Editor’s Note: Originally published in August 2023, this post has been extensively updated to reflect the latest developments in open source LLMs.
Introduction
Open-source LLMs are no longer the inferior lesser choice for your projects. The release of Meta’s Llama model and the subsequent release of Llama 2 in 2023 kickstarted an explosion of open-source language models, with better and more innovative models being released on what seems like a daily basis.
With new open-source models being released on a daily basis, it may be hard to keep track. To help you navigate this dynamic terrain, we dove into the ocean of open-source possibilities to curate a select list of the most intriguing and influential models making waves in recent months. Here are the models we have chosen to spotlight for their unique contributions to the landscape:
- Qwen1.5
- Yi
- Smaug
- Mixtral-8x7B-v0.1
- DBRX
- SOLAR-10.7B-v1.0
- Tulu 2
- WizardLM
- Starling 7B
- OLMo-7B
- Gemma
- DeciLM-7B
For every model on the list, we offer an in-depth exploration that includes key details such as its architectural design, benchmark scores, licensing details, training datasets (where available), and interesting characteristics. Our findings are summarized in this table:
| Model/Model Family Name | Created By | Sizes | Versions | Pretraining Data | Fine-tuning and Alignment Details | License | What’s interesting | Architectural Notes |
| Qwen 1.5 | Alibaba Cloud | 0.5B, 1.8B, 4B, 7B, 14B, 72B | Base and chat | Undisclosed | Alignment with DPO | Tongyi Qianwen | Models excel in 12 languages; Qwen 1.5 72B Chat currently the top non-proprietary model on Chatbot Arena | Uses SwiGLU activation, attention QKV bias, GQA, and combines sliding window attention with full attention |
| Yi | 01.AI | 6B, 9B, 34B | Base and chat | A curated dataset of 3.1 trillion English and Chinese tokens derived from CommonCrawl through cascaded data deduplication and quality filtering | Base models underwent SFT using 10K multi-turn instruction-response dialogue pairs, refined through several iterations based on feedback | Yi Series Models Community License Agreement | Innovative data cleaning pipeline and data quality over quantity for fine tuning; 200k context window | SwiGLU activation, GQA, and RoPE |
| Smaug | Abacus.AI | 72B, 34B | Chat | 72B – same as Qwen 1.5 72B; 34B – same as Yi 34B | Alignment with Direct Preference Optimization-Postivie (DPOP) | 72B – Tongyi Qianwen;34B – Yi Series Models Community License Agreement | First model to surpass an average of 80% on Open LLM Leaderboard | 72B – same as Qwen 1.534B – same as Yi |
| Mixtral-8x7B | mistralai | 46.7B parameters, uses only 12.9B parameters per token | Base and instruct | Undisclosed | Undisclosed | Apache 2.0 | Sparse Mixture of Experts (MoE) model; MT Bench score of 8.3 | MoE using 8 Mistral-7B models |
| DBRX | Databricks | 132B parameters; uses only 36B per input | Base and instruct | Carefully curated dataset comprising 12T tokens from text and code data; employed curriculum learning strategies | Undisclosed | Databricks Open Model License | Fine-grained MoE model, using 4 out of 16 experts per input | Uses GLU, RoPE, and GQA; GPT-4 tokenizer |
| SOLAR-10.7B | Upstage | 10.7B | Base and instruct | Same as Mistral 7B (undisclosed) | Instruction tuning employed Alpaca-GPT4, OpenOrca, and Synth. Math-Instruct datasets; alignment tuning used Orca DPO Pairs, Ultrafeedback Cleaned, and Synth. Math-Alignment datasets | Apache 2.0 | Depth upscaling, starting with a Llama 2 7B architecture with Mistral 7B weights, adding layers to increase model depth, followed by continued pretraining | Depth upscaled Mistral 7B architecture |
| TÜLU v2 | Allen Institute for AI | 7B, 13B, 70B | Instruct and chat | Same as Llama 2 | SFT on the TULU-v2-mix dataset; DPO alignment on the UltraFeedback dataset | AI2 ImpACT Low-risk license | DPO significantly enhances model performance on AlpacaEval benchmark while maintaining performance on other tasks | Same as Llama 2 |
| WizardLM | WizardLM | 7B, 13B, 30B, 70B | Base and instruct | Same as Llama | Fine-tuning using the Evol-Instruct approach, which uses LLMs to generate complex instructions | Llama 2 Community License | Use of LLMs to automatically rewrite an initial set of instructions into more complex ones | Same as Llama |
| Starling 7B Alpha | Berkeley | 7B | Chat | Same as Mistral 7B | Trained from Openchat 3.5 7B using RLAIF and Advantage-induced Policy Alignment (APA) | LLaMA license | Use of Nectar dataset consisting of 3.8M GPT4 labeled pairwise comparisons to train a reward model; MT Bench score of 8.09 | Same as Mistral 7B |
| OLMo | Allen Institute for AI | 1B, 7B | Base, SF and instruct | Trained on Dolma using the AdamW optimized | SFT using the TULU 2 dataset followed by aligning with distilled preference data using DPO | Apache 2.0 | Release fosters collaborative research, providing training data, training and evaluation code, and intermediate checkpoints | SwiGLU activation, RoPE, and BPE-based tokenizer |
| Gemma | Google Deepmind | 2B, 7B | Base and instruct | 6T tokens of text, using similar training recipes as Gemini | SFT on a mix of synthetic and human-generated text and RLHF | Gemma Terms of Use | Instruct model uses formatter that adds extra information during training and inference | GeGLU activations, RoPE and RMSNorm; 2B uses MQA and 7B uses MHA |
| DeciLM-7B | Deci | 7B | Base and instruct | Undisclosed | LoRA finetuned on SlimOrca | Apache 2.0 | Use of Variable GQA and efficient architecture generated using NAS technology | SwiGLU activations, RoPE, and Variable GQA |
Download a PDF version of this table here.
Whether you’re a deep learning engineer seeking the next tool for your project, a team lead scouting the latest AI trends to stay competitive, or a company executive looking for a bird’s-eye view of the open-source AI landscape, this comprehensive guide is tailored for you.Read on to discover what’s transforming the open-source landscape in 2024. Explore the potential of these models, understand their diverse applications, and gain the insights needed to make informed decisions in this rapidly evolving field.
Qwen1.5
Developed by Alibaba Cloud, Qwen1.5 is a family of base and chat-tuned models, in a range of sizes including 0.5B, 1.8B, 4B, 7B, 14B, and 72B. Quantized versions are available for all size variants, encompassing both INT4 and INT8 GPTQ, as well as AWQ and GGUF quantized models.
Qwen1.5 models are built on the Transformer architecture, incorporating SwiGLU activation, attention QKV bias, Grouped Query Attention (GQA), and combining sliding window attention with full attention. They also use a tokenizer adapted to multiple natural and coding langauges.
Base Qwen1.5 models support 12 languages, including English, Chinese, Arabic, French, Vietnamese, Korean, Japanese, Spanish, Indonesian, Portuguese, Russian, and Thai.
All models support a context window of 32k.
Alignment
To enhance the instruction following capabilities of models in the Qwen 1.5 family and ensure their responses align closely with human preferences, the models were tuned using Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO) PPO.
Performance
Qwen1.5 base models exhibit robust performance at each model size across varied evaluation benchmarks, such as MMLU (5-shot), C-Eval, Humaneval, GS8K, and BBH.Qwen1.5-72B-Chat stands out for its impressive results in both human and LLM as judge evaluations.
Two widely recognized benchmarks, with advanced LLMs serving as judges, are MT Bench and AlpacaEval. Although it doesn’t quite match GPT-4-Turbo, Qwen1.5-72B-Chat still outperforms competitors like Claude-2.1, GPT-3.5-Turbo-0613, Mixtral-8x7b-instruct, and TULU 2 DPO 70B, and is comparable to Mistral Medium in both MT Bench and Alpaca-Eval v2 tests.
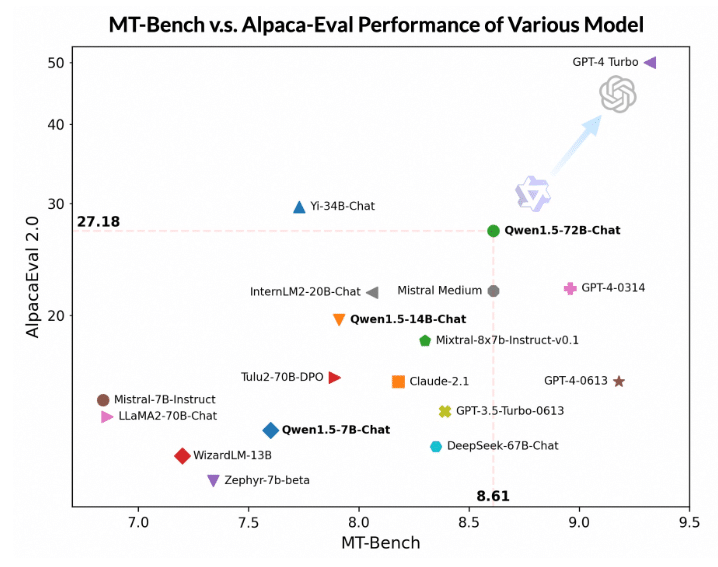
Qwen1.5-72B-Chat is currently the top non-proprietary model on the Chatbot Arena leaderboard, which ranks models on the basis of over 400K human preference votes.
The Elo score in Chatbot Arena is calculated through blind side-by-side comparisons where users interact with and vote on two anonymous models based on their performance. This method generates rankings based on human-chosen win rates, providing a quantifiable measure of each model’s relative skill and preference among users.
Connecting with External Systems
According to the technical blog published with the models’ release, Qwen1.5 Chat models show promising results in RAG benchmarks and tool-use evaluations, underscoring their versatility in executing function calls and utilizing external tools.
Yi
The Yi model series, developed by 01.AI, is available in three sizes: 6B, 9B, and 34B. Each offers a base model alongside a version fine-tuned for chat. The models support a context window of 200k.
The Yi model series employs a modified Transformer architecture. The modifications include
- The use of GQA for all model sizes, including the 6B
- The use of SwiGLU as the post-attention activation function, but with a unique adjustment: the activation size is reduced from 4h to 8/3h, where h represents the hidden size
- The use of RoPE, but with Adjusted Base Frequency (RoPE ABF) to support long context windows up to 200k
Data cleaning
Yi’s training data comprises 3.1T. High data quality was achieved through a data cleaning pipeline, designed to ensure high-quality input for both pre-training and fine-tuning phases.
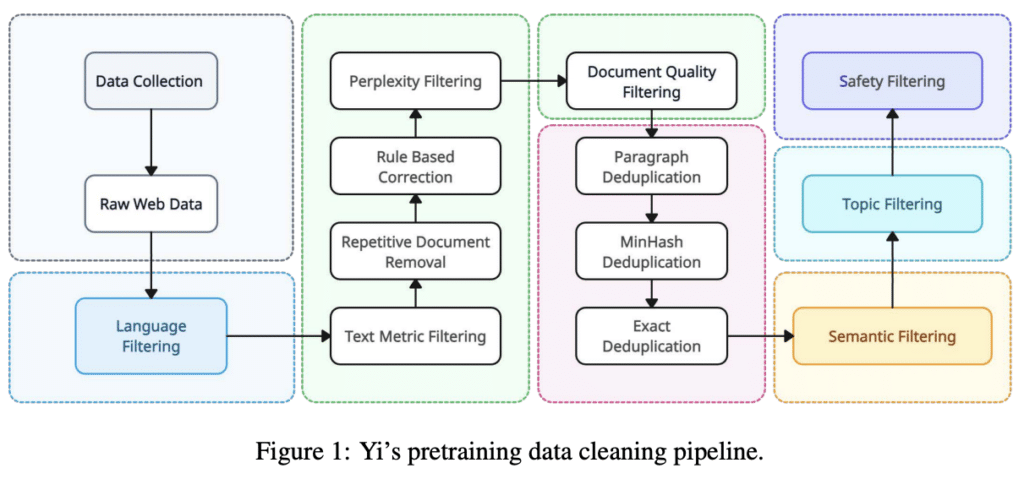
Yi’s data cleaning pipeline begins with web documents from Common Crawl, processed through the CCNet pipeline for language identification and initial quality assessment. It employs heuristic rules to eliminate low-quality or irrelevant text and anonymizes personal information. Learned filters tackle complex issues like inappropriate content, especially in Chinese texts, using scorers for perplexity, quality, safety, and coherence. Documents undergo unsupervised clustering for further quality control. Finally, an advanced deduplication process removes redundant content.
Finetuning
For fine-tuning, the Yi models utilize a dataset of fewer than 10K multi-turn instruction-response dialogue pairs that were refined through multiple iterations based on feedback. According to the accompanying technical report, this approach contrasts with the data-intensive approach of FLAN and UltraChat, “which scales the SFT [Supervised Finetuning] data to millions of entries but each of the entries may not have been examined carefully because the scale is too large.” The team implemented techniques to improve prompt diversity and response formatting, focusing on reducing hallucinations and repetitions. Efforts were made to ensure broad capability coverage, including creative writing and coding, through a diversity-focused sampling algorithm and an instruction tagging system.
Next word prediction loss was employed for finetuning with the AdamW optimizer.
The context length was expanded to 200,000 tokens through an additional phase of lightweight continual pretraining, leading to significantly improved performance in identifying relevant information within vast amounts of data.
Performance
According to the technical report, Yi-34B delivers close to GPT 3.5 performance.
As of March 2024, Yi-34B-Chat is number 18 on the Chatbot Arena leaderboard, tied with WizardLM-70B-v1.0, Tulu-2-DPO-70B, and GPT-3.5-Turbo-0125.
Smaug
Developed by Abacus AI, the Smaug series, including Smaug-34B-v0.1 and Smaug-72B-v0.1 models, was developed by Abacus.AI through a process of fine-tuning using DPO-Positive (DPOP), a variant of Direct Preference Optimization.
The distinctive aspect of DPOP lies in its novel loss function and training procedure designed to avoid a specific failure mode identified in DPO. DPO’s standard loss can inadvertently decrease the model’s likelihood of preferring the more desired outcomes if the relative probability between preferred and less preferred options increases. This issue is particularly pronounced when fine-tuning LLMs on datasets where the difference (edit distance) between pairs of potential completions is minimal.
DPOP addresses this by incorporating a new term into the loss function, which penalizes any reduction in the probability of positive (preferred) completions. This ensures that every token in the preferred completion is encouraged towards the desired outcome, effectively countering the identified failure mode of DPO.

Smaug-72B was finetuned directly from moreh/MoMo-72B-lora-1.8.7-DPO and is ultimately based on Qwen-72B.
Smaug-34B is a modified version of the base model Bagel-34B-v0.2, which itself is a Supervised fine-tuning version of Yi-34B-200k.
Performance
Smaug is the first open-source model to surpass an average score of 80% on the Open LLM Leaderboard. With a score of 80.48% it is still one of the top models on the leaderboard.
It should be noted that Smaug’s stellar performance on the Open LLM leaderboard is not surprising given that the Smaug models’ training incorporated datasets specifically tailored for enhancing the models’ performance on downstream tasks like GSM8K, ARC, and HellaSwag (three of the 6 research benchmarks included in the Open LLM leaderboard). For instance, GSM8K was expanded into MetaMath, providing step-by-step solutions to math problems. Dispreffered versions were created by introducing errors into one of the steps, with a relatively low edit distance of 6.5%.
Mixtral-8x7B
Developed by Mistral, the Mixtral-8x7B-v0.1 and its instruction-tuned variant feature a total of 46.7 billion parameters but utilize only 12.9 billion parameters per token.
Mixtral-8x7B’s architecture is a sparse Mixture of Experts (MoE). A Mixture of Experts (MoE) model consists of multiple specialized sub-models (experts) and a gating mechanism that decides which expert to activate based on the input. This architecture allows for more flexible and potentially more accurate modeling by leveraging the strengths of different experts for different types of data. In a sparse Mixture of Experts (MoE) model, the gating mechanism activates only a small number of experts for any given input, significantly improving computational efficiency while maintaining the model’s adaptability and performance.
Mixtral-8x has a 32k context window and is Apache 2.0 licensed.
Details regarding the training process for both the base and instruction-tuned versions of the model have not been made public.
The model supports English, French, Italian, German, and Spanish.
Mixtral-8x7B achieves an Open LLM Leaderboard average score of 68.47, while Mixtral-8x7b-instruct-v0.1 achieves an average score of 72.7.
Mixtral-8x7b-instruct-v0.1 achieves an MT Bench score of 8.32. In terms of human evaluation, it is tied with Claude-2.1, GPT-3.5 Turbo 0613 and Gemini Pro on the Chatbot Arena leaderboard. It is currently the highest ranked Apache 2.0-licensed LLM on both MT Bench and Chatbot Arena.
DBRX
Developed by Databricks, the 132B-parameter DBRX Base and its fine-tuned variant, DBRX Instruct, leverage an MoE architecture.
Unlike other open-source MoE models like Mixtral-8x7B and Grok-1, which utilize 2 out of 8 experts per input, DBRX models adopt a fine-grained MoE architecture, engaging 4 out of 16 experts for each input. With a total of 132B parameters and 36B active parameters for any given input, these models employ a larger number of smaller experts, resulting in 65 times more possible expert combinations. According to the development team, this significantly enhances the model’s quality.
The DBRX models employ RoPE, gated linear units (GLU), and GQA. They also use the GPT-4 tokenizer, noted for its large vocabulary and token efficiency.
DBRX Base underwent pretraining on 12T tokens of text and code, prioritizing data quality. The dataset is deemed at least twice as effective per token compared to that used for the MPT model family. Curriculum learning was incorporated during pretraining, modifying the data mix to significantly enhance model quality.
Performance
DBRX Instruct has an MT-Bench score of 8.39, surpassing Mixtral-8x7b-instruct-v0.1. Its average score on the Open LLM Leaderboard is 74.5%, exceeding Mixtral-8x7b-instruct-v0.1’s 72.7% average.
SOLAR-10.7B
SOLAR-10.7B-v1.0 was developed by Upstage AI, using an innovative approach called Depth up-scaling (DUS), which aims to enhance the model’s performance on various tasks without introducing the operational complexities often associated with other model scaling techniques, such as MoE.
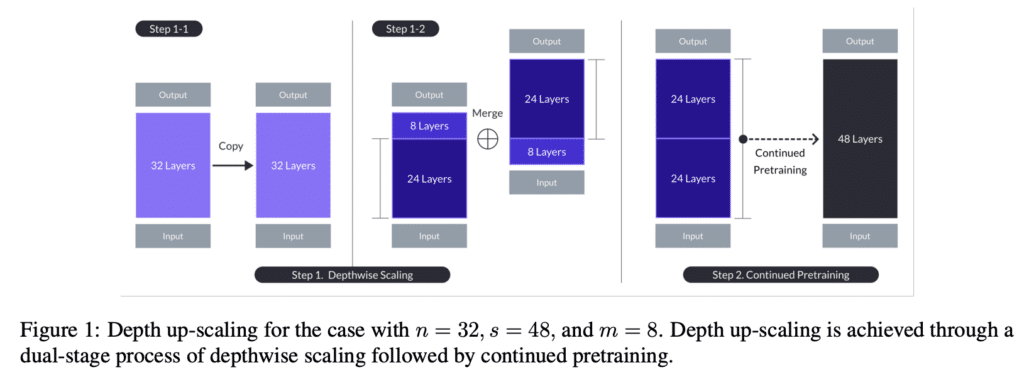
Depth Upscaling
The depth upscaling process starts with a 32-layer base model, (in the case of SOLAR-10.7B, Mistral 7B), which is then modified to expand its depth to a targeted layer count. The depth up-scaling involves duplicating the base model, removing layers from the duplicated base model and recombining it with the original base model to achieve the desired depth. Following this structural modification, the model undergoes a phase of continued pretraining, leveraging a carefully curated dataset. This step is crucial for adjusting the newly scaled model to maintain or enhance its performance, compensating for any initial drop due to the scaling process.
Finetuning
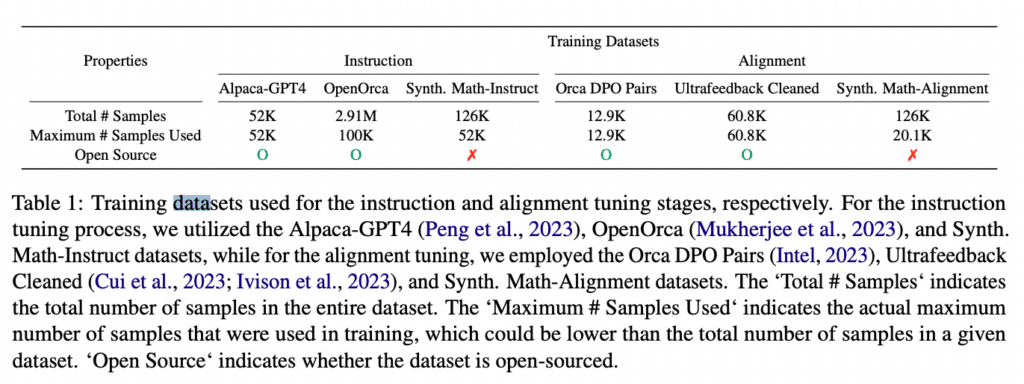
The model was fine-tuned to improve its ability to follow instructions in a question-and-answer format. This stage used a mix of open-source datasets along with a specially synthesized math QA dataset aimed at boosting the model’s mathematical abilities. Instruction tuning employed Alpaca-GPT4, OpenOrca, and Synth. Math-Instruct datasets.
Alignment
Following instruction tuning, SOLAR-10.7B-v1.0-instruct was aligned with human preferences using DPO. Alignment used Orca DPO Pairs, Ultrafeedback Cleaned, and Synth. Math-Alignment datasets.
Performance
SOLAR-10.7B-v1.0-instruct is currently number 30 on the Chatbot Arena leaderboard. It is useful as a strong base model but there are 7B instruct models with much better performance.
TULU 2
The TÜLU v2 models were developed by the Allen Institute for AI by fine-tuning and aligning Llama 2 models to various downstream tasks and user preferences. These models come in three size variants: 7 billion, 13 billion, and 70 billion parameters.
Finetuning
The Llama 2 models were fine-tuned on the TULU-v2-sft-mixture dataset, which consists of the following:
- FLAN: 50,000 examples from FLAN v2, focusing on diverse instructional scenarios.
- CoT: 50,000 examples from the CoT subset of the FLAN v2 mixture.
- Open Assistant 1: 7,708 high-quality conversational paths from Open Assistant, emphasizing natural dialogues and complex queries.
- ShareGPT2: All 114,046 examples to further enhance the model’s grounding in shared knowledge and reasoning.
- GPT4-Alpaca: 20,000 samples distilled from GPT-4 data for advanced reasoning capabilities.
- Code-Alpaca: 20,022 coding examples to bolster the model’s programming knowledge and problem-solving skills.
- LIMA: 1,030 carefully curated examples to introduce nuanced, high-quality instructional content.
- WizardLM Evol-Instruct V2: 30,000 examples of diverse and complex instructional scenarios.
- Open-Orca: 30,000 GPT-4-generated examples that augment FLAN data with model-generated explanations for a deeper understanding of instructional content.
- Science Literature: 7,544 examples covering various scientific document understanding tasks, such as QA, fact-checking, summarization, and information extraction, to enhance the model’s expertise in scientific domains.
- Hardcoded: 140 manually written samples to ensure accurate model responses to queries about its capabilities or origin.
This resulted in Tulu v2 7b, Tulu v2 13B, and Tulu v2 70b.
Alignment and performance
The latter models were then aligned with human preferences using DPO. This involved training on a filtered and binarized form of the UltraFeedback dataset over three epochs, using a notably low learning rate of 5 × 10^−7 to ensure stable and effective DPO training. This was found to significantly enhance model performance on open-ended generation evaluations, such as the AlpacaEval benchmark, across various model sizes without substantially impacting their capabilities on other tasks.
Tulu v2 DPO 70B, for example, achieves an MT Bench score of 7.89. It is tied with Yi-34B-Chat, WizardLM-70B-v1.0, and GPT-3.5-Turbo-0125 on the Chatbot Arena leaderboard.
WizardLM
WizardLM was developed by a research team from Microsoft. It is a series of models fine-tuned from Llama 7B, 13B, and 70B to follow complex instructions.
Finetuning
The fine-tuning process utilized a dataset created through a novel approach called Evol-Instruct. Evol-Instruct utilizes LLMs to autonomously generate open-domain instructions across a spectrum of complexity levels. It addresses the challenge of manually crafting such diverse and complex instruction sets, which can be both time-consuming and limited by human creators’ imagination and effort.
Evol-Instruct starts with an initial set of simple instructions and employs two strategies for evolution: in-depth evolving, which increases complexity through methods such as adding constraints or deepening content, and in-breadth evolving, which broadens topic and skill coverage by mutating instructions into new, diverse forms. This method also includes a response generation step for each evolved instruction and employs an elimination process to filter out unsuccessful evolutions. By iteratively applying these strategies, Evol-Instruct produces a large, varied instruction dataset that challenges LLMs, enabling significant performance enhancements on complex instruction-following tasks.
WizardLM models have a 4k context window.
Performance
In terms of performance, the WizardLM models demonstrate superior performance to some instruction models developed with human-generated instruction. WizardLM-70B-v0.1 even outperforms ChatGPT in certain high-complexity tasks, according to GPT4 automatic evaluation metrics.
In human evaluation, WizardLM-70B-v0.1 also does well. It is currently tied at number 18 with Yi-34B-Chat, Tulu v2 DPO 70B, and GPT-3.5-Turbo-0125 on the Chatbot Arena leaderboard.
Starling-7B
Developed by Berkeley researchers Banghua Zhu, Evan Frick, Tianhao Wu, Hanlin Zhu, and Jiantao Jiao, Starling-LM-7B-alpha is a 7 billion-parameter language model trained from Openchat 3.5 using Reinforcement Learning from AI Feedback (RLAIF). Starling-LM-7B-alpha achieves an impressive score of 8.09 on MT Bench, surpassing the performance of all models except for GPT-4 and GPT-4 Turbo at the time of its release. However, GPT-3.5 has since surpassed it.
Ranking Dataset
Training began with the creation of a GPT-4 labeled ranking dataset, Nectar. Nectar is composed of 183K chat prompts, each including 7 responses given by various models, including GPT-4, GPT-3.5-instruct, Mistral-7B, and Llama 2 7B, resulting in 3.8M pairwise comparisons. Special attention was paid to overcoming inherent positional bias in GPT-4-based rankings. By inducing GPT-4 to conduct pairwise comparisons before compiling a 7-wise ranking, the team was able to moderately reduce this bias.

Reward Model
The Nectar ranking dataset was then used to train a reward model, Starling-RM-7B-alpha. This step involved utilizing a K-wise loss function under the Plackett-Luce model for 7-wise comparisons, marking a departure from traditional cross-entropy loss used in pairwise comparison conversion.
Policy Finetuning
OpenChat 3.5 was selected as the base model for policy finetuning because of its high MT Bench score. The method used for policy finetuning was Advantage-induced Policy Alignment (APA) (as opposed to DPO or Proximal Policy Optimization (PPO)).
Performance
Starling-LM-7B-alpha, evaluated on MT Bench and AlpacaEval, showed improved helpfulness and safety but exhibited minor regressions in tasks involving reasoning or mathematics. Despite its advancements, the model’s basic capabilities, such as knowledge-based QA and coding, remained static. This suggests that while RLAIF significantly refines response style, it does not inherently enhance the model’s core competencies.
OLMo
Developed by the Allen Institute for Artificial Intelligence (AI2), the OLMo language models were released as part of an initiative to advance the science and study of large language models. The release included not only the model weights, but also the training data, training and evaluation codes, and a wealth of intermediate model checkpoints. This initiative marks a significant departure from previous models that limited their openness to weights and inference codes, aiming to foster a more collaborative and transparent research environment.
Like most of the model architectures discussed so far, OLMo’s is a decoder-only Transformer architecture enhanced with SwiGLU activation for efficient processing and Rotary Positional Embeddings (RoPE) for contextual awareness. It also features a redesigned BPE-based tokenizer that reduces the risk of encoding personally identifiable information.
Pretraining
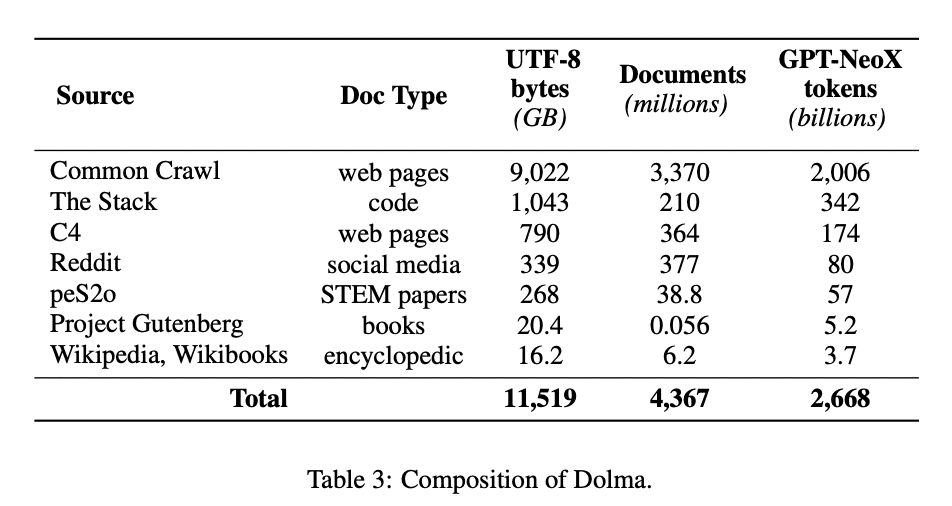
The 7 billion and 1 billion parameter models were trained on Dolma, which comprises 3T tokens across nearly 5B documents acquired from 7 different data sources accessible to the general public.
Finetuning and alignment
OLMo-7B-SFT and OLMo-7B-Instruct are versions of the OLMo-7B model that have been enhanced through specialized training. OLMo-7B-SFT underwent supervised fine-tuning using the Open Instruct framework and TULU 2 dataset, which improved its performance on complex reasoning tasks like MMLU and TruthfulQA, as well as on safety datasets like ToxicGen. This fine-tuning adjusted the model with slightly different hyperparameters compared to those used in the base Llama 2 models. Following this, OLMo-7B-Instruct was further trained with Direct Preference Optimization (DPO) to align more closely with human preferences.
Performance
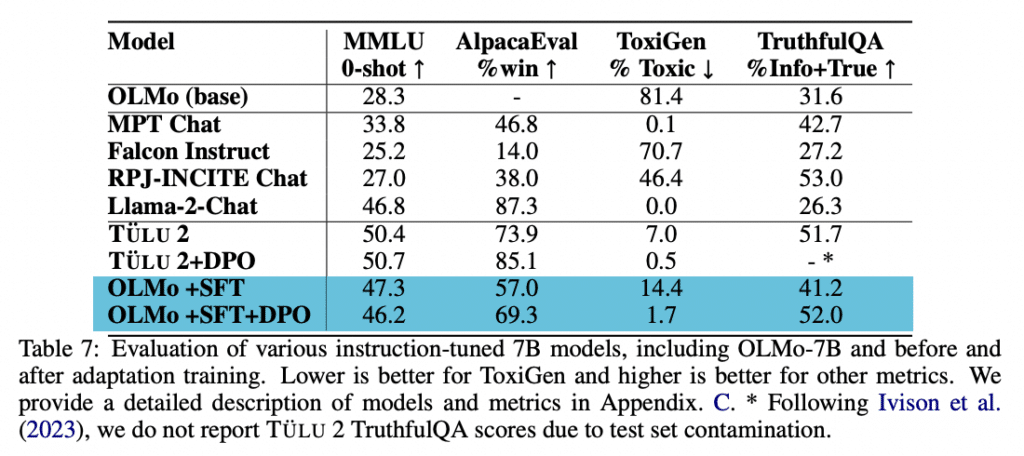
OLMo-7B demonstrates competitive performance across a range of tasks, matching or even surpassing counterparts like Llama 2 on certain evaluations.
OLMo-7B-Instruct, after undergoing fine-tuning and Direct Preference Optimization, shows notable improvements in reasoning tasks such as MMLU and achieves better safety metrics on datasets like ToxicGen, evidencing its quick adaptation to complex requirements and heightened safety.
Gemma
Developed by Google DeepMind, Gemma is a family of models based on research and technology used to develop Google’s Gemini models. Available in two sizes – 2 billion and 7 billion parameters – the models were further finetuned using SFT and RLHF.
The Gemma models’ architecture is built on the Transformer architecture. The 7B model uses Multi-head Attention (MHA) and the 2B model uses Multi-query Attention (MQA). They both employ GeGLU activations, RoPE embeddings, and RMSNorm. The models have a context window of 8192 tokens.
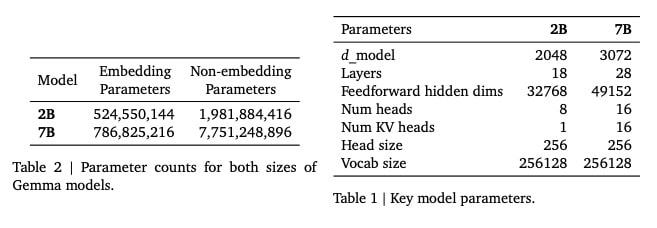
The Gemma 2B and 7B models were trained on 2 trillion and 6 trillion tokens, respectively, sourced from web documents, mathematics, and code, primarily in English. Training did not focus on multimodal or multilingual tasks. A subset of the SentencePiece tokenizer was used with a vocabulary size of 256,000 tokens. The training data underwent rigorous filtering to remove unsafe content and personal information, and to prevent dataset contamination.
Finetuning and alignment
The Gemma 2B and 7B models were instruction-tuned using a two-stage process: supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). SFT involved training on a mix of synthetic and human-generated text, focusing on English, and was optimized through LM-based evaluations for capabilities like instruction-following and safety. Filtering removed unsafe or low-quality content. RLHF further refined the models by training a reward function based on human preferences and optimizing policy with techniques to mitigate reward hacking.
The instruction-tuned models, Gemma-2b-it and Gemma-7b-it, utilize a specific formatter that adds extra information to all examples during both training and inference, serving two main purposes: indicating conversational roles and distinguishing conversation turns with special control tokens. Without this formatter, generations may be coherent but are considered out-of-distribution for the model, potentially leading to inferior output.
Performance
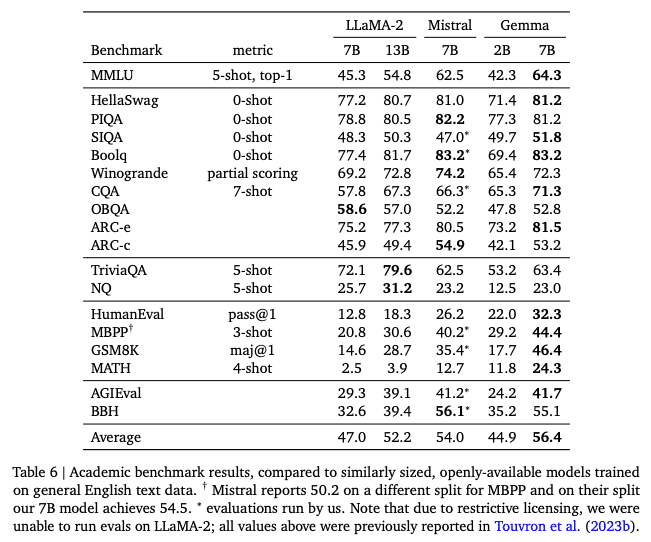
The Gemma base models outperform comparably sized models in 11 out of 18 standard text-based tasks. The models excel particularly in mathematics and coding, achieving high scores in GSM8K and MATH benchmarks.
DeciLM-7B
Developed by Deci AI, DeciLM-7B is notable for its high efficiency and speed. The model features an 8192 context and is a decoder-only transformer using SwiGLU activations, RoPE embeddings, and an innovative version of GQA known as Variable GQA. Unlike GQA, where the number of query groups is the same across all transformer layers, variable GQA features a different number of query groups across layers.
Use of neural architecture search
DeciLM-7B was developed using Deci’s neural architecture search technology, AutoNAC. AutoNAC was instrumental identifying the optimal number of groups per transformer layer for achieving the best balance between model quality and inference speed.
Finetuning
DeciLM-7B underwent instruction tuning with LoRA on the SlimOrca dataset, resulting in DeciLM-7B-instruct.
Performance
At the time of its release, DeciLM-7B was the top commercially licensed base 7B model on the Open LLM Leaderboard.
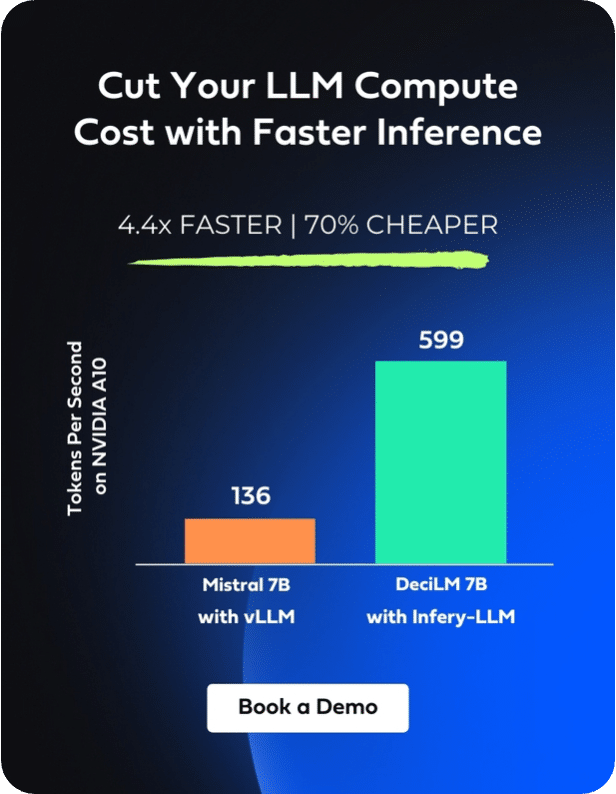
Combined with the Infery-LLM SDK, DeciLM-7B achieves a throughput that surpasses Mistral 7B with vLLM by 4.4 times and Llama-2-7B with vLLM by 5.8 times on NVIDIA A10 GPUs.The synergy between DeciLM-7B and Infery-LLM’s suite of advanced optimization techniques, including selective quantization, optimized beam search, continuous batching, and custom kernels, enables high-speed inference even at high batches. This enhancement is pivotal for use cases requiring high-volume, real-time interactions.
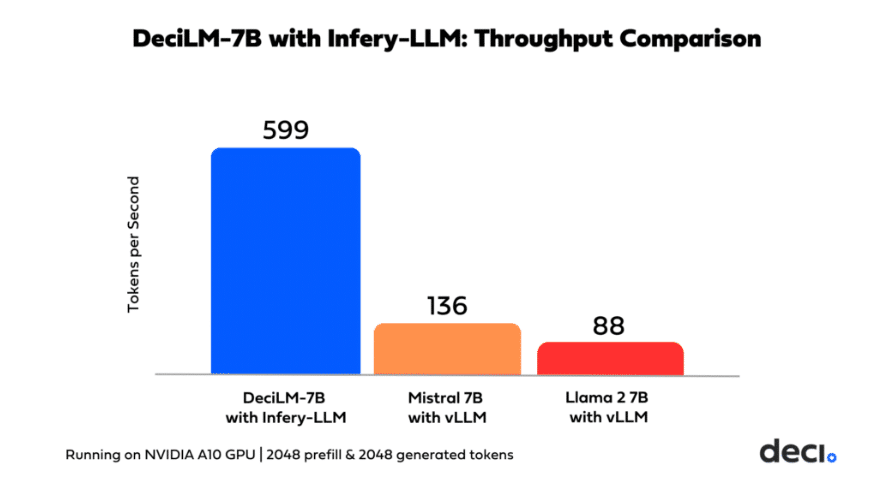
Deci has recently launched its GenAI Development Platform, featuring high-performance LLMs and flexible deployment options. One of the featured models is Deci-Nano, which outperforms both Mistral-7b-instruct-v0.2 and Gemma-7b-it on MT Bench, while being much faster.
To experience Deci-Nano firsthand we invite you to sign up for a free trial of our API. For those curious about Deci’s VPC and on-premises deployment options, we encourage you to book a 1:1 session with our experts.