Deci has set a record for NLP model inference efficiency and delivered a record-breaking throughput performance of more than 100,000 queries per second on eight NVIDIA A100 GPUs while also delivering improved accuracy.
TLDR;
- Deci delivered unparalleled natural language processing (NLP) throughput efficiency outperforming other MLPerf submitters within the BERT 99.9 category on NVIDIA A30, A100 & H100 GPUs.
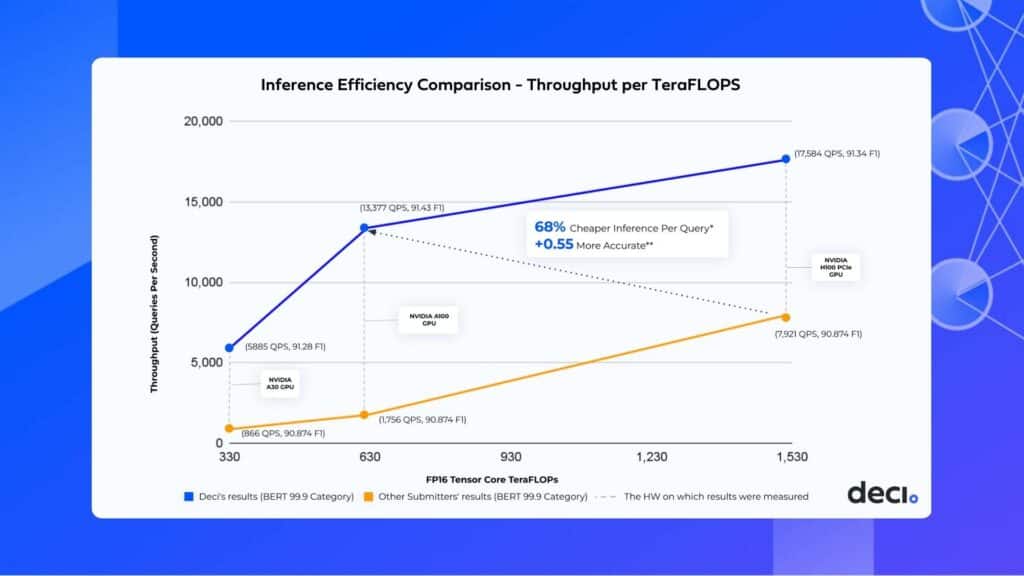
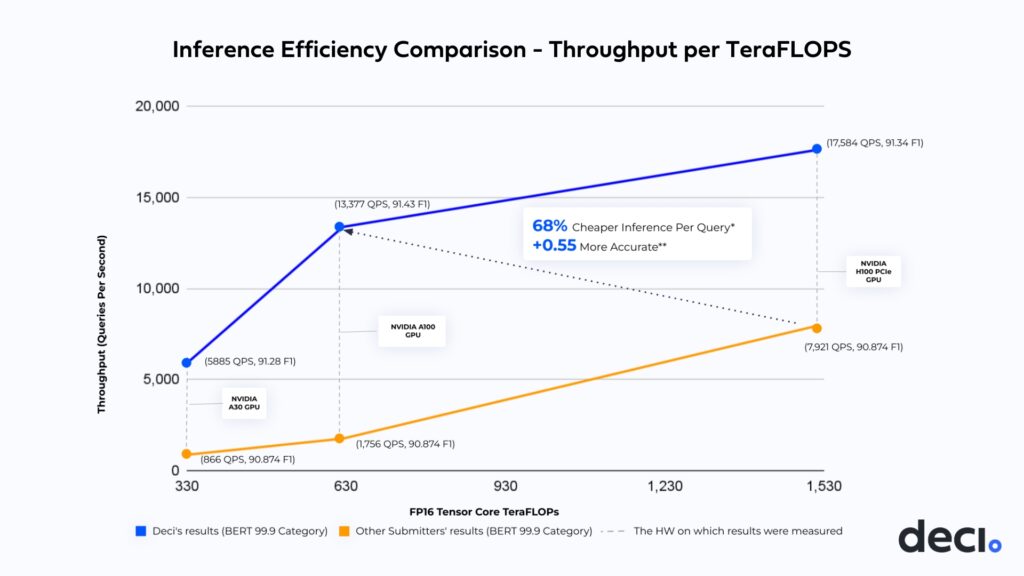
- Deci’s throughput on A100 outperforms other submitters’ results on the NVIDIA H100 GPU by 1.7x (H100 GPU is ~2.4[1] more powerful than the NVIDIA A100 GPU) and more than 7x higher throughput than other submissions on A100.
- This means that ML teams can save approximately 68%[2] of their inference costs while also improving the speed and accuracy of their models.
- Teams can use Deci’s platform and NLP models to easily accelerate their inference performance targets and reduce inference cloud costs while maintaining or improving their models’ accuracy.
What is the MLPerf Benchmark?
The MLPerf provides standardized benchmarks for evaluating the training and inference performance of machine learning systems on-premises and on cloud platforms. Its goal is to provide developers an objective way to evaluate and compare software frameworks, hardware architectures, and cloud platforms for machine learning.
An initiative of the MLCommons organization, a consortium of AI leaders from more than 30 organizations across academia, research labs, and industry, the MLPerf regularly holds new tests to continue to evolve and stay on top of cutting-edge industry trends.
The Importance of Inference Efficiency in Natural Language Processing
Large language models (LLMs) such as BERT have been growing exponentially in complexity and size by as much as 10x every year. Luckily, there’s a wide range of pretrained LLMs that are available for download and require little or no training at all. Unfortunately, these LLMs still need to run in production and the increasing size and complexity make them difficult and costly to use in a variety of NLP use cases. To address this, models must be cheaper to run, and efficient across various parts of the inference pipeline.
Interdependent factors including latency, throughput, model size, accuracy, memory footprint, and cost, must be considered to ensure not only optimal performance but also cost-efficient inference. Improving inference efficiency is necessary for models to be useful in real-world scenarios. It can also have a significant impact on the bottom line for organizations that deploy natural language processing models.
Achieving inference efficiency matters because it enables:
- Accelerated product adoption. Inference performance directly affects the user experience. Slow inference time can lead to a frustrating user experience, which can negatively impact adoption rates. Faster, real-time inference time, on the other hand, leads to a smoother user experience, which can improve adoption rates and overall user satisfaction.
- Reduced cloud inference cost. Leveraging techniques for faster inference and reducing memory footprint lead to increased savings for production deployments of NLP models.
- Faster development cycle. By reaching efficient inference performance that fits production requirements, organizations prevent being too late to the market, or losing market share to the completion.
- Less carbon emissions. Ensuring that the model and inference pipeline are designed to reach their optimal performance and run cost-efficiently in production leads to energy-efficient processing that reduces the embodied carbon per unit inference.
Deci Achieved Record-Breaking NLP Inference Speed on NVIDIA GPUs at MLPerf
The MLPerf is a great opportunity to further demonstrate Deci’s inference efficiency techniques and model generation and design technology based on neural architecture search called Automated Neural Architecture Construction (AutoNAC).
Deci’s MLPerf submission was made under the offline scenario in MLPerf’s open division in the BERT 99.9 category. The goal was to maximize throughput while keeping the accuracy within a 0.1% margin of error from the baseline, which is 90.874 F1 (SQUAD).
Powered by its proprietary AutoNAC engine, Deci leveraged its deep learning development platform to generate model architectures tailored for various NVIDIA accelerators and presented unparalleled performance on the NVIDIA A30 GPU, NVIDIA A100 GPU (1-unit and 8-unit configurations), and NVIDIA H100 GPU.
Now, the results:
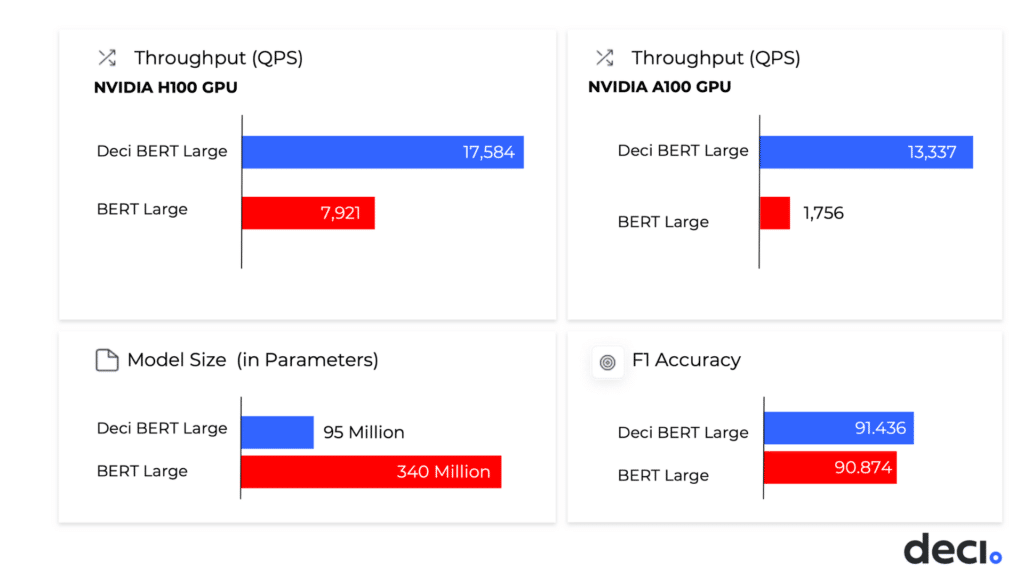
- Deci’s NLP model, called DeciBERT-Large, delivered a throughput performance of over 100,000 queries per second on eight NVIDIA A100 GPUs while delivering improved accuracy, surpassing the submissions made on even stronger hardware setups.
- The DeciBERT model also achieved unparalleled throughput and accuracy performance on the NVIDIA A100 and NVIDIA H100 GPUs. With Deci, ML engineers can achieve higher throughput on one H100 card than on eight NVIDIA A100 cards combined. In other words, teams can replace eight NVIDIA A100 cards with just one NVIDIA H100 card, while getting higher throughput and better accuracy (+0.47 F1). This transition from multi-GPU to a single GPU means lower inference cost and reduced engineering efforts.
- On the NVIDIA A30 GPU, which is a more affordable GPU, Deci delivered accelerated throughput and a 0.4% increase in F1 accuracy compared to an FP32 baseline. By using Deci, teams that previously needed to run on an A100 GPU can now migrate their workloads to the NVIDIA A30 GPU and achieve 3x better performance for roughly a third of the compute price. This means dramatically better performance for significantly less inference cloud cost.
| Hardware | Other Submitters’ Throughput | Deci’s Throughput | BERT F1 Accuracy | Deci Optimized F1 Accuracy | Accuracy Increase |
| NVIDIA A30 GPU | 866 | 5,885 | 90.874 | 91.281 | 0.4076 |
| NVIDIA A100 GPU, 80GB | 1,756 | 13,377 | 90.874 | 91.430 | 0.5560 |
| 8 x NVIDIA A100 GPU | 13,967 | 103,053 | 90.874 | 91.430 | 0.5560 |
| NVIDIA H100 PCIe GPU | 7,921 | 17,584 | 90.874 | 91.346 | 0.4722 |
The Secret Behind the Breakthrough NLP Inference Performance
Deci’s AutoNAC engine is based on proprietary neural architecture search technology and enables teams to develop hardware-aware model architectures tailored to reach specific performance targets on their inference hardware.
Models built and deployed with Deci typically deliver up to a 10x increase in inference performance with comparable or higher accuracy relative to state-of-the-art open-source models. This increase in speed translates into a better user experience and a significant reduction in inference cloud costs.
By building models that deliver better performance and are cheaper to run more organizations and users can harness the power of LLMs and NLP applications.
If you have an NLP use case and want to learn more about accelerating its inference performance, book a demo here.
[1] 624 vs 1513 FP16 Tensor Core TeraFLOPs for the NVIDIA A100 GPU & NVIDIA H100 GPU
[2] Inference cost savings are calculated per 1 million queries on NVIDIA A100 GPU & NVIDIA H100 GPU (PCIe) based on an hourly, on-demand rate.