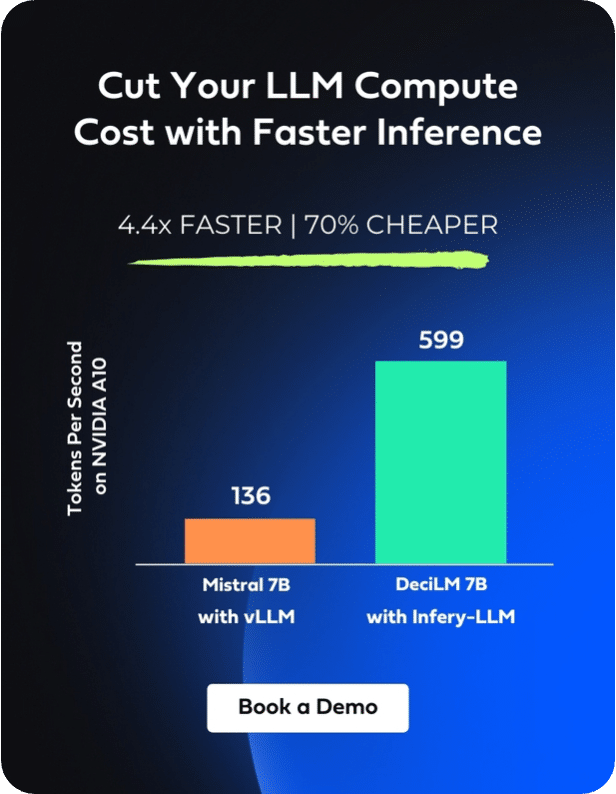
Today we introduce DeciCoder, our 1B-parameter open-source Large Language Model for code generation. Equipped with a 2048-context window, the permissively licensed DeciCoder delivers a 3.5x increase in throughput, improved accuracy on the HumanEval benchmark, and smaller memory usage compared to widely-used code generation LLMs such as SantaCoder.
DeciCoder’s unmatched throughput and low memory footprint enable applications to achieve extensive code generation with the same latency, even on more affordable GPUs, resulting in substantial cost savings.
At Deci, we’re obsessed with AI efficiency. We’ve been empowering AI teams to achieve unparalleled inference speed and accuracy with our advanced tools and deep learning foundation models. Now, we’re extending our core technology and expertise into the realm of generative AI.
DeciCoder is just the beginning. As we prepare to unveil a new generation of high-efficiency foundation LLMs and text-to-image models, developers can also eagerly anticipate our upcoming generative AI SDK. This suite, loaded with advanced tools, promises to redefine Gen AI fine-tuning, optimization, and deployment, offering unparalleled performance and cost efficiency to small and large enterprises alike.
When combining DeciCoder with our LLM inference optimization tool, Infery LLM, you can achieve a throughput that’s a staggering 3.5 times greater than SantaCoder’s.
Explore Infery LLM.
Book a Demo.
Join us as we delve into the outstanding capabilities of DeciCoder.
Bridging the Gen AI Efficiency Gap
Inefficient inference poses a substantial hurdle in the production and deployment of deep learning models, especially for generative AI. As these algorithms grow in size and complexity, their escalating computational requirements not only increase energy consumption but also drive up operational costs. Furthermore, this elevated energy usage carries significant environmental consequences.
Deci’s suite of Large Language Models and text-to-Image models, with DeciCoder leading the charge, is spearheading the movement to address this gap.
DeciCoder’s efficiency is evident when compared to other top-tier models. Owing to its innovative architecture, DeciCoder surpasses models like SantaCoder in both accuracy and speed. The innovative elements of DeciCoder’s architecture were generated using Deci’s proprietary Neural Architecture Search technology, AutoNAC™.
Another Win for AutoNAC
The quest for the “optimal” neural network architecture has historically been a labor-intensive manual exploration. While this manual approach often yields results, it is highly time consuming and often falls short in pinpointing the most efficient neural networks. The AI community recognized the promise of Neural Architecture Search (NAS) as a potential game-changer, automating the development of superior neural networks. However, the computational demands of traditional NAS methods limited their accessibility to a few organizations with enormous resources.
Deci’s AutoNAC revolutionized NAS by offering a compute-efficient method to produce NAS-generated algorithms, bridging the gap between potential and feasibility. Simply put, AutoNAC™ finds the optimal architecture that delivers the best balance between accuracy and inference speed for specific data characteristics, task, performance targets, and inference environment. AutoNAC recently generated the state-of-the-art object detection model Yolo-NAS, DeciBERT for question answering tasks, DeciSeg for semantic segmentation among many others.
For DeciCoder, AutoNAC searched through a design space of transformers that use Multi Head Attention (MHA), Multi Query Attention (MQA), and Grouped Query Attention (GQA). The objective was to find an architecture optimized for NVIDIA’s A10 – a leading cloud GPU for generative AI models, maximizing throughput while rivaling the accuracy of SantaCoder.
DeciCoder’s Architecture
The use of AutoNAC resulted in a new and distinctive transformer architecture for DeciCoder. One notable feature is its implementation of Grouped Query Attention with 8 key-value heads. By grouping query heads and allowing them to share a key head and value head, computation becomes streamlined, and memory usage optimized.
This approach provides a better tradeoff between accuracy and efficiency than does Multi-Query Attention, which is used in models like GPT3, SantaCoder, and StarCoder. Grouped Query Attention offers similar efficiency to Multi-Query Attention, but with much better accuracy.
DeciCoder’s architecture differs from SantaCoder’s in other ways as well. It has fewer layers (20 vs. 24 in Santa), more heads (32 vs 16) and the same embedding size, which means its head sizes are smaller (64 vs 128 in Santa).
DeciCoder’s Training Process
Once the DeciCoder architecture was generated by AutoNAC, DeciCoder began its training phase. DeciCoder was trained on the Python, Java, and Javascript subsets of the Stack, an extensive dataset containing over 6TB of permissively-licensed source code from 358 programming languages.
DeciCoder’s training employed the ‘Fill in the Middle’ training objective. This method challenges language models to complete missing or broken segments of text, aiming to produce coherent and contextually relevant content.
DeciCoder was trained at a Bfloat16 precision.
DeciCoder’s Accuracy – Surpassing SantaCoder Across Multiple Languages
DeciCoder’s accuracy surpasses that of SantaCoder. On the HumanEval evaluation benchmark, a tool designed specifically for assessing large language model (LLM) expertise in code generation tasks, DeciCoder outperforms SantaCoder in every language they were trained on, namely Python, Javascript and Java.
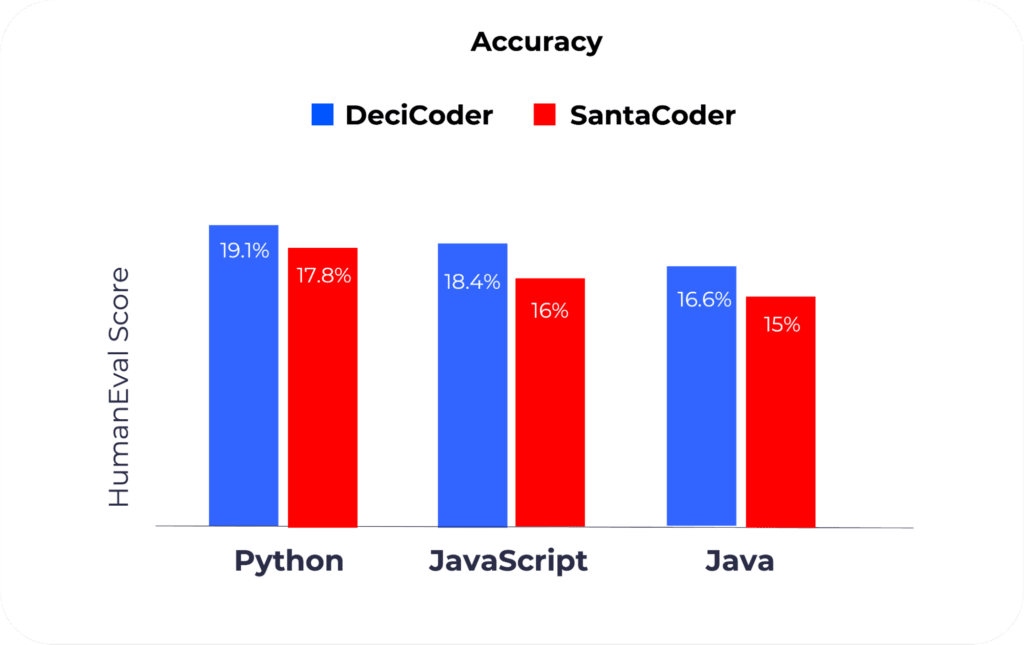
HumanEval stands out as a benchmark, offering a wide array of programming challenges, ranging from language comprehension to algorithmic tasks and foundational mathematics. Some of its tasks are even akin to standard software interview questions, offering a valuable measure for assessing practical utility.
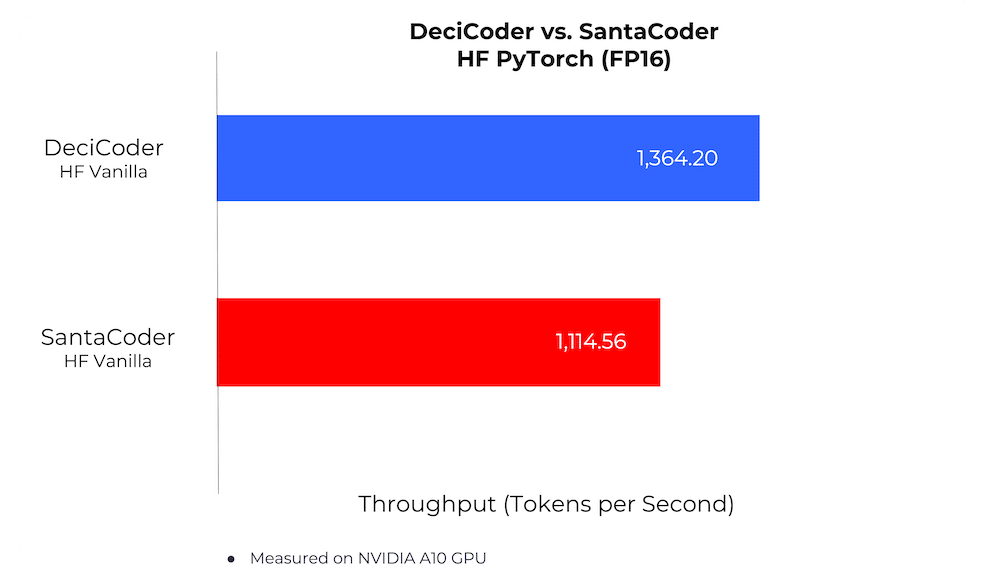
DeciCoder’s Remarkable Inference Speed
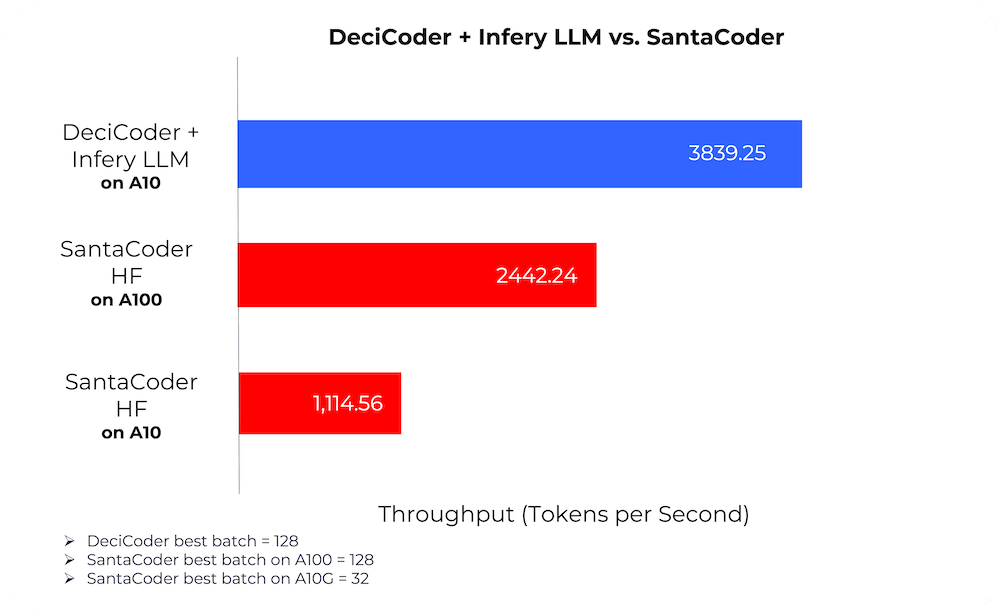
When it comes to measuring the efficacy of AI models, throughput – the number of tokens processed per second – is a critical metric for the operational efficiency of any application powered by Generative AI models . DeciCoder consistently outperforms SantaCoder in head-to-head comparisons.
When integrated with Deci’s inference optimization tool, DeciCoder outperforms SantaCoder in efficiency, delivering higher throughput even on more affordable GPUs that are 4x less expensive.
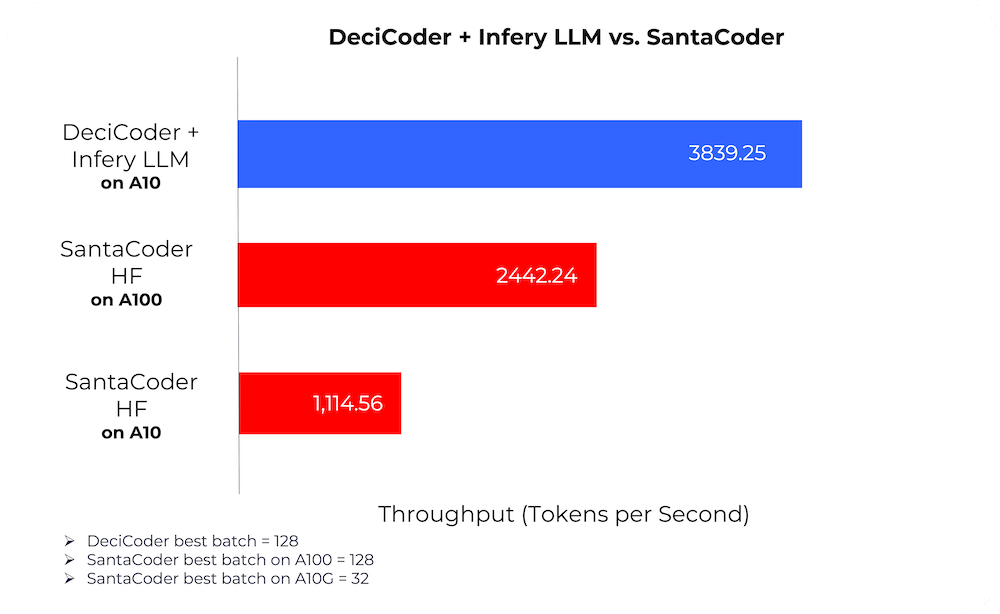
So, what drives DeciCoder’s impressive throughput? A combination of architectural efficiency and optimized implementation. Notably, DeciCoder is significantly more memory efficient, allowing it to manage larger batch sizes. This memory efficiency means that Deci’s throughput reaches its maximum when its batch size is at 128, whereas SantaCoder capped at 32. With larger batch sizes, without the worry of running out of memory, DeciCoder effectively processes more data at once, further augmenting its speed advantages.
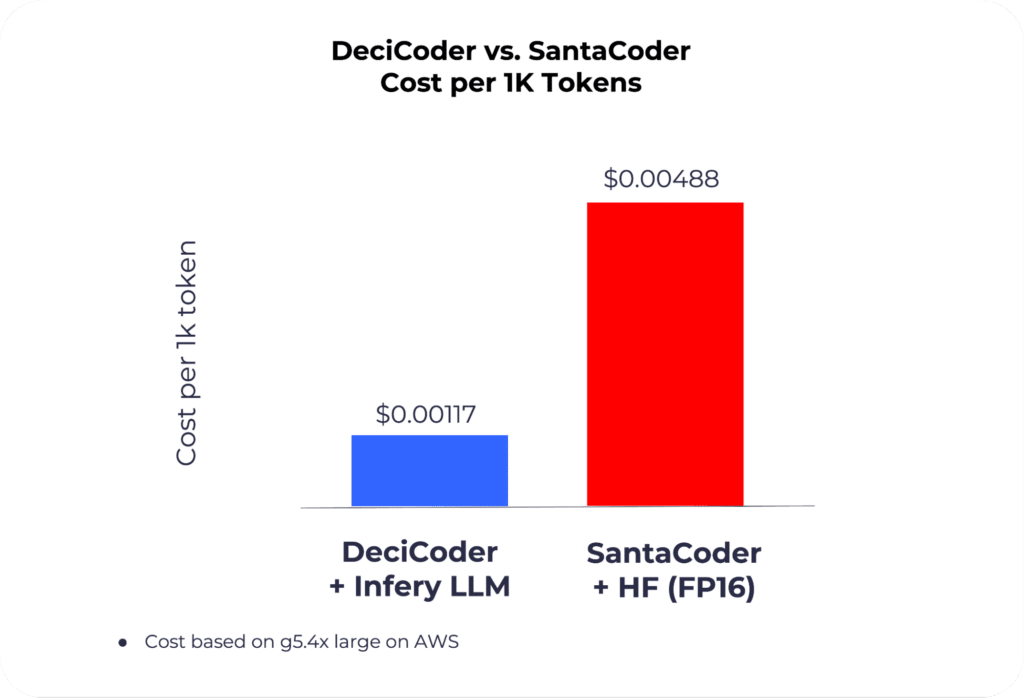
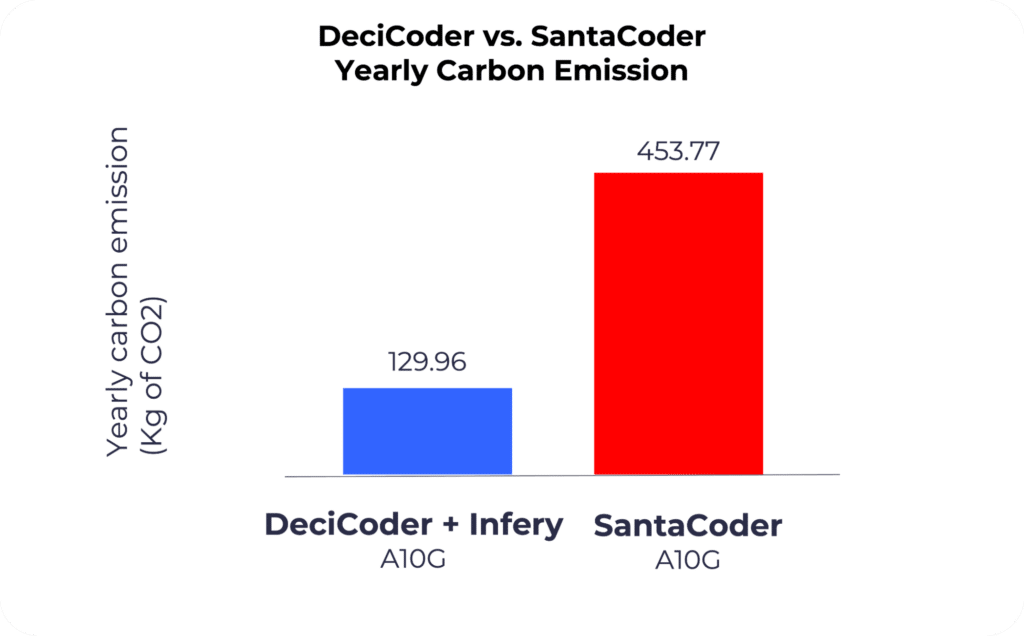
DeciCoder’s efficiency results in a significant reduction in inference cost and carbon emissions. When paired with Infery LLM, the model’s cost per 1k tokens is 71.4% lower than SantaCoder’s on HuggingFace Inference Endpoint. Moreover the yearly carbon emitted is reduced by 324 kg CO2 per model instance on A10G GPU.
Infery LLM’s Advantage in Accelerating Inference Speed
Infery LLM is integral to amplifying DeciCoder’s already impressive inference speeds. Written with proprietary kernels, and other advanced engineering breakthroughs, Infery serves as Deci’s dedicated inference engine for LLMs. When paired with DeciCoder, or any other LLM, it delivers enhanced performance outcomes. For those prioritizing speed and efficiency, the Infery framework is an essential tool to optimize DeciCoder’s deployment or that of any other LLM. Notably, Infery is set to launch with Deci’s Gen AI SDK in the coming weeks.
Looking to accelerate inference and cut your LLM inference costs?
Book a Demo.
DeciCoder’s Permissive Licensing
In releasing DeciCoder to the open source community, we’re committed to ensuring ease of use and accessibility for all users. To that end, DeciCoder comes with a permissive license (Apache 2.0). What does this mean for developers and businesses alike? It’s simple:
- Broad Use Rights: With a permissive license, DeciCoder grants you wide-ranging rights, alleviating typical legal concerns that can accompany the use of some models. You can seamlessly integrate DeciCoder into your projects with minimal restrictions.
- Ready for Commercial Applications: Beyond just experimentation and personal projects, Deci’s permissive licensing means you can confidently deploy DeciCoder in commercial applications. Whether you’re looking to enhance your product, offer new services, or simply leverage the model for business growth, DeciCoder is ready to be your partner in innovation.
Deci’s Edge
Throughout this blog, we’ve highlighted the robust capabilities of DeciCoder, showcasing its consistent superiority over models like SantaCoder. Our innovative use of AutoNAC allowed us to generate an architecture that’s both efficient and powerful.
The synergy with Infery LLM can’t be overlooked. This proprietary inference engine, built with compatibility for PyTorch Script, optimizes execution and bolsters any LLM’s speed, helping AI teams to dramatically cut their inference costs and deliver users with an enhanced experience.
DeciCoder is just a glimpse, into the upcoming release of our expansive suite of Generative AI foundation models, accompanied by the GenAI SDK. This is only the beginning—there’s a world of innovations awaiting.
To learn more about DeciCoder, check out the model on Hugging Face.