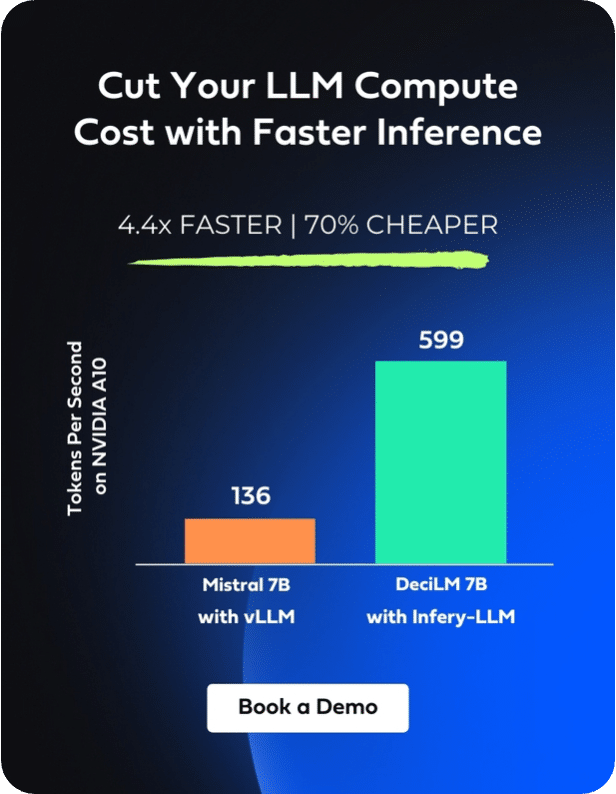
Research is one of the reasons why AI today is growing rapidly. It fosters innovation, enhances AI capabilities, addresses ethics, and discovers new applications.
According to the most recent AI Index Report, published annually by Stanford University, the increasing number of AI publications has more than doubled since 2010. Pattern recognition, machine learning, and computer vision continue to dominate the topics of AI research.
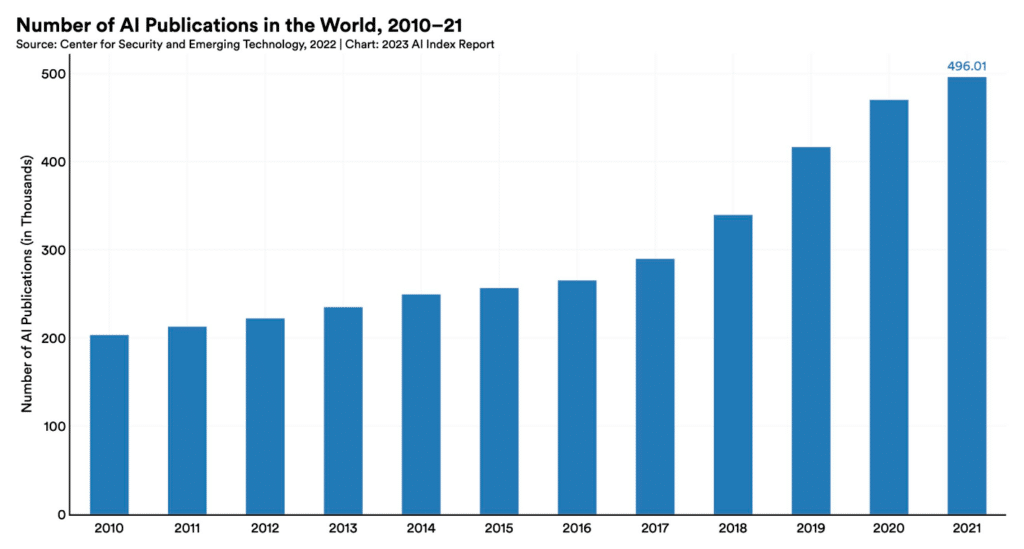
With thousands of AI publications that come out every year, it can be difficult for data scientists, machine learning engineers, and AI practitioners to keep up.
How do you stay up to date on trending papers and state-of-the-art in your subfields of interest? Do you have enough time to read it all? You can check proceedings of conferences for interesting titles, use an arXiv feed/recommender system, talk to the community for recommendations, or set up Google Scholar notifications.
Another way to stay on top of the latest AI papers is by following relevant people on social media, and that is what this blog is all about. Our DevRel Manager, Harpreet Sahota, reached out to three content creators who read, synthesize, and share key research in various AI subfields.
- Shubham Saboo is an AI evangelist, the author of two books, and a data scientist. He is currently the Head of DevRel at Tenstorrent Inc.
- Sebastian Raschka is a deep learning and AI researcher, programmer, author, and educator. Making AI and DL more accessible, he is the Lead AI Educator at Lightning AI.
- Cameron R. Wolfe, Ph.D. is the Director of AI at Rebuy. He is a researcher with an interest in DL and a passion for explaining scientific concepts to others.
Continue reading to see their insights into the work that they do and how it impacts the bigger AI community.
When you first approach a new research paper, what is your process for reading and understanding it?
Shubham: Reading a new research paper is a rewarding journey. I start with a quick skim of the title, abstract, and conclusion to get a feel for the paper’s theme. Next, I dissect the details, familiarize myself with new terms, and dive into a comprehensive reading. I take notes, critique the methods and results, and engage in peer discussions for deeper insight. Finally, I revisit the paper later, often finding fresh perspectives.
Sebastian: My approach in short: First, I start with the abstract. Then, I go over all the figures, looking at the figures and reading the captions. Next, I do the same thing with the tables. After getting this brief overview, I skim through the conclusion. I outlined it in more detail in “Study & Productivity Tips: Reading A Research Paper” here.
Cameron: I read the abstract, end of the intro, and methods, then look at the tables in the results/analysis section first. If that interests me still, then I’ll read the paper more in-depth.
After you’ve read the paper, what’s your process for breaking it down into more digestible content?
Shubham: To make complex research papers more digestible, I focus on identifying key points, understanding the audience’s technical level, and simplifying jargon. I then logically structure the content, often using visual aids like diagrams or infographics for clarity. After refining the content through several iterations, I aim to make it interactive and engaging, possibly with questions or quizzes. The aim is to make the research accessible and stimulating for everyone.
Sebastian: I focus on the main points: What did they do, and how does it compare to other approaches, and write a story around these.
Cameron: If I’m trying to write about a paper, I read it in multiple parts. First, I will read it without making any notes. In the next pass, I will make notes by underlining important points. After that, I will make an outline that identifies all key parts of the paper, then end with a certain number of takeaways that are important/unique to that paper.
How do you decide which research papers are worth reading and potentially sharing with your audience? What criteria do you use?
Shubham: I use the R.I.I framework to decide if the paper is worth reading or not:
- Relevance: The paper should align with my areas of interest and expertise, and it should be relevant to the interests of my audience.
- Innovation: The paper should present novel ideas, algorithms, or methodologies that push the boundaries of the current understanding of AI
- Impact: It should have potential real-world implications or contribute to the ongoing dialogue in the AI community.
Sebastian: I don’t think too hard about it. I share what I personally find interesting.
Cameron: I don’t have a criteria. I just read the papers that seem interesting/important to me.
Could you describe your personal knowledge management system? How do you organize, store, and recall information from the papers you read?
Shubham: Here’s how I handle it:
- Organizing: I categorize papers by topic, technique, or application. I use Google Scholar for managing and categorizing my research papers. They allow me to create folders for different topics and tag papers with keywords.
- Note-taking: For each paper I read, I create a summary document where I jot down the key points, insights, questions, and my own thoughts. I use Notion which lets me search my notes, create links between related notes, and access them from anywhere.
- Sharing: I share some of my notes and insights with the community through Twitter threads, which helps reinforce my understanding and allows me to receive feedback and other perspectives.
Sebastian: Lists! I have it outlined here.
Cameron: I don’t have a sophisticated approach. I use the notes app on my computer to keep a list of papers that I see, then I will pick papers from this list (or my Twitter bookmarks).
What tools or resources do you use to streamline the process of reading and summarizing research papers? How do you use them?
Shubham: Tools like ChatPDF, AskYourPDF, etc.
Sebastian: If you want to get something useful out of a paper, there’s no way around skimming and reading it yourself. Choose whatever reading method feels most comfortable for you: PDF reader, e-reader, or pen & paper.
Cameron: I don’t use any tools. I just read the papers and begin writing in substack after I’ve created a solid outline of what I want to write.
How do you ensure you accurately represent the findings of a paper while making it accessible to a broader audience?
Shubham: To accurately represent research findings while making them accessible, I thoroughly understand the paper first, then distill key points—problem, methodology, results, conclusion—for my audience. I translate technical jargon into simple language, often using metaphors and visual aids to clarify concepts. Before sharing, a peer review helps confirm accuracy. Afterward, I welcome audience feedback to correct potential misinterpretations and encourage discussion.
Sebastian: It’s critical to understand the paper.
Cameron: Typically, I write in a relatively in-depth fashion, which means that I don’t have to abstract too many details. I try to make sure that I understand the papers really well before writing, but I definitely make mistakes sometimes.
Could you share an example of a paper you’ve processed recently? Walk us through the steps from selection to publication.
Shubham: Let’s take the example of a paper I recently read titled “Deep Reinforcement Learning for Complex Decision Making with Multimodal Data.” My approach included an initial scan of the abstract and conclusion, revealing a focus on utilizing multimodal data in decision-making. I delved deeper to understand their proposed framework, the MDRL, and the experiments showcasing its efficacy. I selected the important details and took notes of them to convert into tweets that could be easily read and understood.
Sebastian: The link I outlined earlier walks through the reading process: “Study & Productivity Tips: Reading A Research Paper” here.
Cameron: My recent newsletter series was on open-source language models. As this research area developed, I wrote individual newsletters about notable contributions in this space (e.g., OPT, LLaMA, imitation models, Orca, …). After I had enough of these concepts covered, I will probably follow all of these writings with a survey article that combines them all together and explains the space of open-source LLMs as a whole.
Can you share a particularly successful piece of content or a time when you felt you really helped someone understand a complex AI concept?
Sebastian: (I hope) my latest newsletter issue summarizing computer vision concepts.
Cameron: My most successful piece of content in terms of views/reads was my advanced prompt engineering article. I think this article did well because:
- It was relatively simple to understand
- It was comprehensive (i.e., it covered needed background knowledge inside of the newsletter)
- It covered a lot of different papers in a single newsletter (these survey articles seem to do best)
- It covered a topic that’s interesting to a lot of people (even beyond AI experts)
Overall, this document was useful because there are a ton of papers on the topic of prompt engineering that adopt intricate/complex approaches. The article I wrote took a majority of these and explained them simply to the read, categorized them, and provided a clearer view of what’s currently out there.
What role do you believe content creators like yourself play in the AI community and broader public understanding of AI?
Shubham: Content creators like myself play a pivotal role in the AI community and in enhancing the broader public understanding of AI in several ways:
- Bridging the Gap: We bridge the gap between complex scientific research and the public by translating technical jargon into everyday language, making AI concepts accessible and understandable to a wider audience.
- Fostering a Community: By creating and sharing content, we foster a community of learners and practitioners, encouraging dialogue and collaboration, and promoting the exchange of ideas.
- Promoting Lifelong Learning: Through our content, we inspire curiosity and promote continuous learning, helping people stay abreast of the rapidly evolving field of AI.
- Advocacy: We play a crucial role in advocating for the ethical and responsible use of AI, educating the public about potential issues such as bias, privacy, and the social implications of AI technologies.
Sebastian: I hope I am helping with initiating discussions and exchanges of ideas of otherwise static content. Or in other words, I am hoping to share material that inspires readers to come up with new solutions, which enriches the field as a whole.
Cameron: Depends on the content creator. Personally, my role is in describing concepts to semi-technical audiences (e.g., investors, executives, beginners, etc.). Other content creators will be focused on those who are interested but not experts in AI. Others will be focused on AI experts. In any case, the role is to explain information clearly and accurately to whatever audience listens to you. Better knowledge of AI is never a bad thing, and hopefully, our community can demystify some of these ideas for people over time.
That is a wrap! What is your favorite tip that Shubham, Sebastian, or Cameron shared? If you’re interested in more content like this, be sure to follow Deci on Twitter here and join the Deep Learning Daily community on Discord here.