
Today we launch our Gen AI Development Platform, featuring a new series of proprietary, fine-tunable large language models (LLMs), an inference engine, and an AI cluster management solution.
Designed to balance quality, speed, and cost-effectiveness, our models are complemented by flexible deployment options. Customers can access them through our platform’s API or opt for deployment on their own infrastructure, whether through a Virtual Private Cloud (VPC) or directly within their data centers. Our goal is to equip our customers with access to high performance models, offering the needed flexibility and control over data privacy, applications, and costs.
The first LLM in our series to be made available is Deci-Nano. Here are some highlights:
- Deci-Nano exhibits advanced language and reasoning capabilities, making it ideal for a broad spectrum of applications, such as financial and legal analysis, copywriting assistance, chatbots, summarization, and brainstorming.
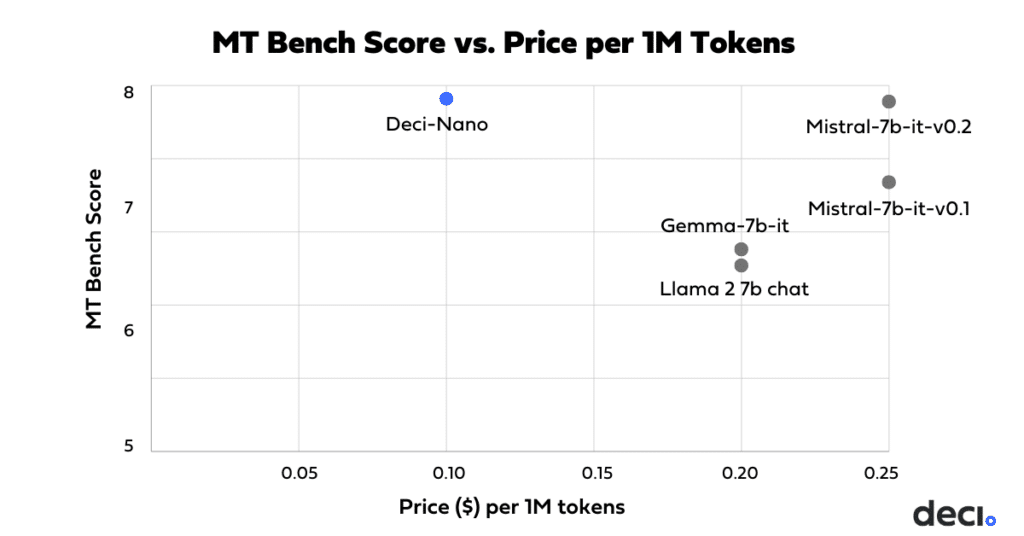
- The model achieves superior scores on MT Bench compared to both Mistral-7b-instruct-v0.2 and Gemma-7b-it.
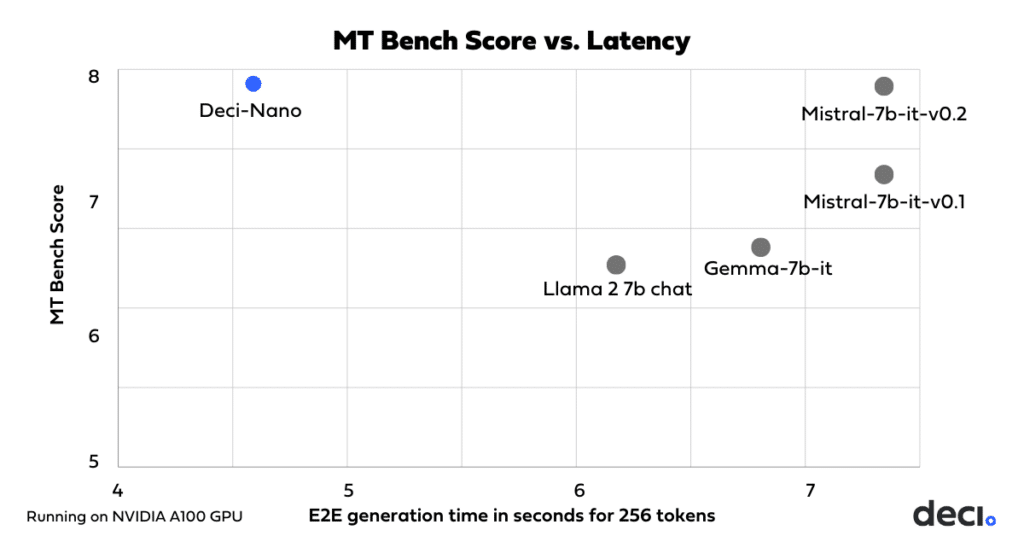
- Deci-Nano is significantly faster than other models with similar capabilities, such as Mistral-7b-instruct-v0.2 and Google’s Gemma 7b-it, making it an excellent choice for real-time applications. When benchmarked on NVIDIA A100 GPUs, Deci-Nano’s end-to-end latency for generating 256 tokens is 38% faster than Mistral-7b-instruct-v0.2 and 33% faster than Gemma 7b-it.*
- Deci-Nano provides the best price in comparison to the same group of models, at only $0.1 per 1M tokens.
- Featuring an 8k context window, Deci-Nano was trained on a mix of proprietary and public datasets and was preference-tuned using DPO.
In sum, Deci-Nano provides the best balance of quality, speed, and price, making it optimal for production.
Deci-Nano embodies our production-oriented approach which includes a dedication not only to model quality but also to efficiency and cost-effectiveness. Looking ahead, we anticipate the release of additional LLMs that promise to elevate this standard of excellence even higher.
To make our line of production-oriented LLMs available to as many businesses and developers as possible, we developed a platform that delivers on three critical fronts: high performance, exceptional control, and unmatched cost efficiency. Read on to learn more.
Deci-Nano Capabilities
We compare Deci-Nano to leading LLMs on both MT Bench and the Open LLM Leaderboard.
The following table (table 1) reports the performance of these models on MT Bench.
| Model | MT Bench average |
| Deci-Nano | 7.41 |
| Mistral 7B-Instruct-v0.2 | 7.39 |
| Llama 2 7B chat | 6.27 |
| Gemma 7b-it | 6.38 |
Table 2 presents the Open LLM Leaderboard scores of Deci Nano, Mistral-7b-instruct-v0.2 and Gemma 7b-it.
| Model | Average | Arc_challenge | Hellaswag | MMLU | TruthfulQA | WinoGrande | GSM8K |
| Deci-Nano | 70.76 | 69.11 | 85.88 | 60.86 | 63 | 81.06 | 64.67 |
| Mistral 7b-Instruct-v0.2 | 65.71 | 63.14 | 84.88 | 60.78 | 68.26 | 77.19 | 40.03 |
| Gemma 7b-it | 64.29 | 61.09 | 82.47 | 66.03 | 44.91 | 78.45 | 52.77 |
Deci-Nano Inference Performance
Deci-Nano demonstrates a significantly lower latency than comparable models, when benchmarked at BF16 precision on NVIDIA A100 GPUs. Latency for Mistral-7b-instruct-v0.2, Mistral-7b-instruct-v0.1, Gemma 7b-it and Llama 2 7B-chat is taken from the LLM perf leaderboard.
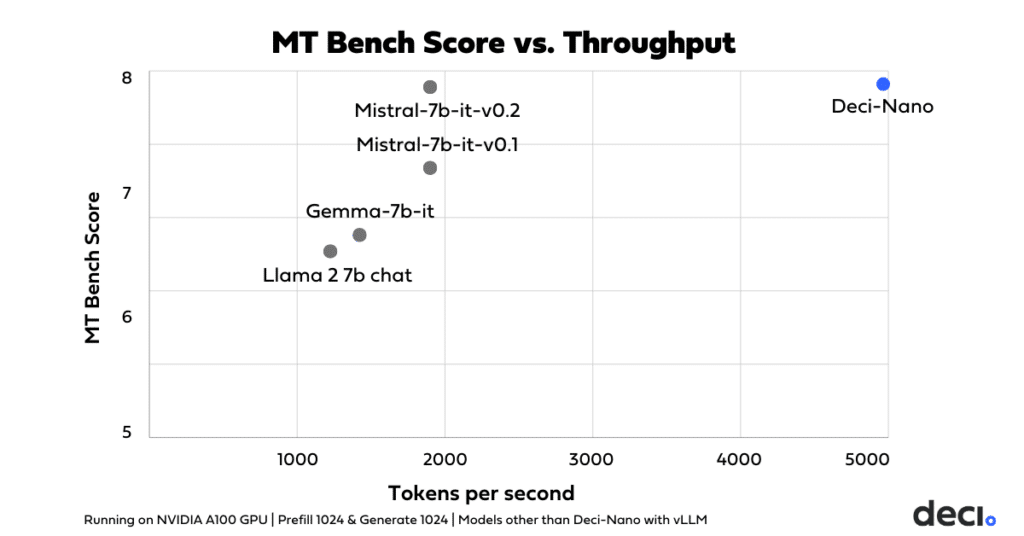
Deci-Nano delivers exceptional computational and memory efficiency, further amplified by Deci’s Infery- LLM for unparalleled throughput. When benchmarked at BF16 precision on NVIDIA A100 GPUs, Deci-Nano, paired with Infery LLM, demonstrates a significantly higher throughput than other models with vLLM, including Mistral-7b-instruct-v0.2, Mistral-7b-instruct-v0.1, Gemma 7b-it, and Llama 2 7B.
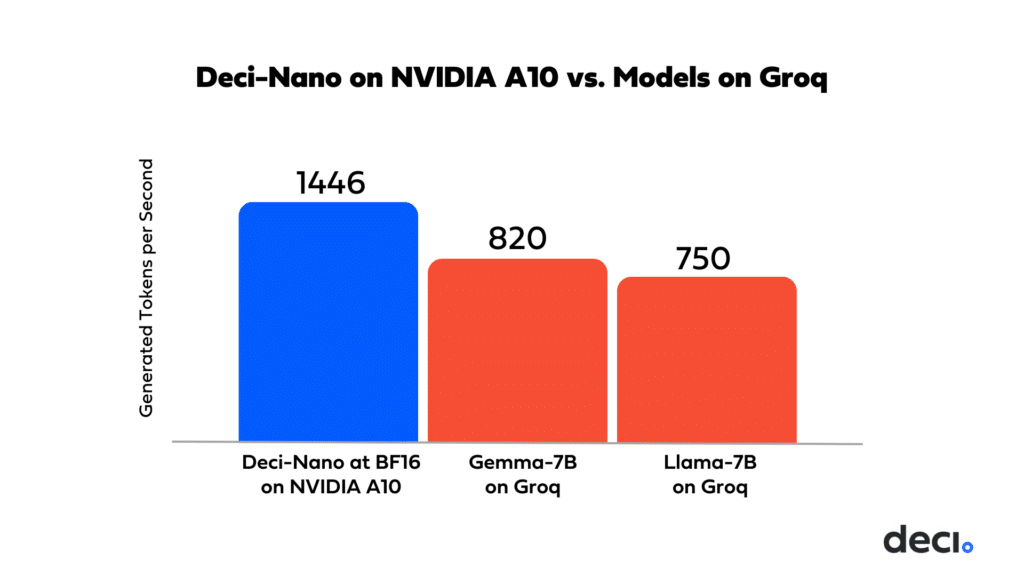
Additionally, Deci-Nano’s throughput on NVIDIA A10 GPU is higher than that of Llama 2 7B on Groq.
Just like with Deci’s open-source 7B parameter LLM, DeciLM, Deci-Nano’s predecessor, our neural architecture search engine, AutoNAC, played a crucial role in identifying an architecture that optimally balances model quality with efficiency.
Flexible Deployment Options
Deci-Nano and other supported models can be deployed through our Generative AI Development Platform in a number of ways:
- API: Choose between serverless instances for ease and pay-per-token pricing or dedicated instances for model fine-tunability and enhanced privacy. Our platform’s API is fully compatible with OpenAI API and features INT8 capabilities for a 2x reduction in latency.
- VPC Deployment: We offer both containerized deployment and managed inference options. Choose the former for hands-on control. Alternatively, managed inference within your Kubernetes cluster offers a hands-off solution, featuring model deployment, Infery acceleration and server management tailored to your requirements.
- On-Premises Deployment: Opt for this choice to integrate containerized models seamlessly into your data center. This option provides you with a container that houses both the model and the Infery SDK, enabling you to secure sensitive data within your own infrastructure while granting you complete control over the deployment process and infrastructure management.
This breadth of deployment flexibility is central to our offering, ensuring you can migrate between deployment options as you scale and your needs evolve, without the necessity to alter your chosen model.
Pricing, Cost Savings, and Sustainability
Our API pricing for Deci-Nano is $0.1 per 1M tokens.
By providing cost-efficient access to advanced LLMs, we enable businesses to expand their AI initiatives and extend their application’s reach without the constraints of high costs.
The enhanced throughput of our models means that deploying them in your own VPC yields greater efficiency per GPU hour, enhancing the value of your investment and allowing you to serve more users at once. For on-premises deployments, this higher throughput translates into energy savings, the opportunity to allocate your GPU to additional tasks, or an overall boost in your application’s productivity.
With Deci-Nano, you don’t need to be ‘GPU-rich’ or invest in pricey GPU alternatives to scale. Our software-only approach squeezes more power out of existing GPUs, leading to significant operational savings. Additionally, it reduces our environmental impact by lowering carbon emissions during training and inference phases.
How to Get Started with Deci-Nano and the Deci Gen AI Development Platform
Interested in experiencing Deci-Nano firsthand or exploring our range of supported models? We invite you to sign up for a free trial of our API.
For those curious about our VPC and on-premises deployment options, we encourage you to book a 1:1 session with our experts.
*Latency numbers for Mistral-7b-instruct-v0.2, Mistral-7b-instruct-v0.1, Gemma 7b-it, and Llama 2 7B are from the LLM perf leaderboard.








