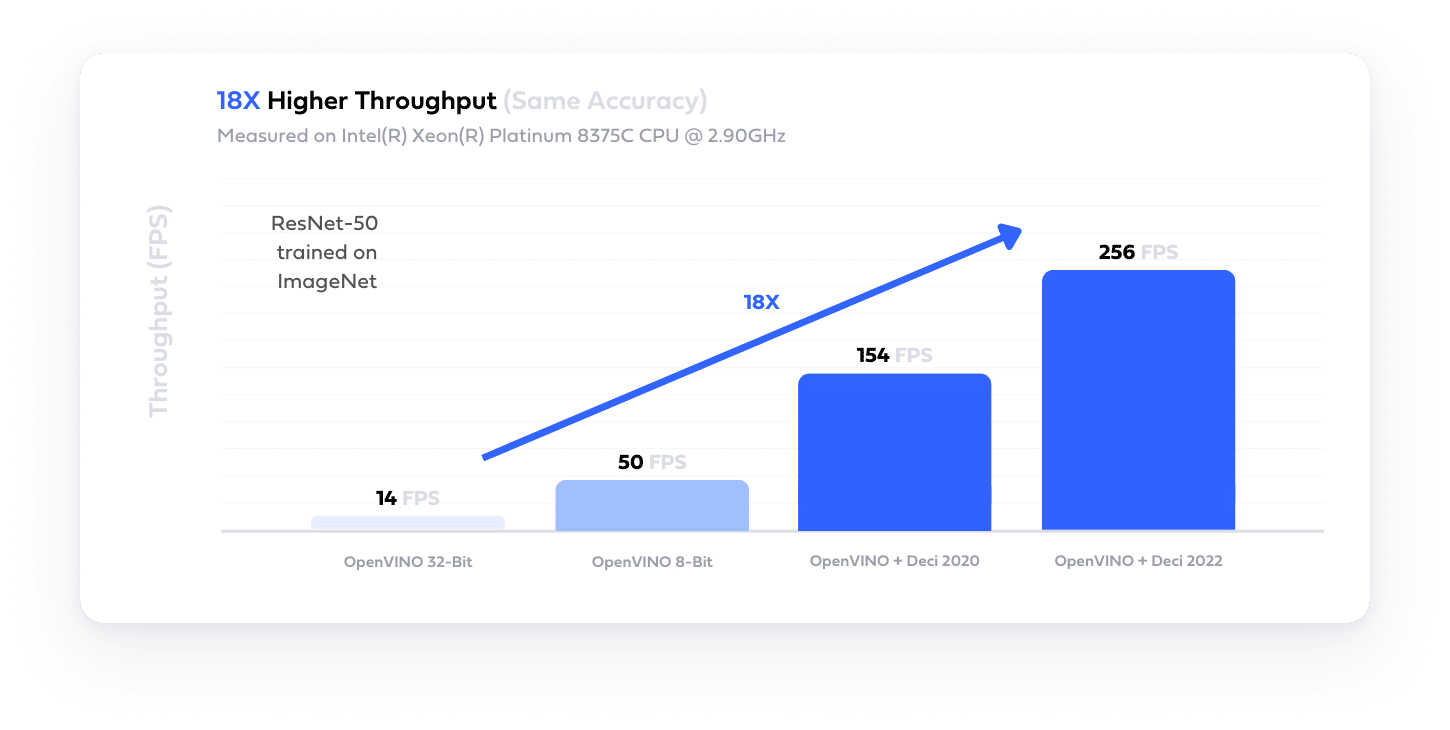
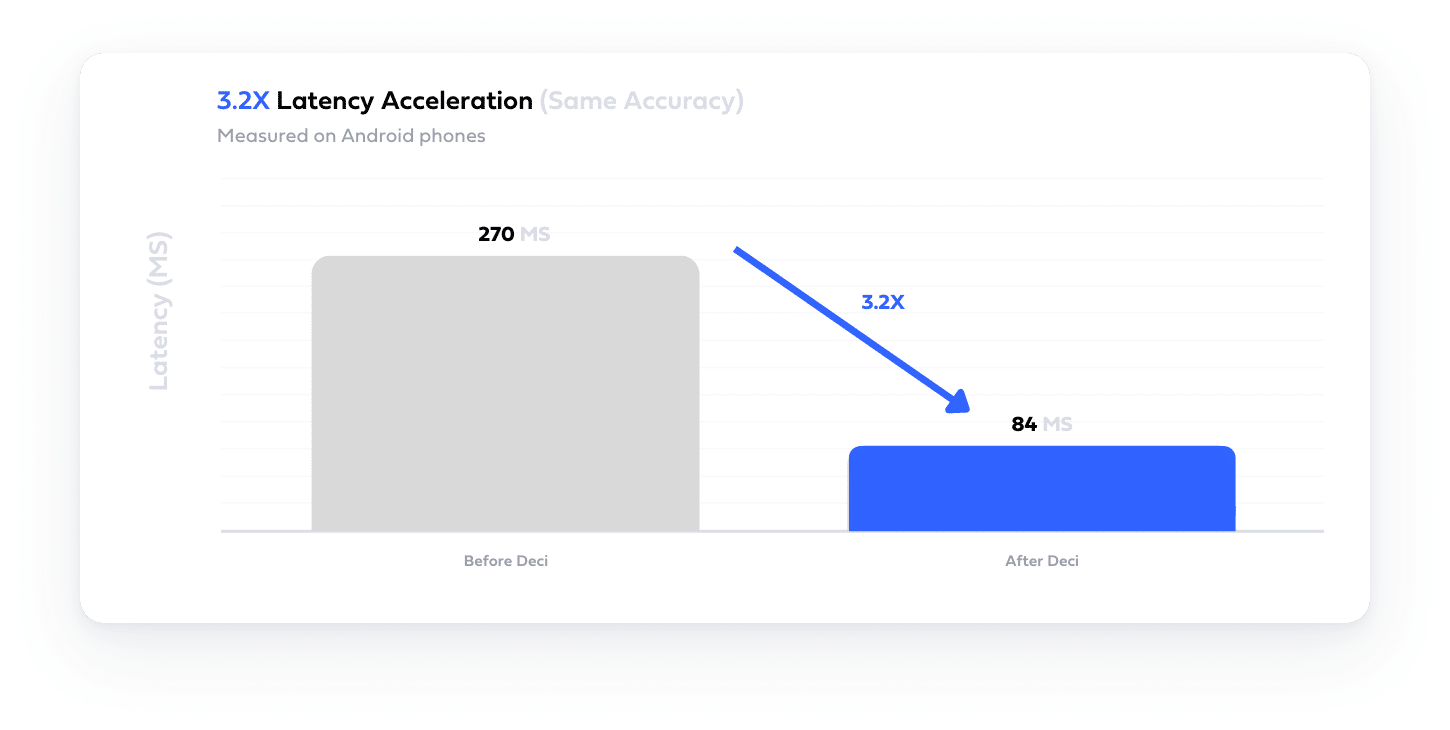
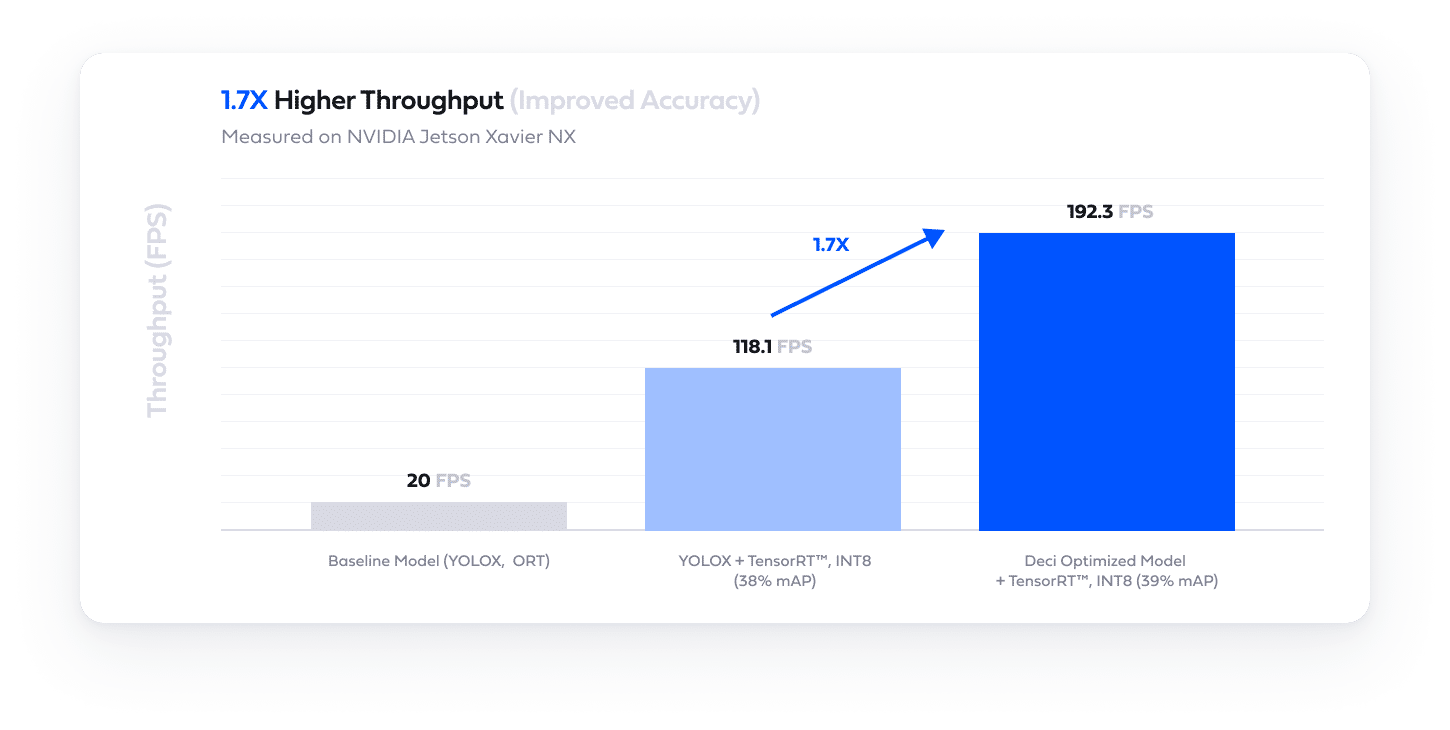
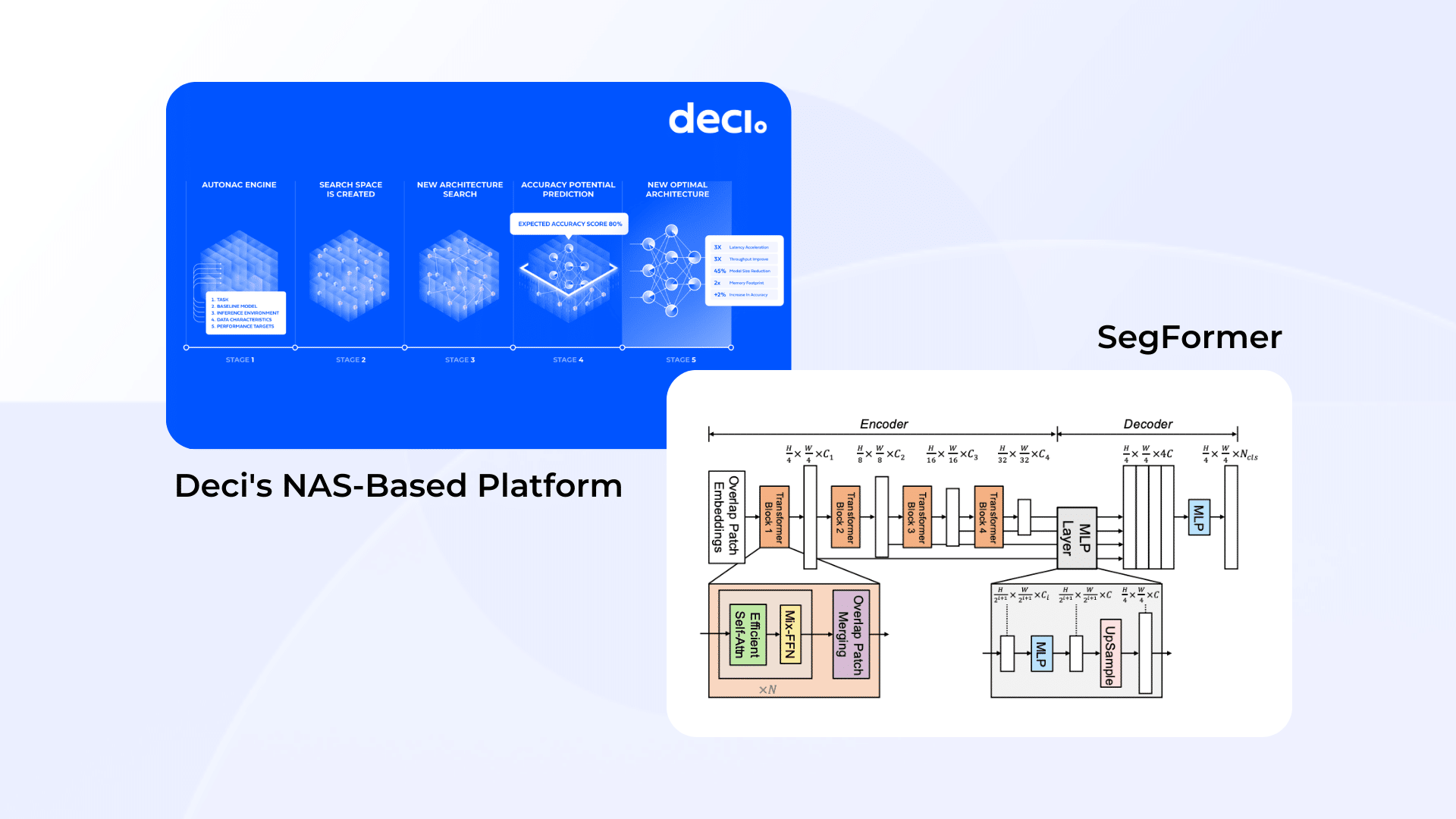
Easily build hardware and data aware model architectures that deliver superior accuracy and performance tailored for your needs with Deci’s AutoNAC engine.
Teams spend precious time and go through endless trial and error iterations when trying to manually design models yet, only 30% of models make it to production. Use Deci’s Neural Architecture Search engine (AutoNAC) to easily build custom, production-grade models that deliver better than SOTA performance.
Maximize your data and hardware potential with a powerful custom model architecture.
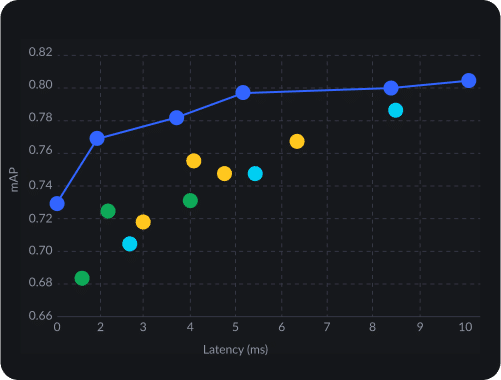
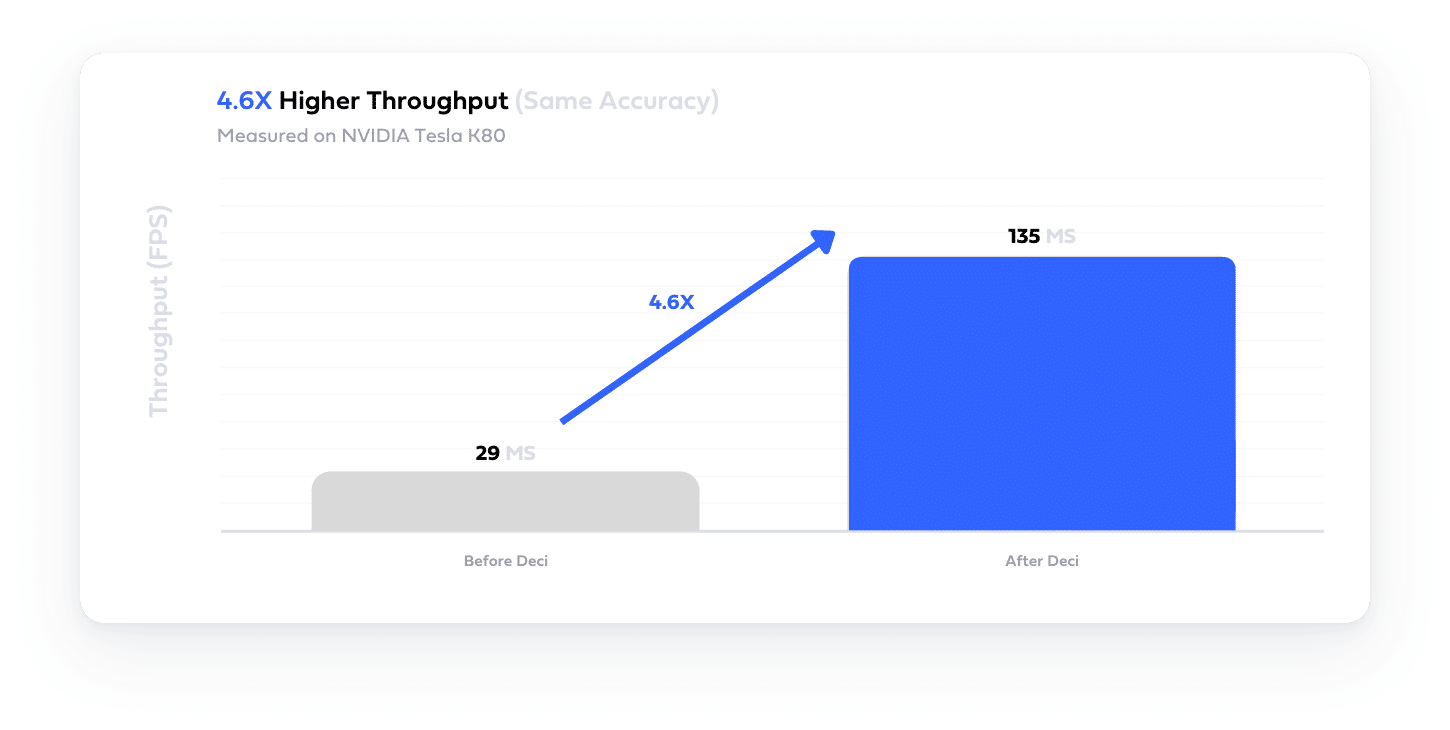
Reach production in days instead of months by beginning your deep learning project with the best accuracy and latency results in hand.
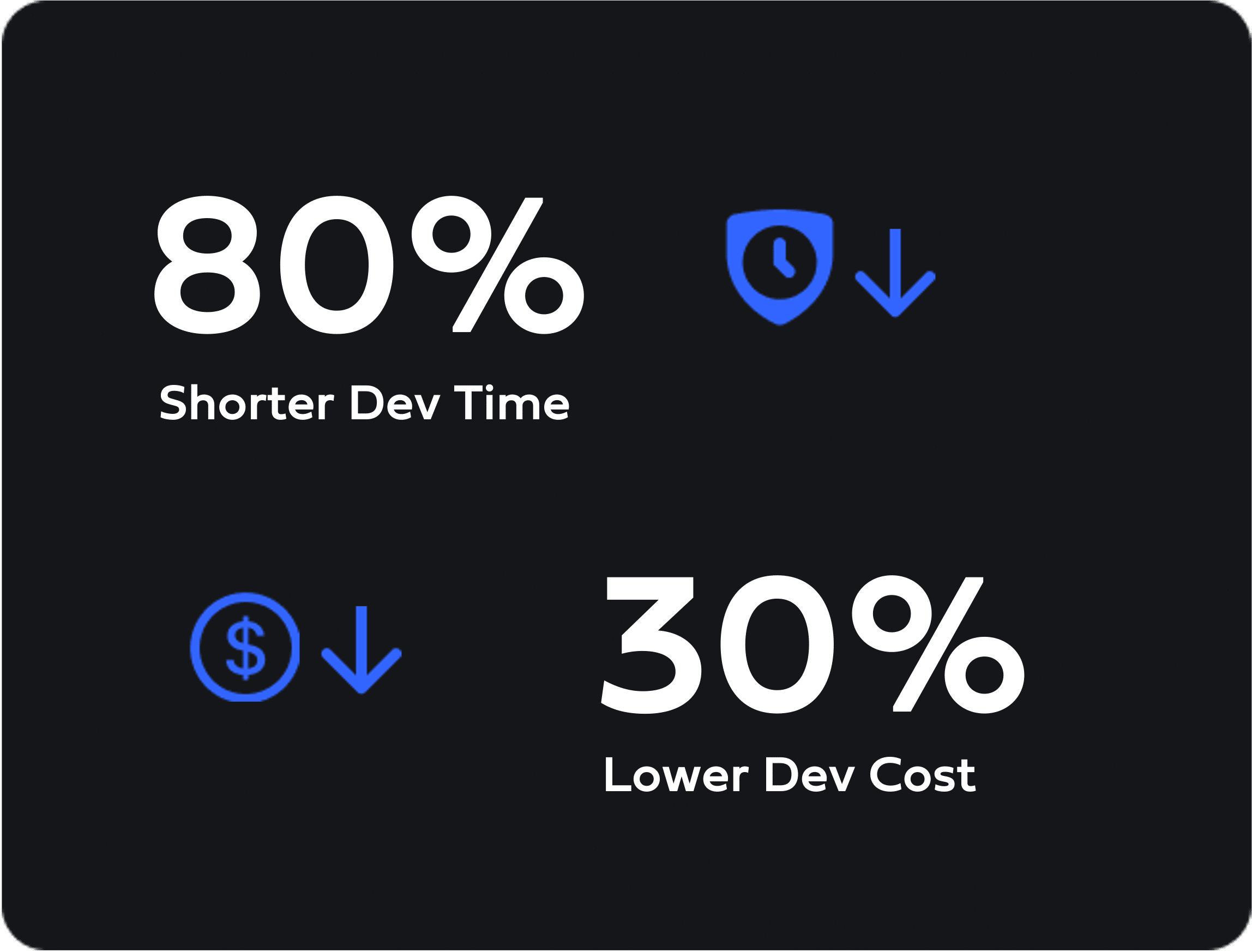
Eliminate endless iterations and ensure your models meet production requirements successfully.

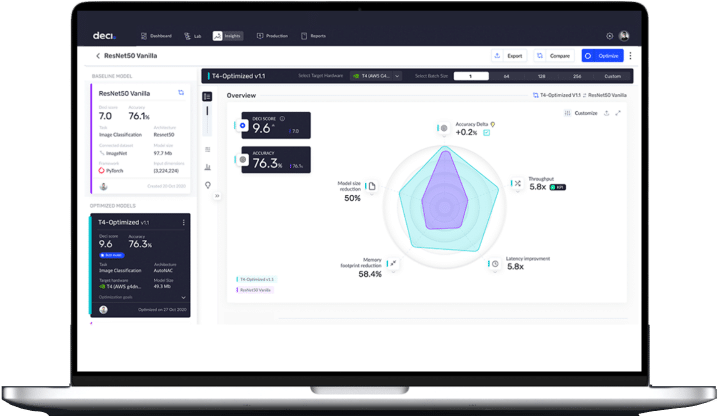
As an input, the AutoNAC engine requires information relating to desired performance targets as well as data characteristics such as the task, image resolution, average size of an object, maximum objects per image and number of classes. Then, AutoNAC performs a multi-objective search within a huge search space to find an architecture that delivers the highest accuracy for your specific speed, model size and inference hardware targets.
Deci’s AutoNAC engine includes a sophisticated accuracy predictor which analyzes the architecture’s ability to reach a high accuracy. The predictor examines the network’s topology and building blocks and determines the expected performance without having to train it. The output? A highly accurate and fast architecture tailored to your needs.

AutoNAC, short for Automated Neural Architecture Construction, is Deci’s proprietary optimization technology. It is a Neural Architecture Search (NAS) algorithm that provides you with end-to-end accuracy-preserving hardware-aware inference acceleration. AutoNAC considers and leverages all components in the inference stack, including compilers, pruning, and quantization.
Absolutely. You can easily integrate Deci’s deep learning acceleration platform using our API access.


Deci is ISO 27001
Certified
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")