
Authors: Shai Rozenberg, Deci AI, and Guy Boudoukh, Intel Labs
Deci’s DeciBert Models coupled with Intel® Distribution of OpenVINO™ toolkit deliver better speed than BERT-Base, and higher accuracy than BERT-Large
When it comes to deep learning models for Natural Language Processing (NLP), accuracy and speed are the pivotal scores. This year at MLPerf, Intel ® and Deci collaborated to submit optimized NLP models that produced outstanding results: accelerating question-answering task’s throughput performance on various Intel CPUs by a range of 4.6x to 10.3x (depending on hardware type and quantization level) while keeping the same accuracy. Here’s the story.
What is MLPerf?
MLPerf has been referred to as the ‘olympics of neural network performance’. Established by AI leaders from industry and academia, MLPerf is geared at creating fair and standardized benchmarks to measure the training and inference performance of ML hardware, software, and services. MLPerf is probably the best and most reliable baseline for ML models, with each benchmark defined by a model, a dataset, a task, and an allowable margin of error.
Similar to past MLPerf benchmarks, the submissions have two divisions: closed and open. Closed submissions use the same reference model to ensure an easy method for comparison, while the open division allows different models to be submitted. In Q1 2022, Intel ® and Deci participated in the open submission, in which they were required to provide a network that is at least 99% as accurate or in some cases 99.99% as accurate as the F1 score of BERT-Large. The task at hand was NLP question-answering on the Stanford Question Answering Dataset (SQuAD v1) for reading comprehension. This dataset contains a list of questions on Wikipedia articles, where the answer to each may be a segment of text from the Wikipedia article or it may be unanswerable. The submission was made under the Offline track, allowing the samples to be run in groups.
Deci and Intel Together Achieve Inference Speedup of 4 to 5 times
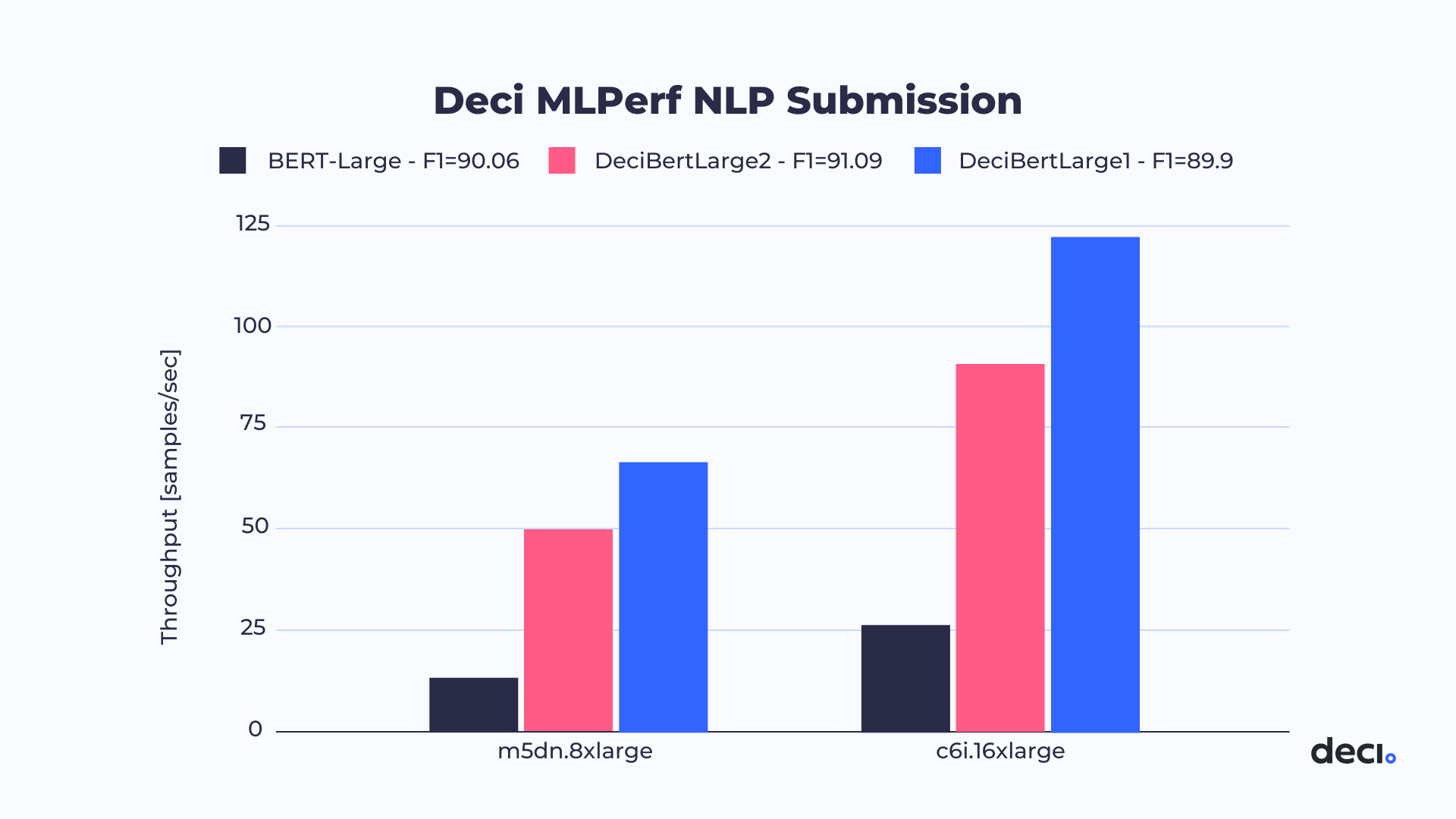
MLPerf was an ideal opportunity to test Deci’s Automated Neural Architecture Construction (AutoNAC) generated DeciBERT models. Together, Deci and Intel made submissions on two different Intel hardware platforms: the 16-core Cascade Lake CPU and the 32-core Ice Lake CPU. For each machine, 2 DeciBERT models were submitted, which reached 91.09 F1 score and 89.9 F1 score. In short, the submissions were within the required accuracy, while speeding up throughput by factors ranging from 4.6x to 10.3x. The speedup was achieved on a batch size of 16, quantized to INT8 and compiled with Intel® Distribution of OpenVINO™ toolkit.
Let’s take a closer look at the results. The table below, compares our submission to the baseline BERT-Large, clearly showing that our submission achieves an outstanding improvement in throughput per core relative to the baseline.
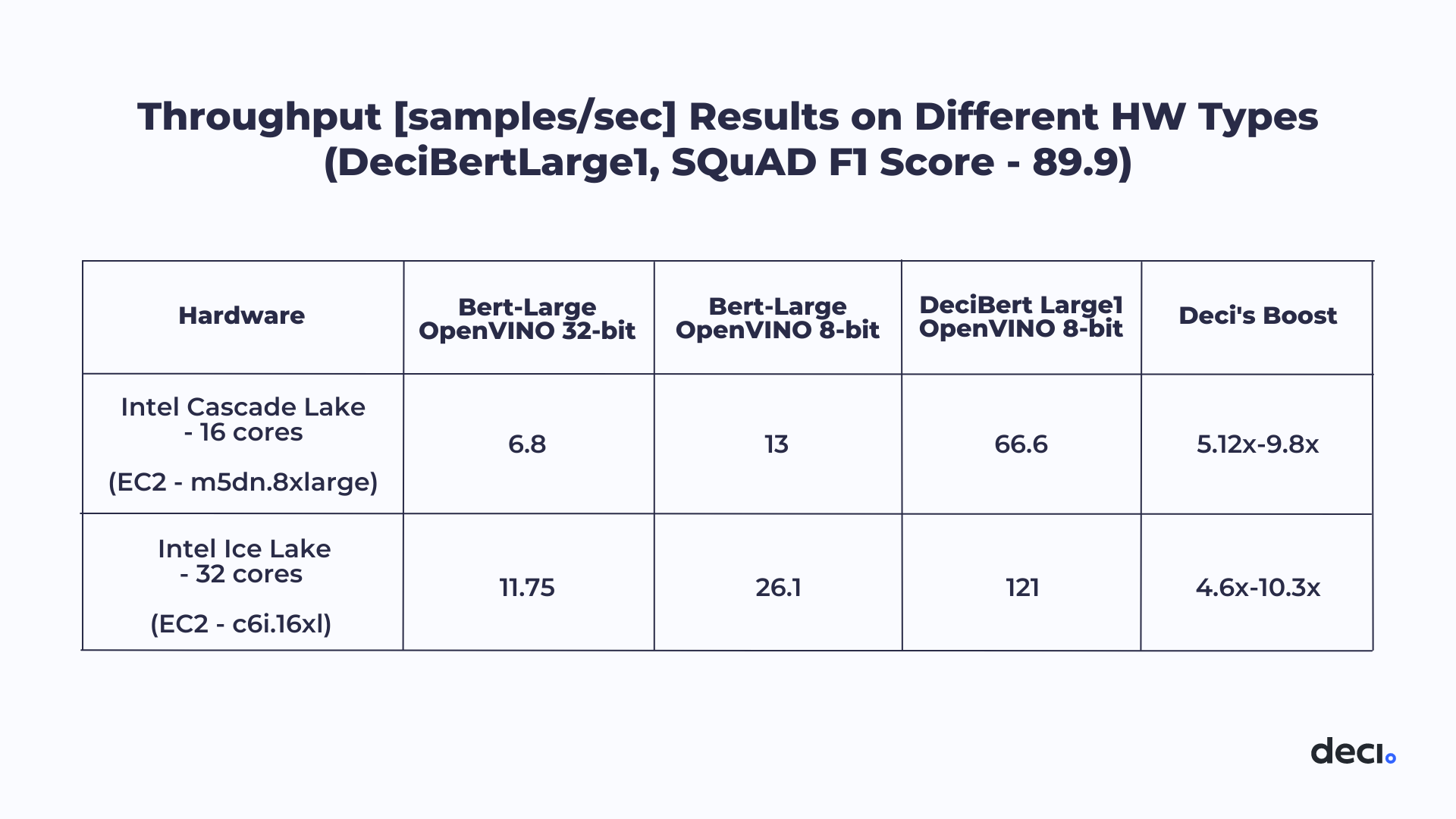
Table 1: Throughput [samples/sec] Results on Different Hardware Types
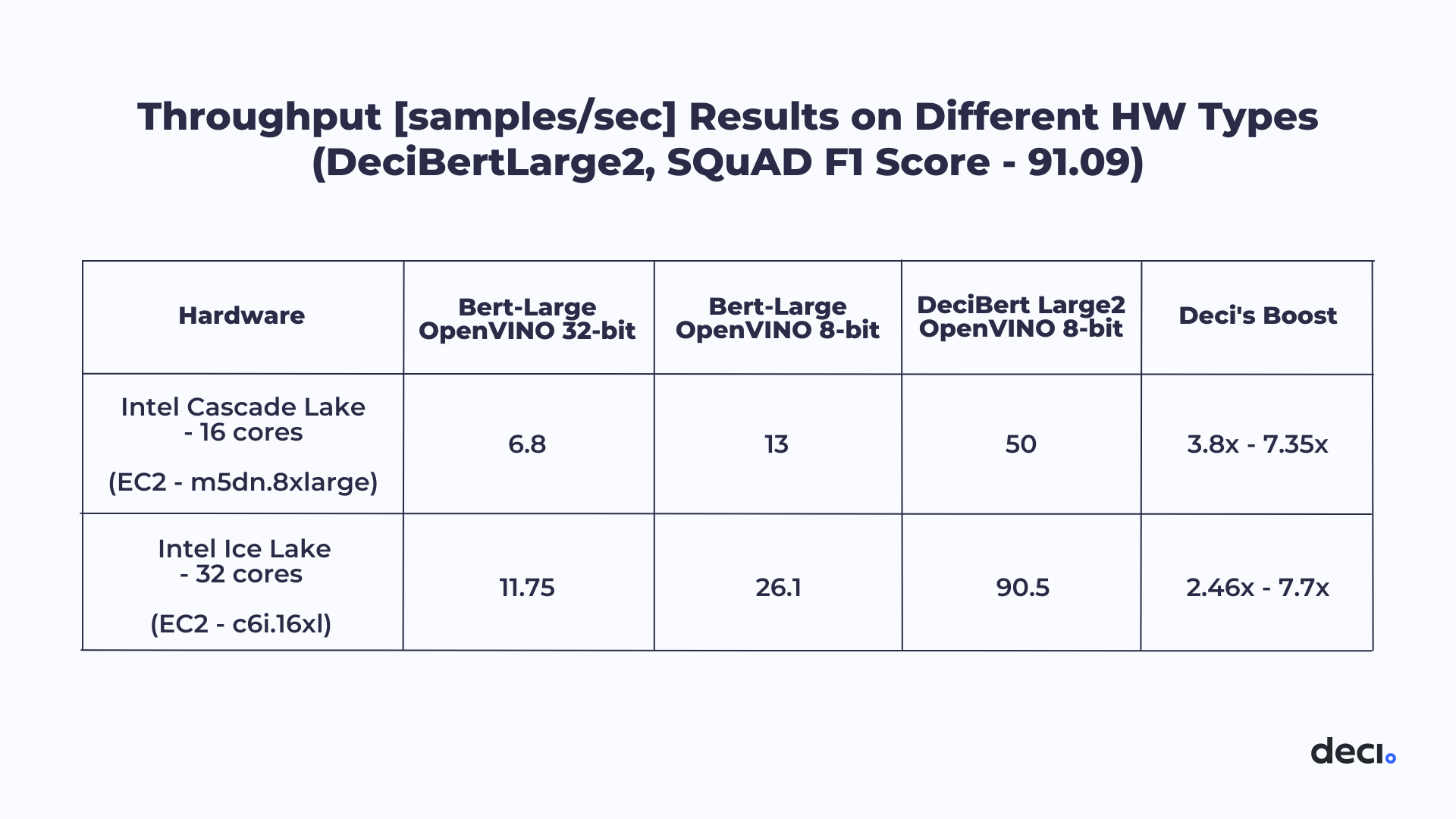
Table 2: Throughput [samples/sec] Results on Different Hardware Types
How We Did It and The Secret Sauce
Deci’s AutoNAC is a data- and hardware-aware architecture optimization algorithm. It determines which operations can be compiled more efficiently and based on that replaces the architecture with an optimal compiled one. AutoNAC uses a sophisticated AI-based search to find new architectures that reduce latency, increase throughput, or reduce power consumption while maintaining the accuracy of the baseline model. Essentially, AutoNAC is an algorithmic optimization engine that automatically generates best-in-class deep learning models for any task, data set and target inference hardware.
The resulting new and improved model architecture is much faster and more efficient because of its ability to optimize operations in a way that is ‘compiler aware’. The question was whether this leaner, faster model would achieve the necessary accuracy. Based on our results, the answer was a resounding yes.
The Future Looks Bright
Like other language models, DeciBERT can be easily fine-tuned for any downstream task; such as, classification, sentiment analysis, summarization, and more. The model is already trained on a massive set of data, ready to be adapted for other tasks or systems, and easily integrated into any existing inference pipeline.
These trailblazing pre-trained DeciBERT models are ready for deployment and commercial use on any platform.
Configuration Details
Test by Intel as of 15/03/2022
m5dn.8xlarge
32 vcpu (Intel® Xeon® Platinum 8259CL Processor), 128 GB total memory, bios: SMBIOS 2.7, ucode: 0x500320a, Ubuntu 18.04.5 LTS, 5.4.0–1068-aws, gcc 9.3.0 compiler. Baseline (Bert Large): bert-large-uncased-whole-word-masking-squad-int8, F1=90.06; Deci Bert Large1: Deci-bert-large1-squad-int8, F1=89.9; Deci Bert Large2: Deci-bert-large2-squad-int8, F1=91.09
c6i.16xlarge
64 vcpu (Intel® Xeon® Platinum 8375C Processor), 128 GB total memory, bios: SMBIOS 2.7, ucode: 0xd000331, Ubuntu 18.04.5 LTS, 5.4.0–1069-aws, gcc 9.3.0 compiler. Baseline (Bert Large):bert-large-uncased-whole-word-masking-squad-int8, F1=90.06; Deci Bert Large1: Deci-bert-large1-squad-int8, F1=89.9; Deci Bert Large2: Deci-bert-large2-squad-int8, F1=91.09
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
This article was first published here.









