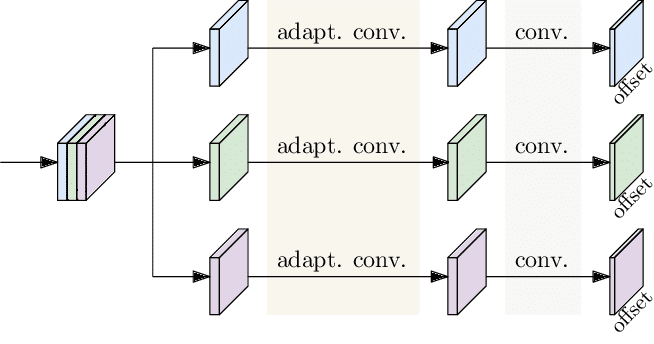
In disentangled keypoint regression (DEKR), each branch learns the representation for one keypoint through two adaptive convolutions from a partition of feature maps output from the backbone and regresses the 2D offset of each keypoint using a 1×1 convolution separately. An illustration for three key points is shown in the figure below, the feature maps are divided into three partitions, each fed into one branch. In the experiments on COCO pose estimation, the feature maps are divided into 17 partitions and there are 17 branches for regressing the 17 key points.
DEKR adopts the multi-branch parallel adaptive convolutions to learn disentangled representations for the regression of the key points, so that each representation focuses on the corresponding keypoint region.
Expected Input
The DEKR model takes an image as input and predicts the human poses for all the persons in the image, where each pose consists of K keypoints, such as shoulder, elbow, and so on.
Expected Output
DEKR outputs an image with a regressed pose at each position, and the keypoint and center heatmaps.
History and Applications
Human Pose Estimation identifies and classifies the poses of human body parts and joints in images or videos. The human pose estimation can be classified into two primary approaches: bottom-up and top-down. Bottom-up methods evaluate each body joint first and then arrange them to compose a unique pose. Top-down methods run a body detector first and determine body joints within the discovered bounding boxes. Different libraries are available on the internet for human pose estimation, which includes OpenPose, DensePose, AlphaPose, and HRNet
Some real-world applications of pose estimation include:
AI-powered personal trainers
Robotics
Motion capture and augmented reality
Athlete pose detection
Motion tracking for gaming
Infant Motion Analysis
Metrics and Performance
Training and Evaluation Data, and Metrics
DEKR is trained and evaluated on the COCO 2017 keypoint detection dataset. The COCO (Common Objects in Context) dataset is an image recognition dataset for object detection, segmentation, and image captioning tasks. The COCO 2017 dataset includes keypoint annotations for over 250,000 people in more than 200,000 images. These annotations provide the x and y coordinates of 17 key points on the body, such as the right elbow, left knee, and right ankle.
Average Precision (AP)
The standard average precision based on Object Keypoint Similarity (OKS) is adopted as the evaluation metrics. OKS measures the similarity between predicted and ground truth key points and is calculated based on Euclidean distance and a scale factor related to the object size.
On the COCO dataset, the proposed approach with HRNet-W32 as the backbone achieves 67.3 AP score, and significantly outperforms the methods with the similar model size. With HRNet-W48 as the backbone, a 70.0 AP score is achieved. On multi-scale testing, the proposed approach with HRNet-W32 achieves a 69.8 AP score. With HRNet-W48, a 71.0 AP score is achieved.
Inference Performance
When selecting an architecture there are several things you should carefully consider:
What is the expected performance of the architecture on your target inference hardware?
What is the architecture performance after compilation and quantization?
Does this architecture deliver the best accuracy-speed tradeoff for your specific project?
Having clarity on these topics before you start training the model can save you a lot of time, effort, and money.
How to Use
Installation
You can find the open-source code for DEKR with SuperGradients here.
The code to train or fine-tune the DEKR model can be found in this notebook.
You can use the DEKR model to do pose estimation on images. Below, see how you can easily load the pretrained model and use it for pose estimation.
!pip install super-gradients==3.1.3
from super_gradients.common.object_names import Models
from super_gradients.training import models
dekr_model=models.get(Models.DEKR_W32_NO_DC,pretrained_weights="coco_pose")
dekr_model.predict("image.jpg").show()