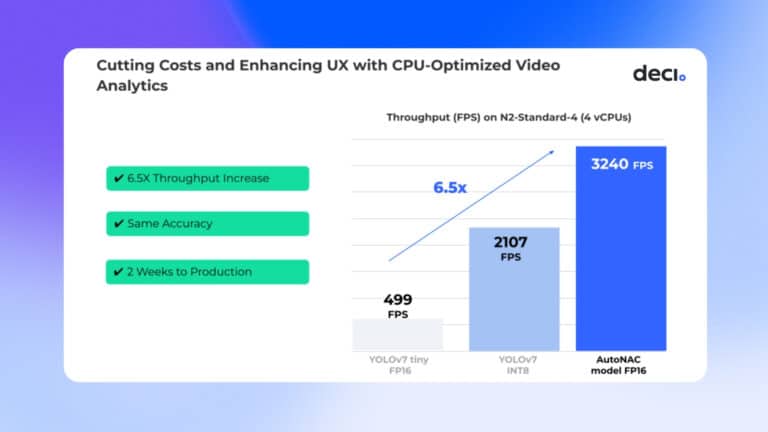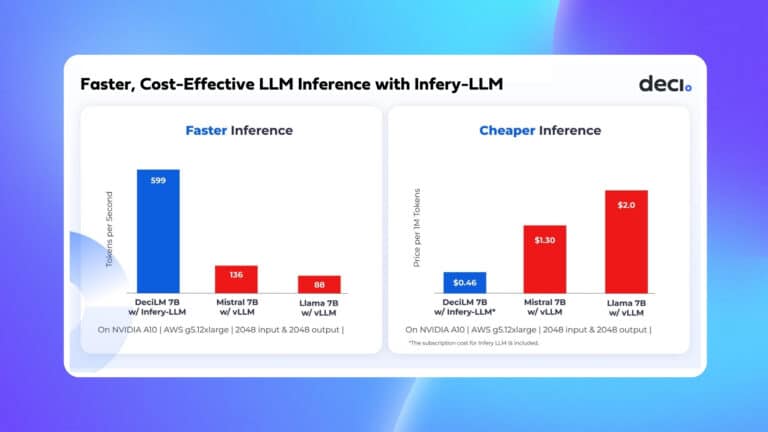
Introduction
The Qualcomm Snapdragon suite is a powerhouse for edge deployment of AI models. But to get these models running on Snapdragon SoCs, there’s a crucial step: quantization. Using the standard method with Snapdragon Neural Processing Engine SDK (SNPE) leads to a drop in the accuracy of some of the most popular object detection models, including YOLOv8 and YOLO-NAS.
This challenge, however, is not insurmountable. SNPE supports a range of advanced post-training quantization (PTQ) techniques that mitigate these accuracy losses. In this blog, we’ll review these advanced methods in depth. Additionally, we will share our own optimal quantization recipe using SNPE, which combines several techniques to deliver impressive results.
Qualcomm Snapdragon processors
Let’s kick things off with a brief overview of Qualcomm Snapdragon processors.
The Qualcomm Snapdragon family of SoCs is designed for a diverse array of devices—from smartphones to in-vehicle systems. Each SoC integrates a CPU and GPU. But it’s the addition of a digital signal processor (DSP) that really enhances its capabilities. This DSP allows for real-time signal processing and more efficient AI model inference compared to using just the main CPU or GPU.
A key highlight of the Snapdragon series is its AI accelerators. These boost computing power and efficiency, enabling devices to tackle complex tasks swiftly and accurately. Connectivity is essential in modern IoT, and Qualcomm excels here, too. The hardware supports 5G, Wi-Fi, and other advanced connectivity options, making it a cornerstone for innovative IoT applications.
Snapdragon Neural Processing Engine (SNPE) SDK
SNPE is an SDK for optimizing and deploying deep learning models directly on devices equipped with Qualcomm Snapdragon processors. This on-device processing capability not only reduces latency but also sidesteps the need to rely on cloud computing for AI tasks, which can enhance privacy and responsiveness.
SNPE provides support for various quantization techniques. However, using it to quantize YOLO object detection models is a significant challenge. Before we delve into this challenge, let’s review the basics of quantization. This will help us understand the more advanced strategies we’ll discuss later.
Quantization
Quantization is the process of reducing the number of bits used to represent the numerical values, such as activations and weights, in neural networks from standard floating-point precision to lower bit widths.
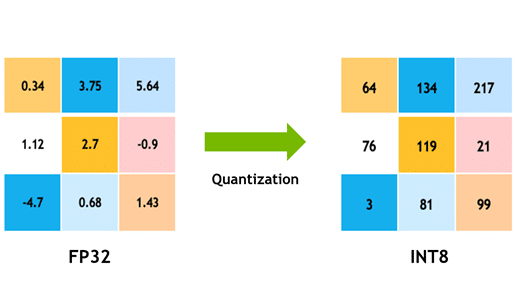
By adopting lower bit widths, quantization allows for a more compact representation of tensors, which decreases both memory demands and computational requirements. The transition from FP32 (32-bit floating point) to INT8 (8-bit integers) involves using scale and offset parameters. These parameters are crucial as they are determined during the quantization process to minimize errors associated with compressing the network’s weights and activations.
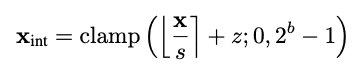
The main sources of quantization error include rounding errors and clamp errors. Rounding errors occur when continuous float values are converted to whole integers. Clamp errors happen when values exceed or fall short of the dynamic range of INT8. These errors can significantly impact the accuracy of a neural network. Therefore, refining and optimizing the quantization process is essential to preserve model accuracy while enhancing efficiency.
When to Employ Quantization
Quantization becomes a priority in several key scenarios:
1. Runtime Performance: If you’re facing issues such as high latency or low throughput during model operation, quantization can help streamline processes and speed up execution.
2. Memory and Size Constraints: Quantization reduces the memory footprint and overall size of models, which is crucial when storage or bandwidth is limited.
3. Hardware Limitations: Quantization is vital on edge devices, where power consumption needs to be minimized, and certain hardware may only support specific data formats. For example, in Qualcomm Snaprdragon devices, the SNPE DSP and AI accelerator specifically require models to be in the INT8 format to function properly.
Quantization is thus not just an option but a necessity in many contexts to ensure that deep learning models perform optimally on various devices, particularly when dealing with the constraints of edge AI.
The Impact of Standard Quantization on YOLO Model Performance in Qualcomm Snapdragon Platforms
In YOLO object detection models, key components like the prediction and decoding heads are particularly sensitive to INT8 quantization. This sensitivity necessitates careful application of quantization techniques.
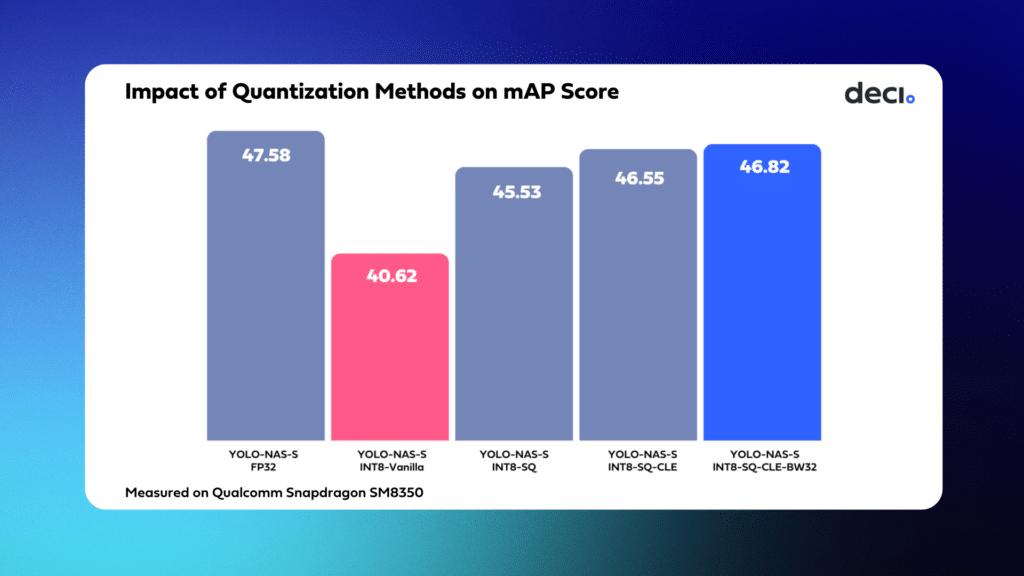
Standard or ‘vanilla’ quantization using the SNPE SDK presents significant challenges in maintaining the mean Average Precision (mAP) score of YOLO models. For example, our application of vanilla quantization on the YOLO-NAS-S model resulted in a 6.96% drop in the mAP score.
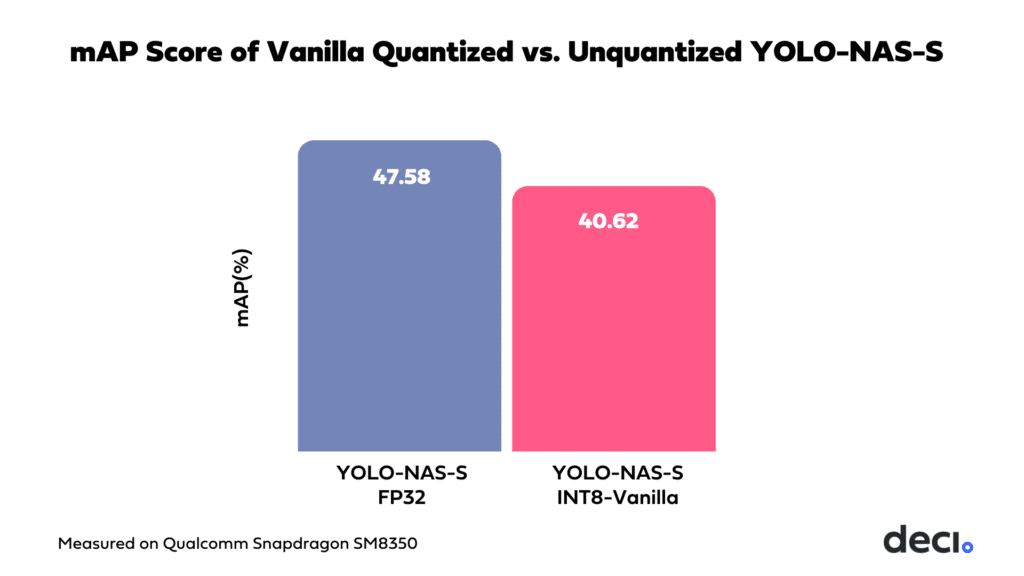
This decline in performance is consistent across other models in the YOLO series, such as YOLOv8, highlighting the broader implications of using basic quantization approaches on Qualcomm Snapdragon platforms.
Advanced SNPE Quantization Techniques
Selective Quantization
Selective quantization allows us to strategically exclude certain weights and activations from the typical INT8 quantization, opting instead to process them at higher bitwidths such as 16 or 32. This approach is particularly useful for preserving the integrity of sensitive layers, thereby helping to recover any accuracy losses typically associated with full quantization.
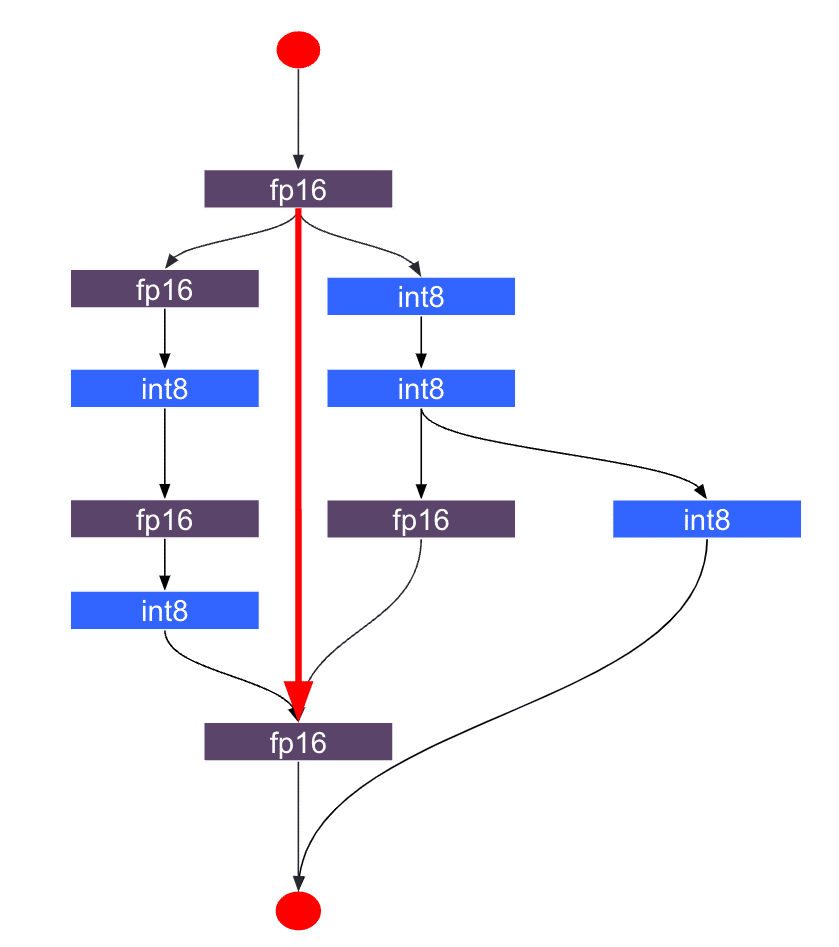
As we increase the number of layers exempted from INT8 quantization, we generally see an improvement in model accuracy. However, this comes with a trade-off: the more layers we exclude from INT8, the greater the impact on the model’s latency performance. It’s important to balance these factors based on the specific requirements of the application.
Selective Quantization with SNPE
The SNPE DSP backend supports selective quantization, although this capability can vary depending on the DSP version.
To optimize this process, we utilized AI Model Efficiency Toolkit (AIMET), a Qualcomm library that offers advanced model quantization and compression techniques. Using AIMET, we analyzed and built selective quantization configurations that maintain the best accuracy/latency trade-off.
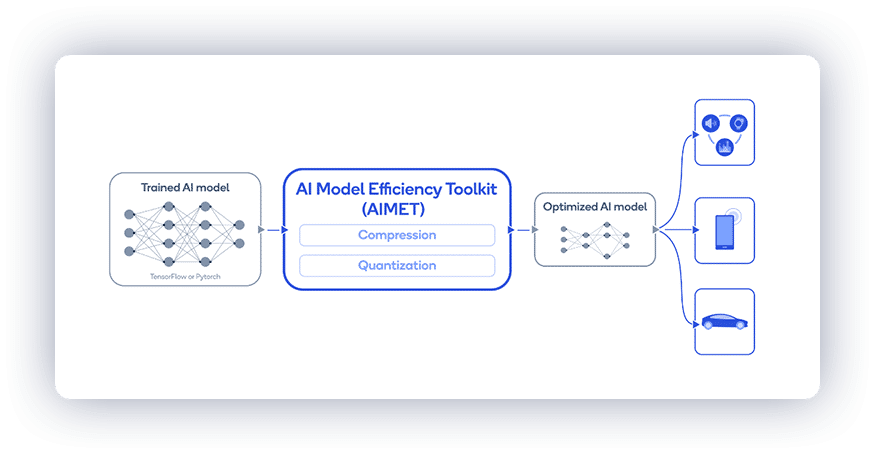
We then export the quantization encoding parameters in a JSON format compatible with the SNPE SDK. These parameters override SNPE’s standard quantization settings, allowing us to apply custom INT8 quantization techniques tailored to the model’s needs.
Cross-Layer Equalization
Cross-Layer Equalization (CLE) is a PTQ method designed to make model weights more amenable to INT8 quantization. It’s implemented through the AIMET library, specifically on PyTorch FP32 models, and focuses on adjusting the ranges of convolution weights by capitalizing on the scale-equivariance property of activation functions.
When examining the weight range per output channel in a model’s convolution layers, it’s common to find significant variance across channels. This variance complicates the process of selecting appropriate scale and offset parameters that accurately represent the dynamic range of the entire tensor. CLE addresses this issue by balancing weight ranges across channels.
The method involves identifying sequences of consecutive convolution layers. By leveraging the scale-equivariance property of activation functions, CLE can adjust the scale factor of weights in one convolution layer relative to the subsequent layer. This adjustment helps standardize the weight scales across layers, facilitating a more uniform approach to quantization.
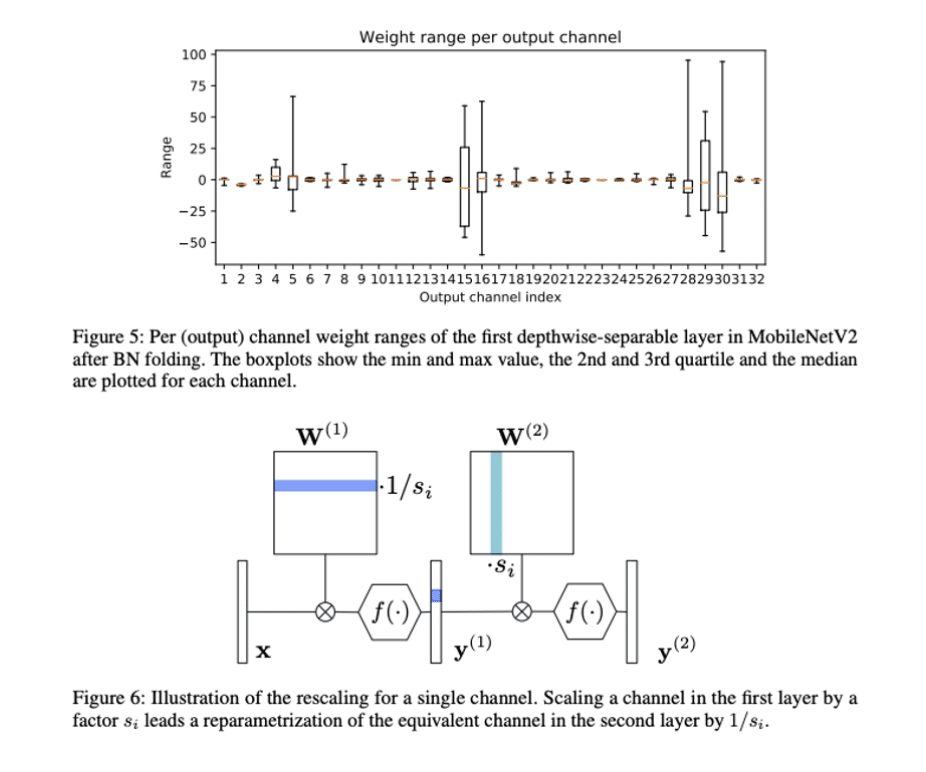
Importantly, applying CLE to a model does not alter the model’s FP32 accuracy but is generally effective in enhancing the performance of the INT8 version.
Bias bitwidth with SNPE
According to the SNPE documentation, the default quantization bitwidth for both weights and biases in the SNPE SDK is set at 8 bits. However, developers have the option to override this setting and specify a 32-bit width for biases using the command line option “-bias_bitwidth 32.”
Utilizing a 32-bit bitwidth for biases can potentially lead to improvements in model accuracy, although predicting which models will benefit from this adjustment can be challenging. Based on our empirical observations, models that use a 32-bit bias bitwidth generally show improved accuracy or maintain their current levels of performance.
Moreover, when it comes to latency performance, there appears to be no significant difference between using an 8-bit or a 32-bit bias bitwidth. This suggests that opting for a higher bitwidth for biases does not adversely affect the speed of model execution, making it a viable option for those looking to optimize model accuracy without sacrificing performance.
Other Quantization Methods Supported by SNPE
SNPE supports additional quantization methods:
1. SNPE Enhanced Quantizer: This method can be employed in specific scenarios where a slight enhancement in accuracy is required. It’s designed to fine-tune the quantization process to potentially yield better model performance, though the improvements are generally marginal.
2. Activation Bit-width 16: Retaining activation intermediates at 16 bits instead of the lower 8 bits can potentially improve model accuracy. However, this increase in bit width can adversely affect the model’s latency performance. This method might be considered when accuracy is prioritized over response time, but it’s essential to evaluate the trade-offs carefully.
Our Recommended SNPE Quantization Recipe for YOLO Models
To achieve the best balance between accuracy and speed when quantizing YOLO models with SNPE, we employ a sequence of advanced quantization techniques supported by the SDK.
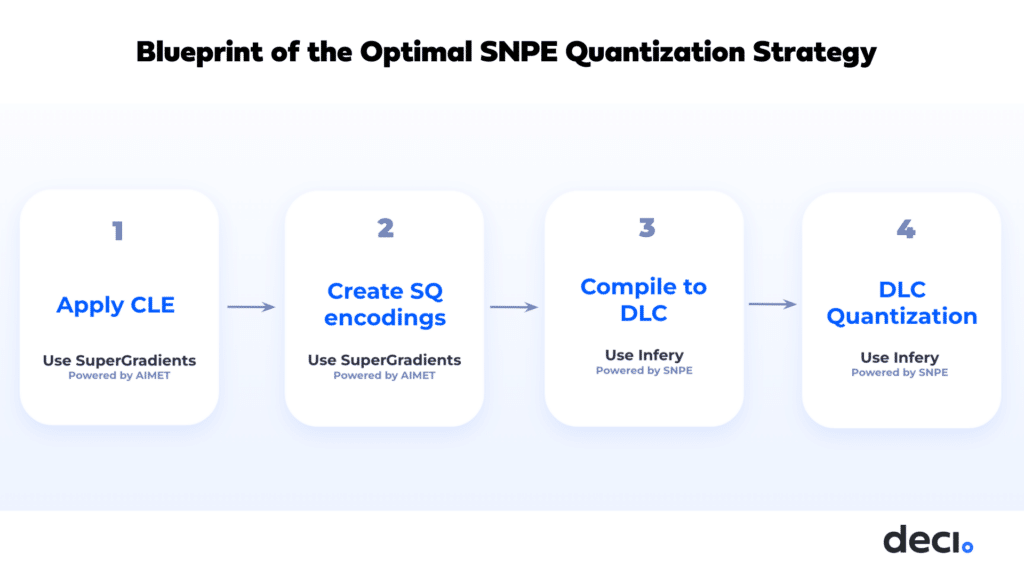
- First, we apply CLE. For this, we utilize SuperGradients, Deci’s open-source training library for PyTorch deep learning models. SuperGradients offers various data loaders for different datasets and incorporates best practices for constructing models that are INT8-friendly. We use the AIMET tools as a third-party library to facilitate the CLE application.
- Next, we create selective quantization encodings. This step is informed by our extensive analysis and prior knowledge.
- Following this, we compile our model from Pytorch to the framework neutral deep learning container (DLC) format, which is the official container format for the SNPE SDK. We employ Infery, Deci’s optimization and inference SDK for this step.
- Finally, we perform the last step of quantization using the DLC framework to produce the INT8 quantized model. This systematic approach ensures that our YOLO models are not only efficient but also maintain high performance standards post-quantization.
Results of our Recipe for YOLO Models on Qualcomm Snapdragon
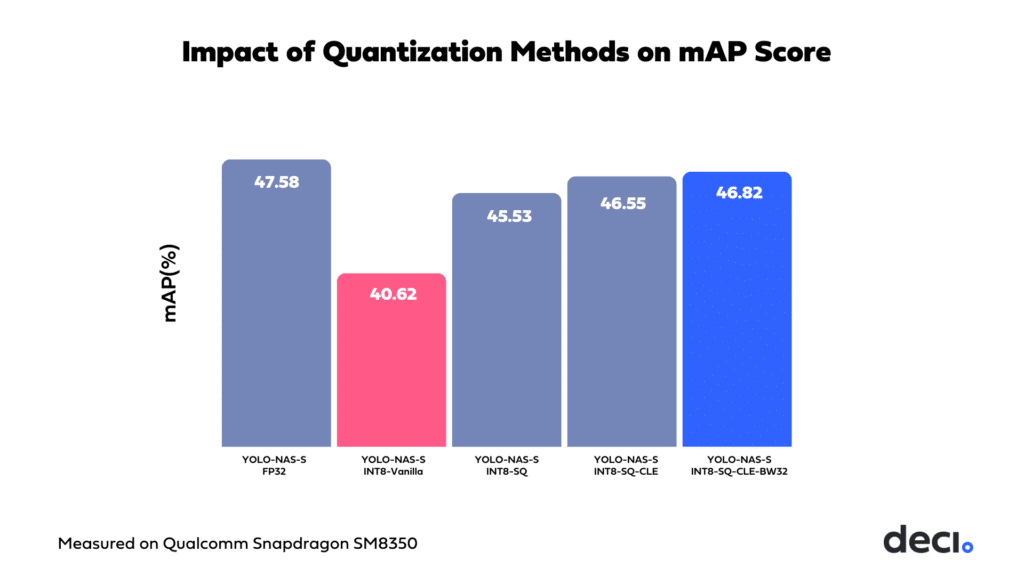
- Selective Quantization: By applying selective quantization alone, we are able to recover 5 mAP points.
- Cross-Layer Equalization (CLE): Adding CLE contributes an additional 1 mAP point.
- Bias Bitwidth Adjustment to 32: Finally, adjusting the bias bitwidth to 32 brings an additional improvement of 0.3 mAP, narrowing the accuracy gap to only a 0.8 mAP drop compared to the unquantized model.
We applied this quantization recipe across all YOLO-NAS variants and compared the results with those from the vanilla quantized models.
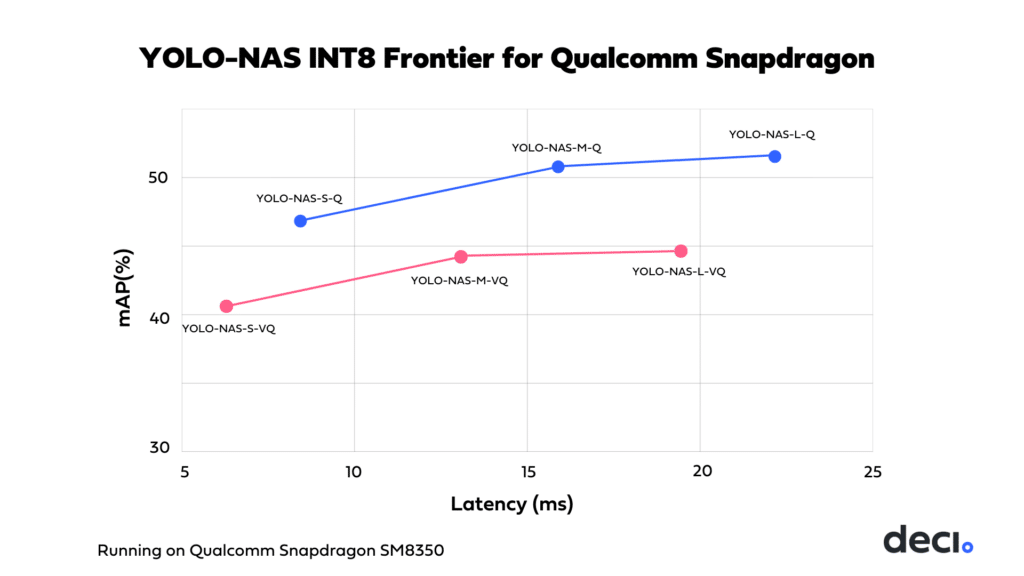
In the above graph, the vanilla quantized YOLO-NAS models are represented by the red dots and the ones quantized with our recipe are represented by the blue dots. The results clearly show a slight shift to the right, indicating a minor slowdown in the models. Despite this, the models quantized with our recipe are decidedly superior, offering much greater accuracy with only a marginal reduction in speed. This balance of accuracy and efficiency underscores the effectiveness of our tailored approach in optimizing YOLO models on Qualcomm Snapdragon platforms.
Wrapping Up
In this blog, we saw that while quantization is a challenge when deploying YOLO models on Qualcomm Snapdragon devices, it is not an insurmountable one. SNPE supports advanced quantization techniques such as selective quantization and CLE. By applying our SNPE quantization recipe alongside the Infery SDK, we’re able to combine these methods to reach INT8 speed while maintaining near FP32 accuracy.
If you’re eager to push the limits of what’s possible on Qualcomm Snapdragon or other edge devices, we invite you to talk to our experts about Deci’s foundation models and Infery SDK.
CTA: Book a Demo