
Authors: Amos Gropp, Deci AI, and Guy Boudoukh, Intel Labs
MLPerf Submission Overview
MLPerf is a non-profit organization established by AI leaders from academia, industry and research labs. The goal of MLPerf is to provide standardized and unbiased benchmarks for training and inference performance of machine learning hardware, software and services. MLPerf holds tests to continuously improve and evolve these benchmarks, which are each defined by a model, dataset, quality target, and latency constraint.
This year, Deci and Intel ® collaborated on joint submissions across the computer vision and NLP categories. For computer vision, we submitted three models to the ResNet50 category. Our submission was under the offline scenario in the open division.
Deci and Intel’s Submission Results
We made submissions on two different hardware platforms: a 12-core Intel Cascade Lake CPU and two different Intel Ice Lake CPU with 4 and 32-cores. Models were optimized on a batch size of 32 and quantized to INT8 using Intel® Distribution of OpenVINO™ toolkit . Compared to the baseline ResNet50 model (32 bit), Deci delivered +1.74% improvement in accuracy and between 10x-16.8x improvement in throughput, depending on the hardware type, as shown in Table 1. To further distinguish the improvements due to the use of the AutoNAC-generated DeciNets, we compare a compiled 8-bit ResNet-50 to our submitted model. This shows an improvement of between 2.8x to 4x that is attributed to Deci’s AutoNAC technology.
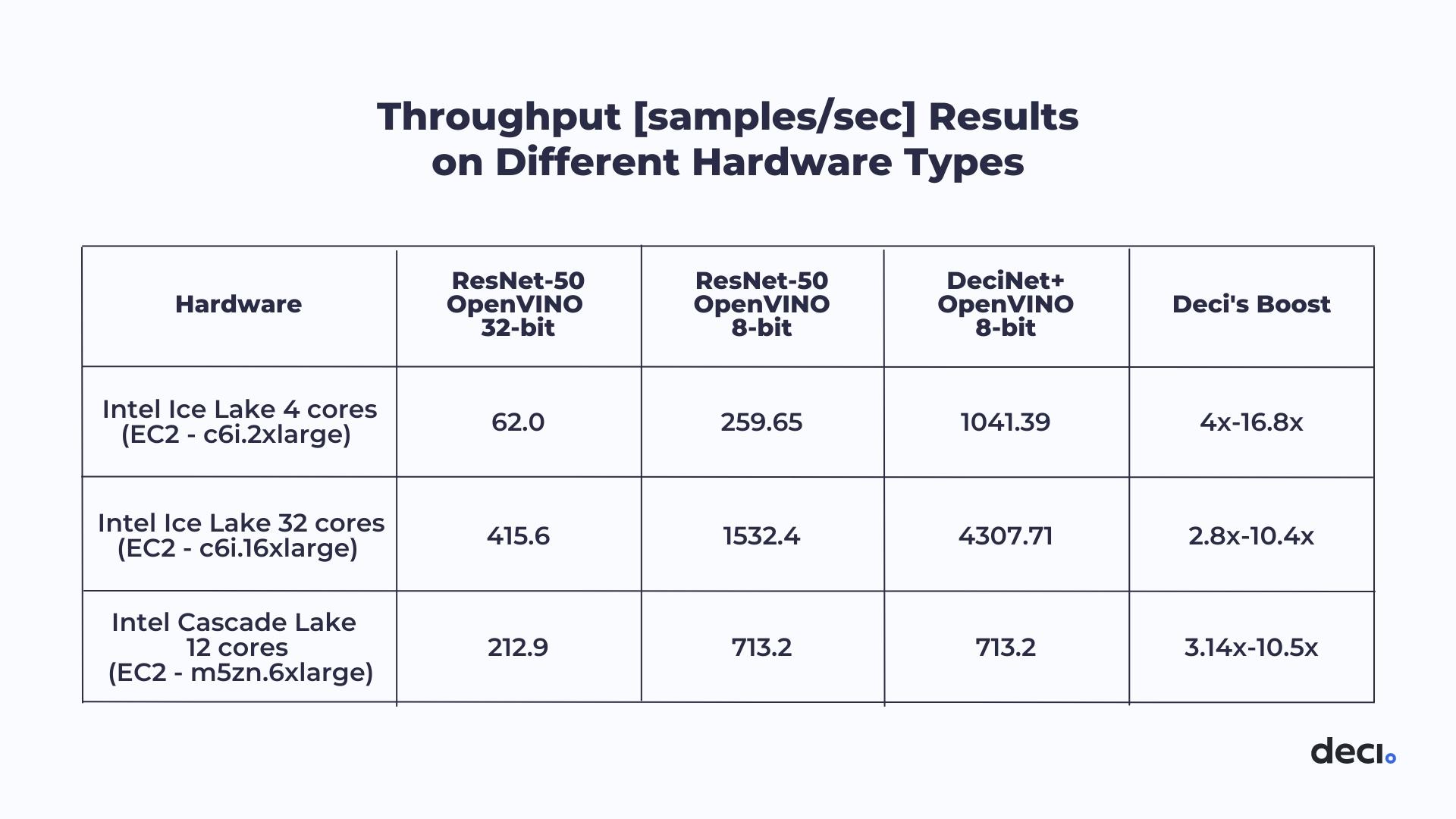
Table 1: Offline scenario — Throughput is images/second. Two hardware types were tested. The second column presents ResNet-50 compiled with OpenVINO to 32-bit. The third column shows ResNet-50 with compilation to 8-bit, and the column labeled DeciNet shows the AutoNAC generated DeciNet model with 8-bit compilation.
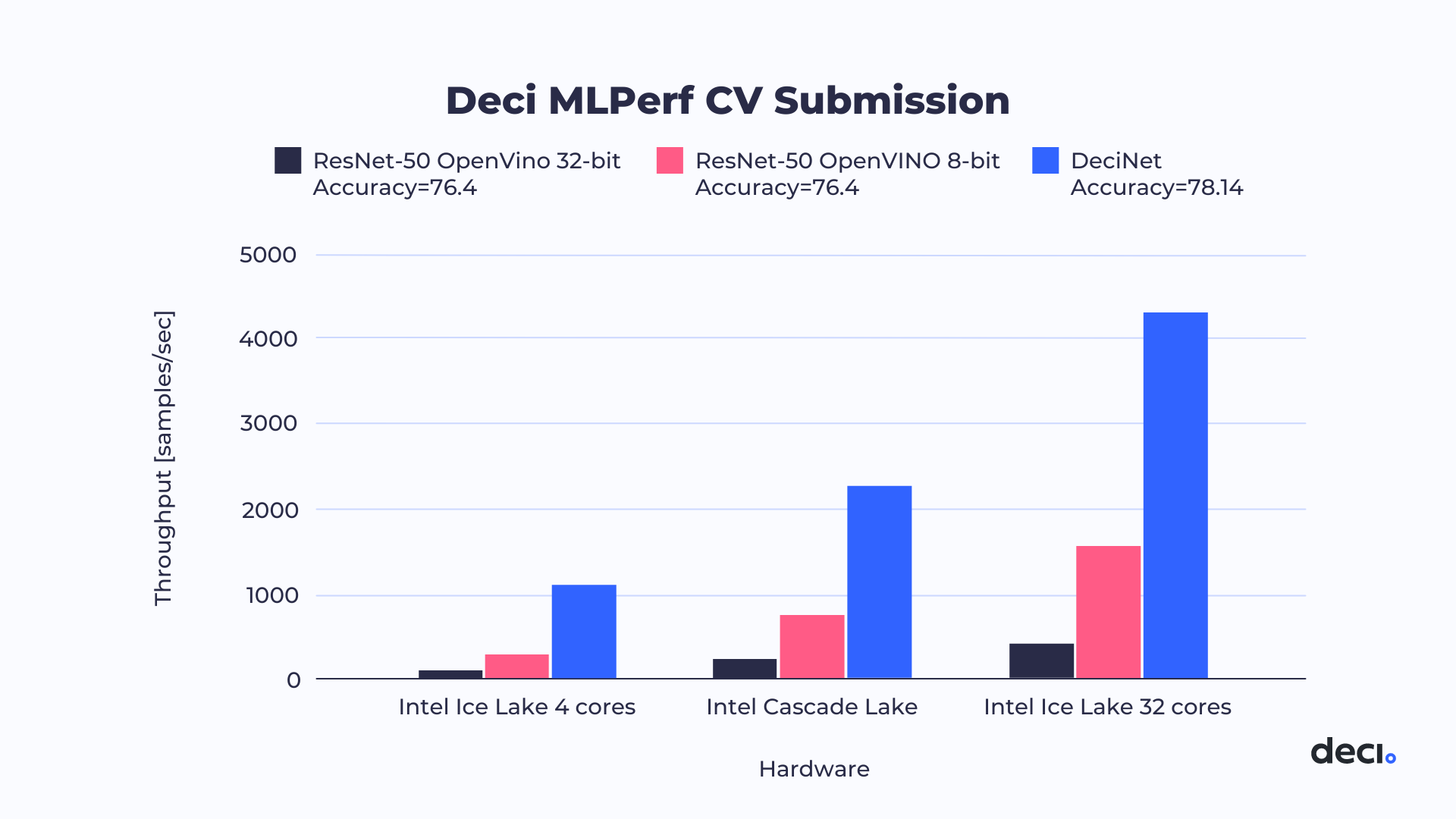
How We Achieved These Results
The starting point for the submission was ResNet-50 with 76.1% top-1 accuracy on ImageNet. The initial objective was to maximize throughput, while maintaining the same accuracy. In order to achieve better performance, we applied Deci’s proprietary Automated Neural Architecture Construction (AutoNAC) technology. Deci’s AutoNAC is a data- and hardware-dependent architecture optimization algorithm. AutoNAC automatically generates best-in-class deep learning models for any given combination of deep learning task, data set and inference hardware. Applying AutoNAC is a seamless process in which the user provides a trained model, training and test datasets, and access to the hardware platform over which the model should be deployed. AutoNAC then automatically computes a new low-latency, high throughput, or low power consumption model that preserves the accuracy of the original Model. The AutoNAC optimization process is depicted in Figure 1.
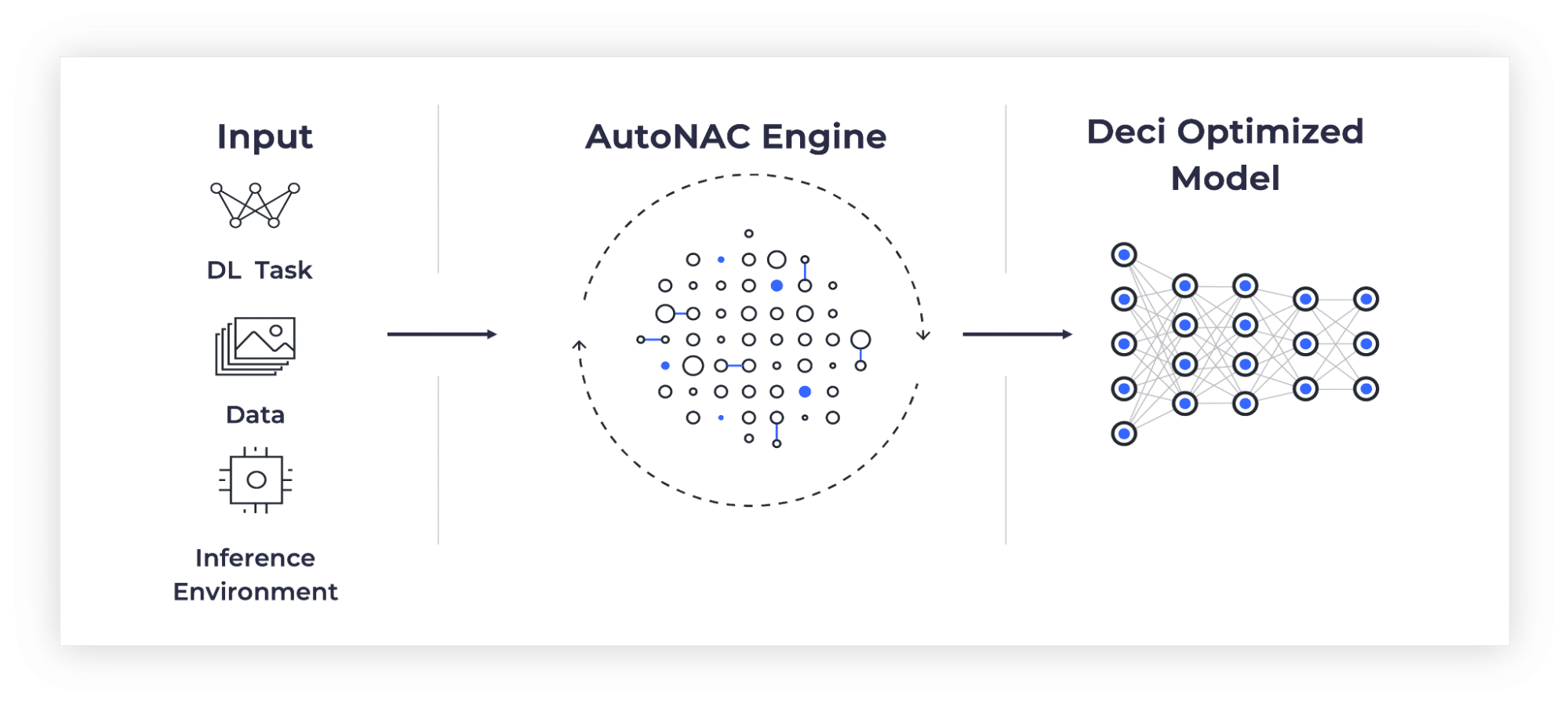 Figure 1: Deci’s AutoNAC Process
Figure 1: Deci’s AutoNAC Process
Unlike standard NAS techniques, AutoNAC starts the search procedure from a relatively good initial point by heavily utilizing the baseline model; including several of its already trained layers.
AutoNAC is applied on a discrete space of architectures that is set in accordance with the allowable neural operations that are supported in the target hardware. The (proprietary) search algorithm itself relies on prediction models to determine effective optimization steps. This algorithm results in very fast convergence times that are often lower than known NAS techniques by orders of magnitude. In addition, one of the main advantages of AutoNAC is its ability to consider all levels of the inference stack and optimize the baseline architecture while preserving accuracy and taking into consideration the target hardware, the (hardware-dependent) compilation, and quantization.
Last year AutoNAC discovered a new family of image classification models, dubbed DeciNets, which outperform well known state-of-the-art models both in accuracy and runtime performance.
The DeciNets we submitted to MLPerf were generated by AutoNAC and specifically designed to deliver optimal performance when running on Intel’s Cascade Lake and Ice Lake CPUs.
Year Over Year Improvement
Two years ago, in 2020, Deci.ai and Intel ® submitted models to the same MLPerf category. When evaluating per core, we can see an approximately 37% improvement in throughput performance compared to our previous submission.
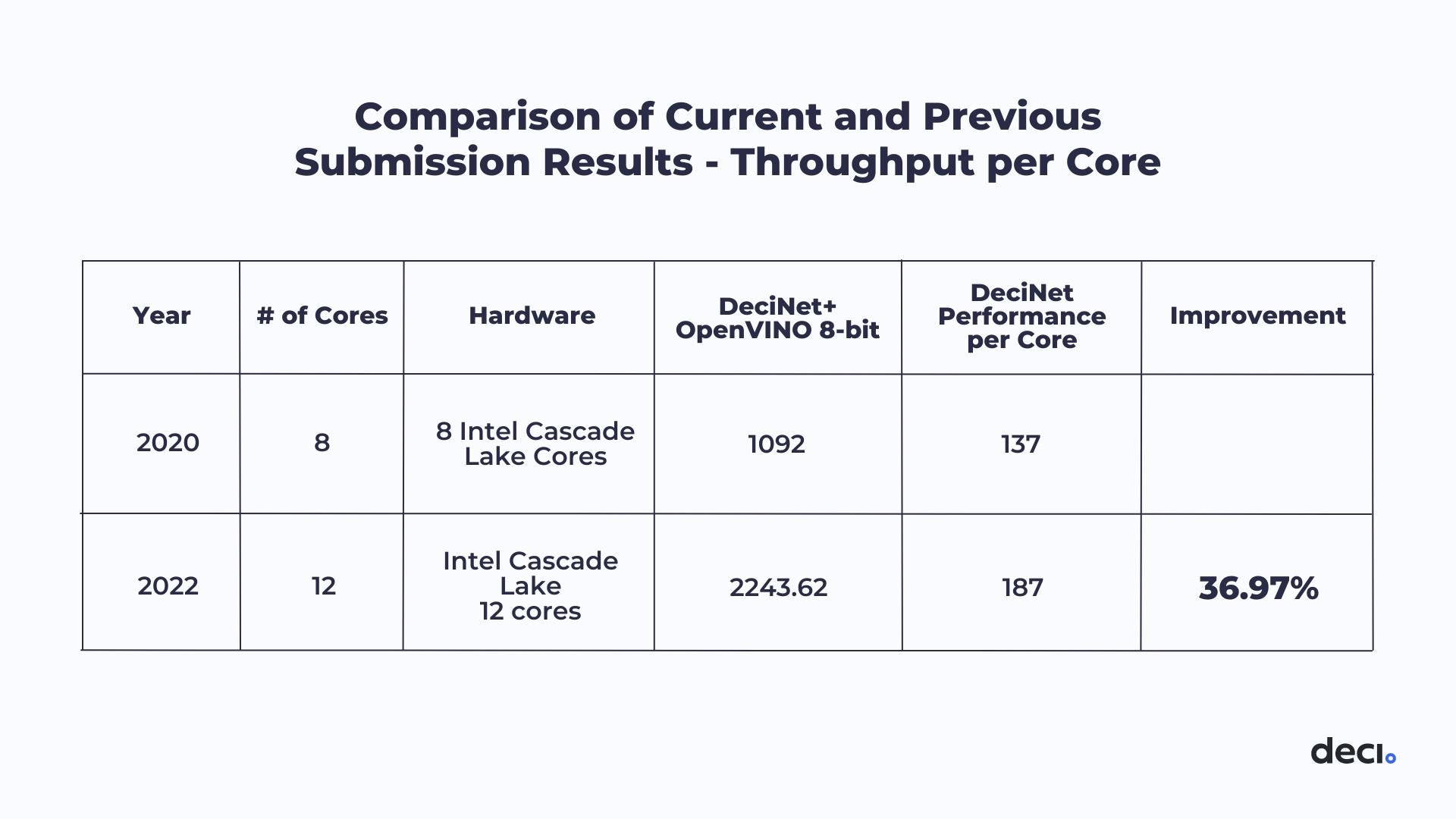
Table 2: Comparison of Current and Previous Submission Results — Throughput per Core
What’s Next for CPU in Deep Learning Inference
The model we submitted improved both the throughput performance of ResNet-50 by a factor of 16.8x as well as delivered a +1.74% boost in accuracy. This was achieved through the synergy between Intel’s OpenVINO ™ compiler and Deci’s AutoNAC-generated DeciNets models.
This marks another significant milestone in the ongoing Deci-Intel collaboration towards enabling deep learning outstanding inference on CPUs. This major increase both in accuracy and throughput has numerous direct implications.
With DeciNets, tasks that previously could not be carried out on a CPU, because they were too resource intensive, are now possible. Additionally, these tasks will see a marked performance improvement: by leveraging DeciNets, the gap between a model’s inference performance on a GPU versus a CPU is cut in half, without sacrificing the model’s accuracy.
Deci’s AutoNAC technology as well as its auto-generated DeciNets are ready for deployment and commercial use and can be easily integrated to support any computer vision task on a wide range of hardware types.
Configuration Details
c6i.2xlarge
8 vcpu (Intel® Xeon® Platinum 8375C Processor), 16 GB total memory, bios: SMBIOS 2.7, ucode: 0xd000331, Ubuntu 18.04.5 LTS, 5.4.0–1069-aws, gcc 9.3.0 compiler. Baseline: Resnet50, Accuracy=76.4; DeciNet, Accuracy=78.14
c6i.16xlarge
64 vcpu (Intel® Xeon® Platinum 8375C Processor), 128 GB total memory, bios: SMBIOS 2.7, ucode: 0xd000331, Ubuntu 18.04.5 LTS, 5.4.0–1069-aws, gcc 9.3.0 compiler. Baseline: Resnet50, Accuracy=76.4; DeciNet, Accuracy=78.14
m5zn.6xlarge
24 vcpu (Intel® Xeon® Platinum 8252C Processor), 96 GB total memory, bios: SMBIOS 2.7, ucode: 0x500320a, Ubuntu 18.04.5 LTS, 5.4.0–1069-aws, gcc 9.3.0 compiler. Baseline: Resnet50, Accuracy=76.4; DeciNet, Accuracy=78.14
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
This was first published here.









