

From sports and manufacturing to smart cities and consumer products, computer vision applications have expanded in recent years – and their growth is only going to continue from here on out. However, for computer vision to advance in terms of technology and adoption across industries, a key obstacle must be addressed: the balancing of inference performance and accuracy on target hardware to achieve cost-efficiency and deliver the optimal user experience. To bridge this critical gap, Deci has introduced its Foundation Models, a catalog of off-the-shelf base models architected for target hardware and optimized for high accuracy and efficient runtime performance.
In this blog, we’re going through the various challenges in building and deploying computer vision applications and how Deci’s Foundation Models address them. In particular, we’re looking at how and why the best approach to optimization to achieve the full potential of computer vision applications is at the algorithm level.
The rise of computer vision and its challenges
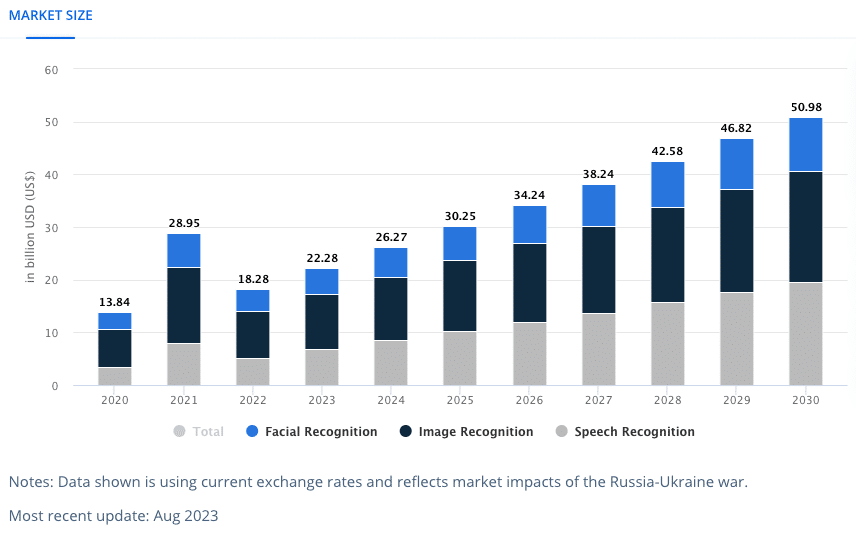
Computer vision is a promising field in the world of AI, and the numbers prove it. The market size in the computer vision market is projected to reach US$26.26bn in 2024. With an annual growth rate (CAGR 2024-2030) of 11.69%, the market volume is expected to reach US$50.97bn by 2030.
The steady growth of computer vision applications can be attributed to a few factors:
- An increase in demand for automation and AI-based solutions in various industries including Industry 4.0, automotive, smart city, and retail that require fast, cost-efficient, and accurate models.
- The explosion of digital imagery and video content available online, providing vast amounts of data for training computer vision models, which is crucial for the development and refinement of algorithms.
- Finally, the rise of foundation models, like ResNet and EfficientNet, that push the boundaries of computer vision, paving the way for novel use cases and continuous advancement of the field.
However, in computer vision, there’s typically a trade-off between accuracy and latency. While aiming for high accuracy is preferable, it can lead to increased latency or slower inference times, particularly with large and complex models. Conversely, prioritizing low latency may mean compromising on accuracy to a certain degree.
While foundation models offer improvements, there are still challenges, such as managing model complexity, ensuring accuracy, adapting models to new domains, and deploying them in resource-constrained environments, to name a few. These hurdles can be summed up into the balancing of inference performance, cost-efficiency, and accuracy on target hardware.
And Deci’s foundation models solve exactly that.
What are Deci’s foundation models?
Foundation models refer to large-scale pretrained neural network architectures that serve as the basis or foundation for various downstream computer vision tasks.
These models are typically trained on massive datasets and learn to represent visual information in a way that captures meaningful patterns and relationships. Once trained, these foundation models can be fine-tuned or adapted to specific tasks and domains with comparatively smaller datasets. With foundation models, you can leverage their pretrained knowledge to improve the performance of your fine-tuned models on specific tasks, without needing to train from scratch.
Deci’s foundation models are a catalog of base models for various computer vision tasks including object detection, pose estimation, image classification, and semantic segmentation. Unique to Deci, our foundation models are optimized for specific hardware and datasets. This ensures efficient performance, resource utilization, and reduced latency. If your use case targets hardware similar to these foundation models, you can expect similar results.
How Deci’s models outperform other SoTA models in their class
Created for a combination of tasks, hardware, and data characteristics, Deci’s foundation models offer the best inference performance when compared with SoTA models in their respective domains. These object detection, pose estimation, image classification, and semantic segmentation models are built and optimized to run successfully in production. Let’s take a look.
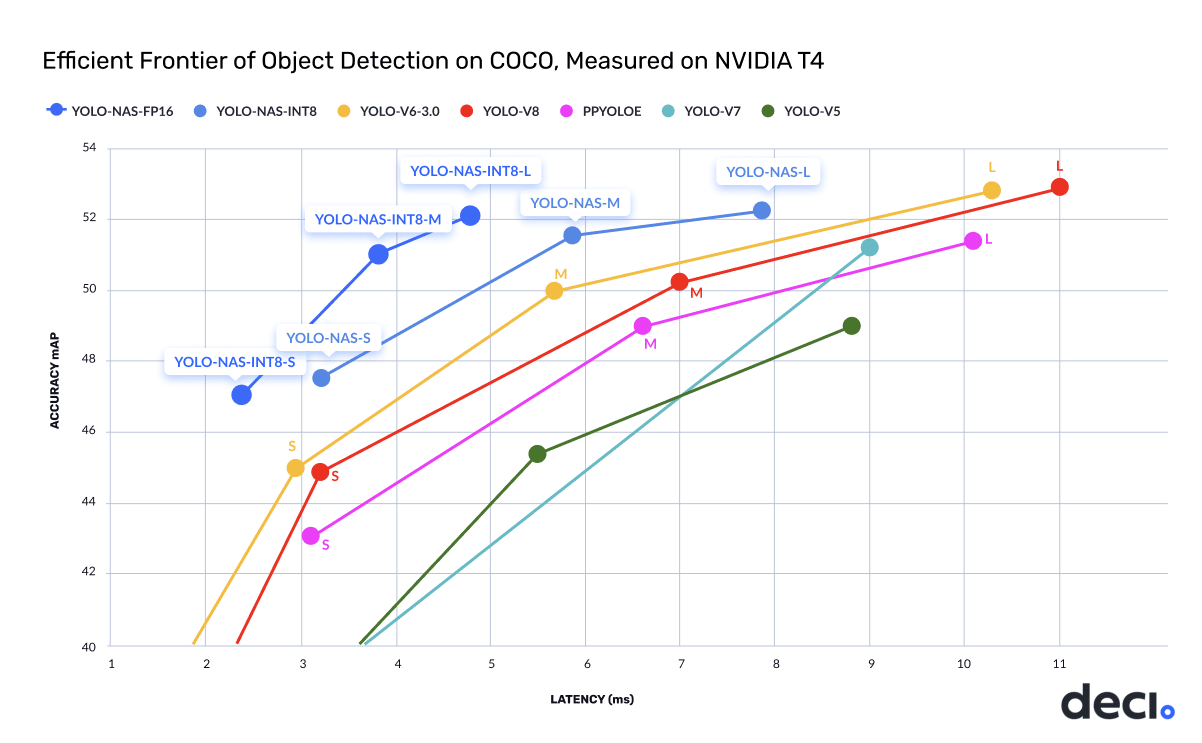
YOLO-NAS for object detection
YOLO-NAS provides superior real-time object detection capabilities and production-ready performance. It delivers SoTA performance with unparalleled accuracy-speed balance, outperforming other models such as YOLOv5, YOLOv6, YOLOv7, and YOLOv8. As demonstrated in the chart below, the YOLO-NAS (m) model delivers a 50% (x1.5) increase in throughput and 1 mAP better accuracy compared to other SOTA YOLO models on the NVIDIA T4 GPU.
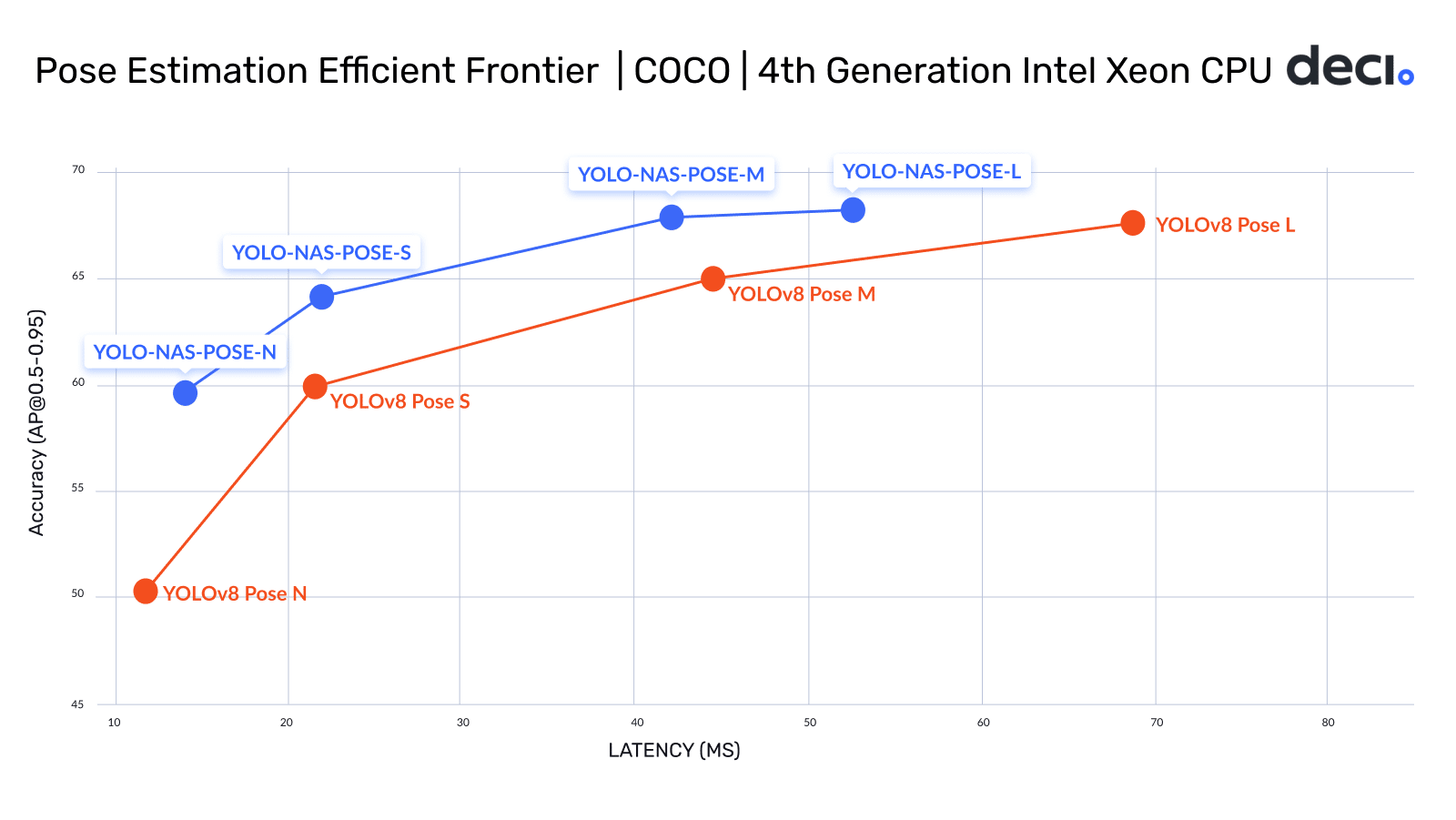
YOLO-NAS Pose for pose estimation
Building on YOLO-NAS, its pose estimation sibling, YOLO-NAS Pose, delivers significantly higher accuracy with similar or better latency compared to its YOLOv8 Pose equivalent model variants. For example, the YOLO-NAS Pose M variant boasts 38% lower latency and achieves a +0.27 AP higher accuracy over YOLOV8 Pose L, measured on Intel Gen 4 Xeon CPUs. YOLO-NAS Pose excels at efficiently detecting objects while concurrently estimating their poses, making it the go-to solution for applications requiring real-time insights.
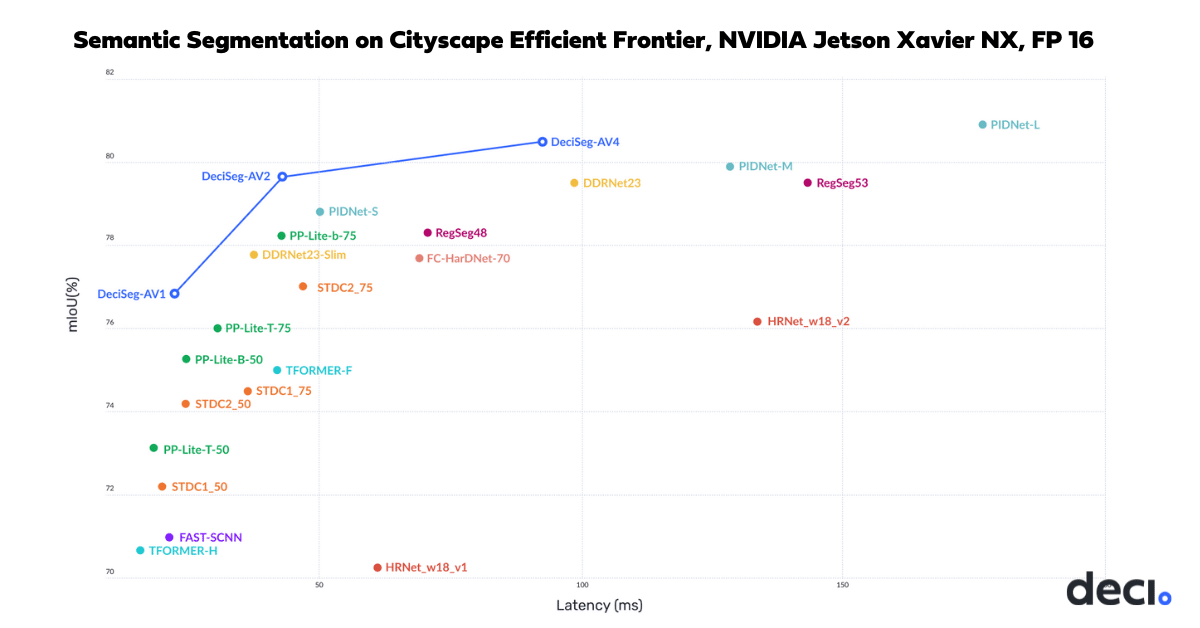
DeciSegs for semantic segmentation
DeciSeg models can dramatically improve the performance of real-world applications that require high accuracy and low latency. In the following chart, you’re able to see a comparison of SoTA models such as PP-Lite, FC-HardNet, STDC, DDRnet, and PIDNet, and how they compare to the DeciSeg models both in terms of accuracy and latency. For example, one of the DeciSegs is 2.31x faster and +0.84 more accurate than DDRNet23.
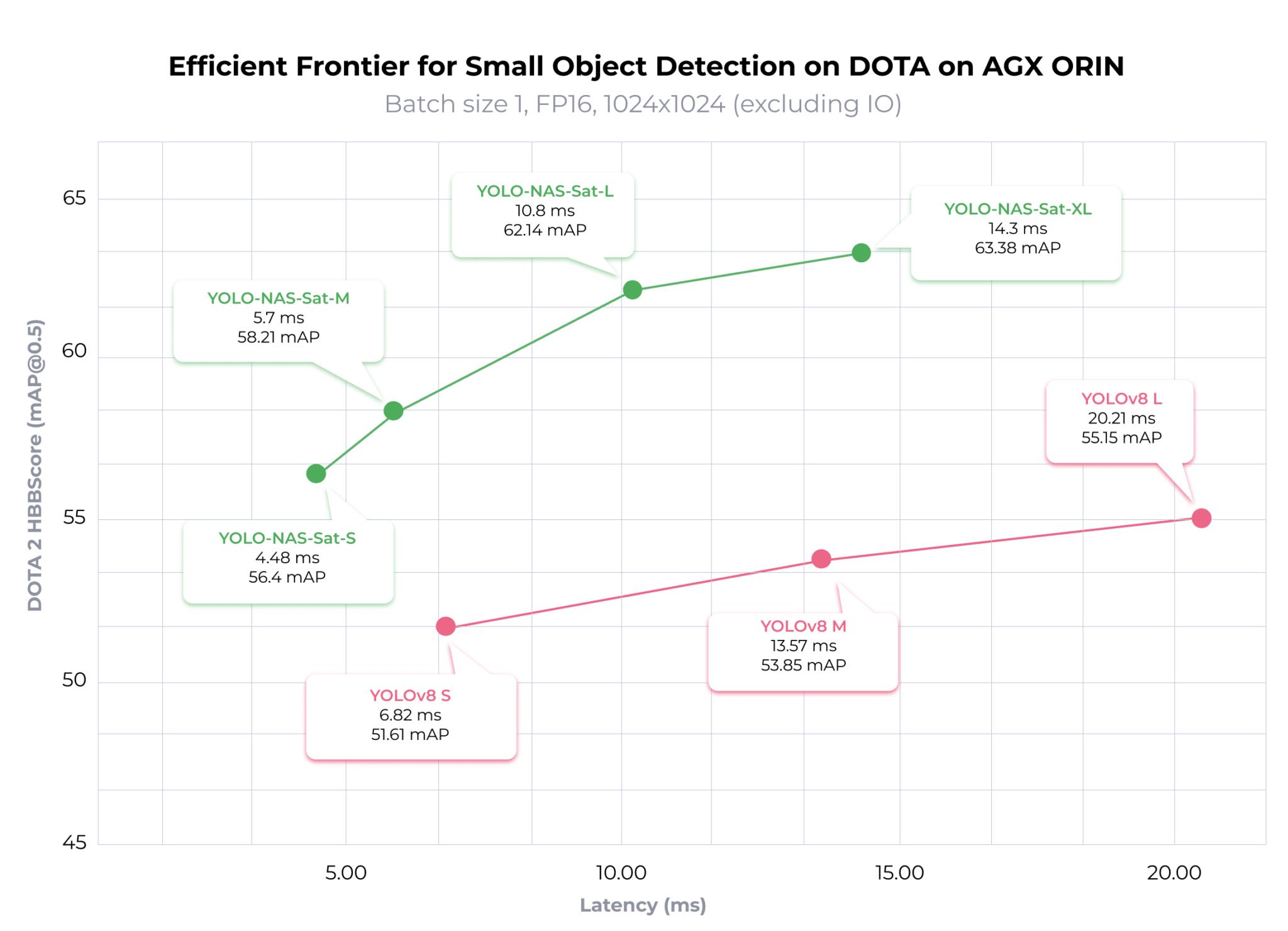
YOLO-NAS-Sat for small object detection
Built for small object detection, YOLO-NAS-Sat sets itself apart by delivering an exceptional accuracy-latency trade-off, outperforming established models like YOLOv8 in small object detection. For instance, when evaluated on the DOTA 2.0 dataset, YOLO-NAS-Sat L achieves a 2.02x lower latency and a 6.99 higher mAP on the NVIDIA Jetson AGX ORIN with FP16 precision over YOLOV8.
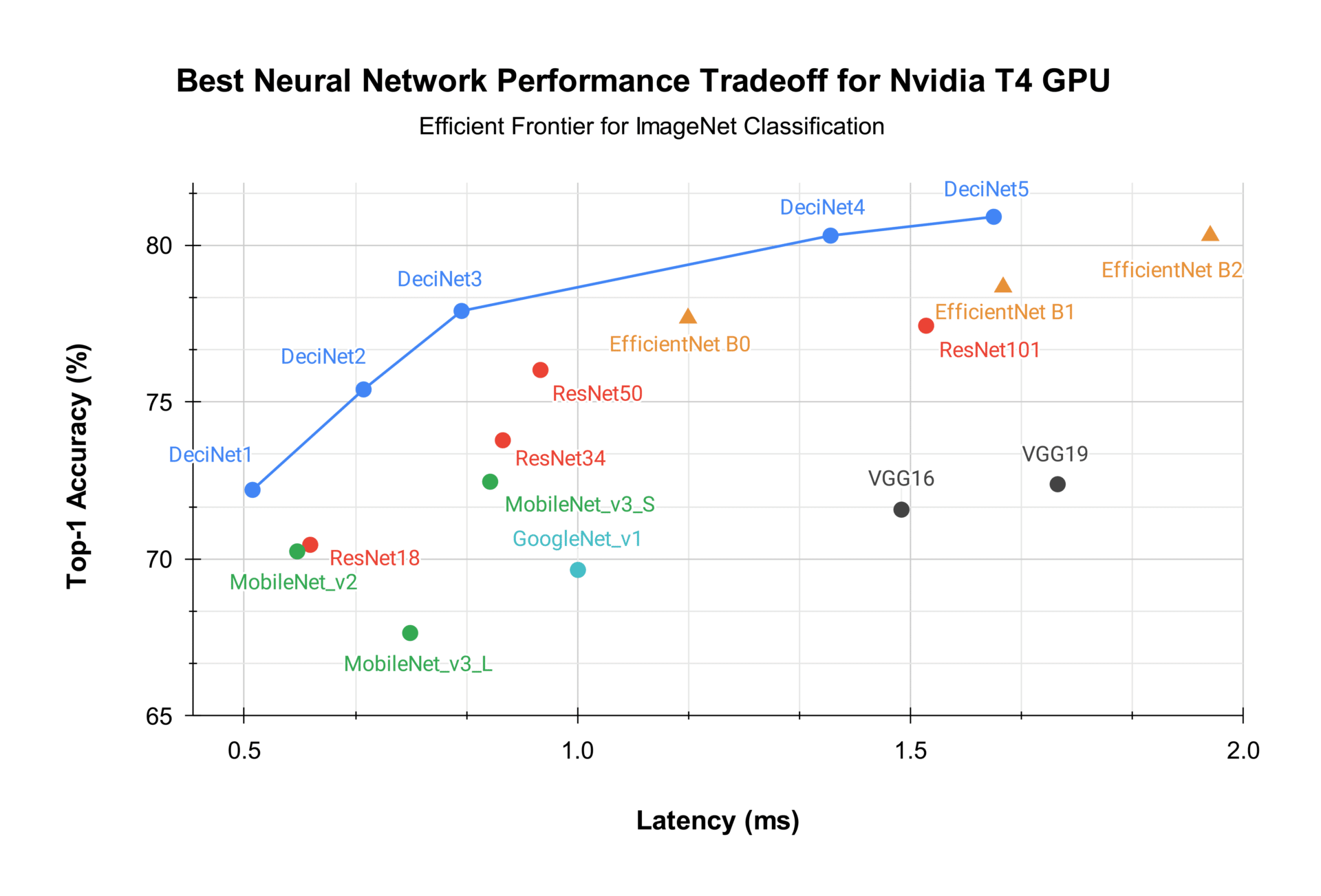
DeciNets for image classification
DeciNets are image classification models that outperform many well-known and powerful models including EfficientNets and MobileNets. In the graph below, EfficientNet B2 achieves 0.803 top-1 ImageNet accuracy with an inference time of 1.950 milliseconds. DeciNet-4 has the same accuracy and is almost 30% faster, while DeciNet-5 is both more accurate and faster. DeciNets clearly dominate the baseline architectures and advance the SoTA for the NVIDIA T4 GPU hardware.
What are the advantages of using Deci’s foundation models?
Deci’s pretrained foundation models eliminate the complexities and uncertainties of model development. The result is not just a savings in development time and reduction of risk but also an enhancement in accuracy and performance beyond what could typically be achieved with in-house efforts. Leveraging Deci’s foundation models for your needs capitalizes on a strategic opportunity to enhance efficiency and effectiveness, negating the need to “reinvent the wheel” when a proven solution is readily available.
Moreover, Deci has complementary tools to help you with training, fine-tuning, and deployment. Once you select a foundation model that’s suitable for your use case, you can use SuperGradients, Deci’s open-source PyTorch training library to fine-tune it. Once done, you can optimize and run the model with Infery, our inference optimization and deployment SDK, in any environment including on-premise, cloud, or data center.
Working with Deci’s foundation models, you get:
- 5X inference acceleration. With Deci’s foundation models you can achieve low latency, high throughput, and better accuracy to improve user experience.
- 80% shorter development process. Using Deci’s production-ready models lowers risks and shortens development time from months to days.
- 5X inference cost reduction and 50% lower development cost. Since the models are hardware-aware, you get a smaller memory footprint and maximal hardware utilization, allowing you to save on costs and easily deploy on any hardware, even at the edge.
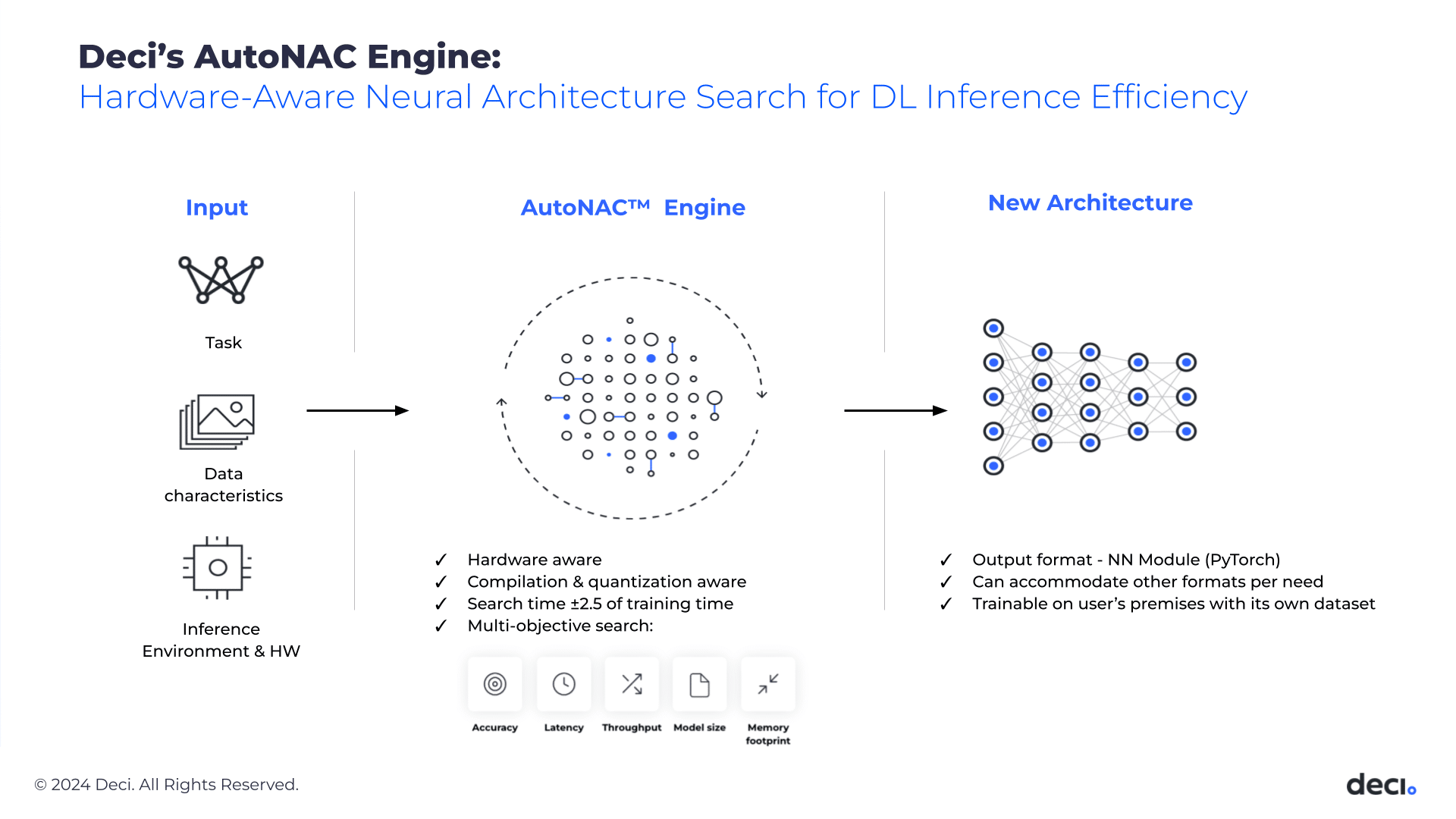
The secret sauce: AutoNAC
The superior performance of YOLO-NAS, YOLO-NAS Pose, DeciSegs, YOLO-NAS-Sat, and DeciNets is attributable to their innovative architecture, all generated by AutoNAC (Automated Neural Architecture Construction), Deci’s proprietary hardware-aware neural architecture search (NAS) engine.
NAS is an algorithmic acceleration method for achieving significant speed improvements. To employ NAS, you must define an architecture space and use a search strategy to explore it for an architecture meeting the desired criteria. NAS optimizations have led to remarkable advancements in deep learning, exemplified by discoveries like MobileNet-V3 and EfficientNet(Det) that emerged through NAS.
However, NAS algorithms typically demand extensive computational resources, making their application in scalable production environments exceptionally challenging and costly. Deci’s AutoNAC introduces a novel, fast, and computationally efficient generation of NAS algorithms, enabling cost-effective and scalable operation. It is aware of hardware considerations and accounts for all factors affecting inference, including compilers and quantization. It takes it only a few days to find an architecture that meets specified performance requirements such as accuracy, latency, throughput, and memory footprint, and is optimized for specific hardware and dataset characteristics.
The future of computer vision is inference acceleration at the algorithmic level
To wrap it up, Deci’s pretrained foundation models, generated with AutoNAC, are tailored to specific tasks, hardware, and data characteristics. Addressing the demand for highly accurate and cost-efficient inference performance, they can be fine-tuned using SuperGradients and optimized with Infery for deployment in any environment.
As the case studies showed, Deci’s foundation models empower you to achieve low latency, high throughput, and better accuracy. They shorten development time, reduce memory footprint, and maximize hardware utilization for deployment across various hardware, including at the edge.
Do you have a computer vision use case in mind? We’d be happy to chat. Talk with one of our experts.








