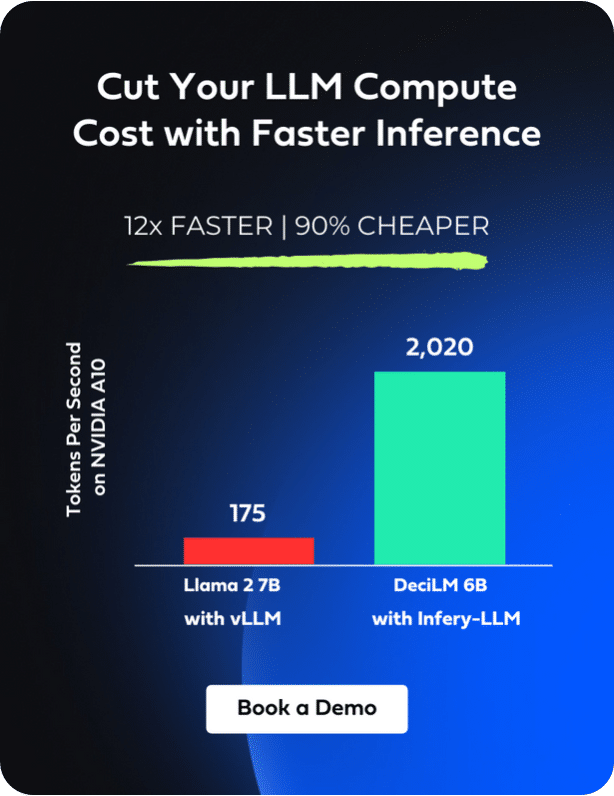
In 2023, more than 1 billion voice searches occurred each month, and current projections place the global voice recognition market at $26.8B by 2025. Behind voice search and virtual assistants like Amazon’s Alexa, Apple’s Siri and Google Assistant, are powerful advanced speech recognition (ASR) technologies used to interpret spoken language into written text. A major step forward in ASR was OpenAI’s Whisper model, first introduced in September 2022, with improved speed and accuracy over ASR models that came before. Whisper was released as an open-source model trained on 680K hours of multilingual data, and can translate, understand, and transcribe audio files in 100 languages. OpenAI recently announced Whisper v3, boasting 5 million hours of training data, improving its performance in a wide range of languages, and reducing error rates.
In this blog post, we’ll explore the applications of OpenAI’s Whisper, delving into the challenges of deploying and operating this advanced speech recognition model in production environments. We will discuss how Deci’s Infery can optimize and deploy Whisper, enhancing its efficiency and speeding up inference.
Applications of Whisper
Whisper’s training on a vast and diverse dataset enables it to proficiently handle a wide range of languages, accents, and dialects, maintaining high accuracy across a variety of speech patterns and conditions. This accuracy is not just limited to clear and distinct speech; Whisper also shows impressive performance in understanding speech in noisy environments or with background interference. Such a level of precision in capturing spoken words and nuances makes Whisper a highly reliable tool in applications where accurate speech-to-text conversion is critical.
Representing a significant advancement in ASR with its multitasking capabilities, Whisper can perform language identification, transcription, and translation. Its capabilities can extend even further with fine-tuning, enabling contextual understanding, identifying idiomatic expressions, and even perceiving subtle differences in tone and emotion. These capabilities unlock a wide array of applications, from enhancing content creation to improving accessibility services and refining the functionality of voice assistants.
Voice-Activated Systems and IoT Devices
Whisper’s advanced speech recognition capabilities allow for highly accurate interpretation of spoken commands, crucial for the seamless operation of voice-activated systems and smart devices. Due to Whisper’s ability to handle a variety of languages and dialects, devices become more accessible and user-friendly. Whisper’s proficiency in deciphering context and nuance in speech is particularly beneficial for complex command structures, allowing devices to understand and execute multi-step instructions or queries with higher precision.
Transcription services
Using OpenAI’s Whisper for transcription services opens up a myriad of possibilities across various sectors. Its pretrained transformer architecture enables the model to grasp the broader context of sentences transcribed and “fill in” the gaps in the transcript based on its understanding:
- Accessibility: Creating tools for people with hearing impairments or speech difficulties
- Podcasts: Transcripts of episodes for accessibility, audience engagement, and SEO enhancement.
- Journalism and Media: Transcribing interviews, press conferences, and speeches for content creation and editing.
- Legal Sector: Transcribing court proceedings, depositions, and legal consultations for precise and searchable legal records.
- Healthcare: Fine-tuned Whisper models excel at transcribing patient consultations, medical procedures, and doctor’s notes for accurate medical documentation and record-keeping.
- Global Business: Transcribing multilingual meetings and international conferences, aiding in communication across different languages.
- Entertainment: Transcribing film and television content for subtitles and closed captions, enhancing accessibility and viewer experience.
Customer Support
Whisper’s ability to accurately transcribe speech into text is particularly beneficial for call centers and online customer service platforms. Whisper can transcribe customer calls from recorded audio, providing valuable textual records of customer interactions. This assists in quality assurance, training, and compliance monitoring, enabling efficient review and analysis of customer interactions.
Additionally, Whisper’s multilingual proficiency allows it to transcribe and understand conversations in various languages, an indispensable feature in today’s global marketplace. The model’s advanced neural network architecture, trained on a vast array of speech patterns and dialects, ensures high accuracy even in noisy environments typical of call centers.
Whisper can also integrate with analytics tools, providing deeper insights into customer sentiments, queries, and feedback. This integration facilitates improved customer service strategies and more personalized customer experiences. Moreover, the transcription data can feed into AI-driven analytics for pattern recognition and trend analysis, helping businesses understand common customer issues and improve their services.
OpenAI’s Whisper and LLMs for Speech-Based Interactions
Combining Whisper with Large Language Models (LLMs) opens up exciting possibilities for speech-based interactions and applications. OpenAI’s Whisper serves as the gateway by accurately transcribing spoken language into text. This transcribed text can then be fed into an LLM, which excels in understanding and generating human-like text. The synergy between Whisper’s transcription accuracy and LLMs’ deep understanding of language nuances creates a powerful tool for various applications.
For instance, in customer service, this combination can facilitate automated, conversational agents capable of understanding customer queries through speech and generating contextually relevant and coherent responses. In accessibility technology, it can transform spoken input into detailed, context-aware written or spoken responses, aiding individuals with visual impairments.
In the realm of smart assistants and IoT devices, integrating Whisper with an LLM can lead to more natural, efficient, and accurate voice interactions, as the LLM can process transcribed speech to perform tasks, answer questions, or control smart devices based on user commands.
Balancing Accuracy, Speed and Cost
While Whisper demonstrates remarkable accuracy, the base Whisper model has limitations, especially when it comes to building and deploying real-time, UX-first and production-grade applications.
Offered in five model sizes, ranging from 39 million to over 1.5 billion parameters, Whisper’s varying sizes present a trade-off between accuracy, processing speed, and computational cost in production environments. The larger models offer higher accuracy and have a greater capacity to learn and recognize a wider range of speech patterns, accents, and nuances. However, this high level of accuracy comes at the cost of increased processing time. The larger the model, the more computational steps are required to process each segment of audio.
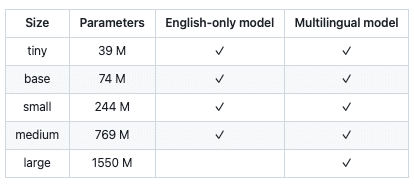
To mitigate this slowdown and enhance processing speed, additional computing resources are required. This involves not just more powerful CPUs or GPUs, but also potentially more memory and storage to handle the larger model size and the data it processes. The computational intensity of these larger models manifests in greater energy consumption and higher operational costs, particularly when processing large volumes of audio data or requiring near-real-time transcription. On the other hand, the smaller versions of Whisper models, while less taxing on computational resources, are primarily efficient in English and a limited number of other languages. They offer quicker transcription but at the expense of reduced accuracy and a diminished capacity to manage complex speech scenarios.
Optimizing OpenAI’s Whisper with Infery
With the expansive range of applications offered by Whisper, many companies are exploring ways to integrate it into their systems to enhance efficiency, accuracy, and user experience across various domains. This involves technical considerations like adapting Whisper’s neural network architecture to fit specific use cases, optimizing its performance for different languages and dialects, and ensuring seamless integration with existing IT infrastructure. Businesses are also assessing the computational requirements and scalability needed to deploy Whisper effectively, especially in high-demand environments.
To overcome the challenges of deploying and running Whisper in production, Deci offers Infery, an inference runtime engine for large, complex foundation models like Whisper. Engineered to enhance performance, Infery’s comprehensive library includes advanced techniques for compiling and optimizing models for inference, from quantization to pipeline orchestration. Enabling inference with just three lines of code, Infery makes it easy to deploy into production on various hardware, frameworks, and environments.
In the case of a chatbot development company using Whisper to build a real-time transcription application for customer service call centers, Infery was used to reduce latency by 1.92x compared to other inference tools–with no degradation of accuracy.
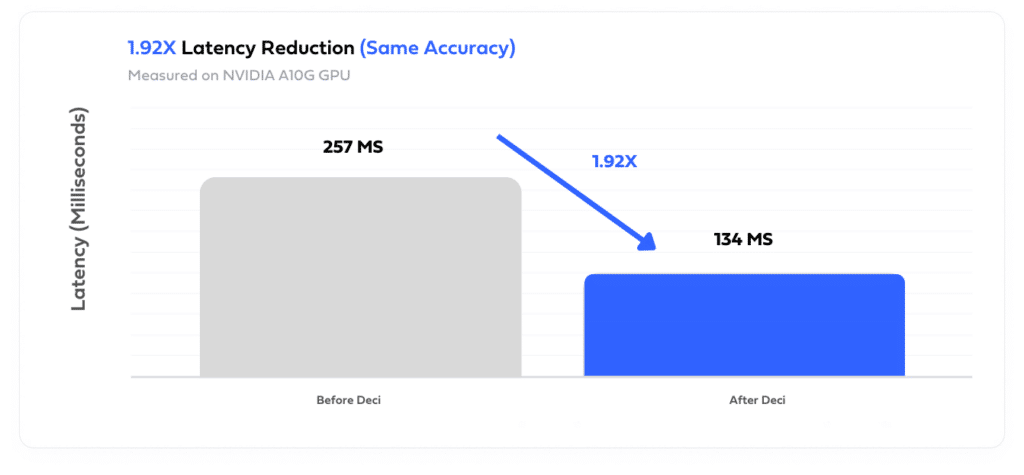
Deci’s diverse customer base is finding innovative ways to utilize Whisper for transcription needs. For instance, one customer applied Whisper to transcribe medical dialogues between doctors and patients and was able to reduce annual compute costs in half by reducing latency through the use of Infery.
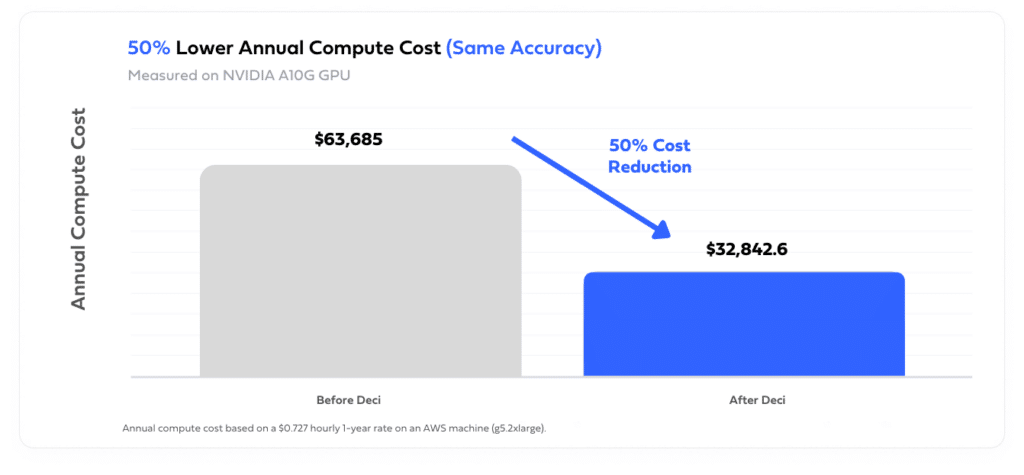
A key element in optimizing Whisper’s performance in these varied applications is Infery, which boosts efficiency and allows the model to operate on less powerful, smaller GPUs. This adaptation not only makes the process more affordable but also more environmentally friendly. In a specific case, the integration of Infery enabled a customer to deploy their Whisper model on an A10G GPU, a more economical option compared to the higher-end A100, thereby significantly reducing their computational expenses.
How does Infery Work?
Most common inference engines and various optimization techniques that exist offer limited support for Whisper’s specific architecture and operations. Applying them to Whisper often requires substantial effort and expertise. However, Infery provides an inference engine and SDK that makes it easy for developers to maximize the acceleration potential of Whisper’s complex architecture.
Efficient Compilation
Infery employs a unique approach to compile Whisper models by segmenting the transformer blocks, a key component of the model’s architecture, into three main blocks. This segmentation allows for more targeted and efficient compilation. Each block is compiled separately, enabling specific optimizations tailored to the distinct characteristics and computational demands of each segment. This process not only streamlines the compilation but also allows for more effective management of the model’s complexity. After the separate compilation of these blocks, they are then gathered and orchestrated. This reintegration is crucial as it ensures that the optimized blocks function coherently, maintaining the overall integrity and performance of the Whisper model. By splitting and then reassembling the transformer blocks, Infery effectively tackles the challenges posed by the large size and complexity of Whisper, optimizing it for better performance without compromising its transcription accuracy and capabilities.
Selective Quantization
The selective quantization approach of Infery is particularly effective when applied to Whisper. It involves strategically applying FP16 (16-bit floating point) or INT8 (8-bit integer) quantization to specific layers of the Whisper model that are more receptive to quantization. This method allows for a significant boost in processing speed for these layers, as lower bit quantization can be computed more rapidly.
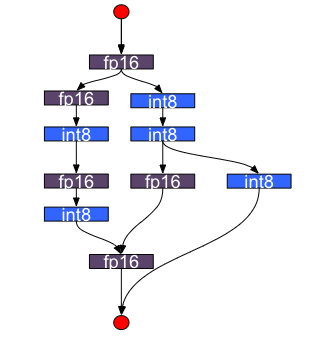
Crucially, this is achieved without broadly reducing the precision across the entire model, which could compromise the overall quality and accuracy of speech recognition. Layers that are less amenable to quantization or where higher precision is essential to maintain the integrity of the model’s output, are retained in their original FP32 (32-bit floating point) format. This selective application ensures that the critical elements of Whisper’s neural network continue to operate with the high fidelity required for complex speech recognition tasks. As a result, Infery enables Whisper to benefit from the accelerated performance that quantization offers, while still preserving the essential FP32 quality in parts of the model where it’s most needed.
How to use Infery to Boost Whisper Performance:
Infery is a Python runtime engine that lets you quickly run inference locally with only 3 simple commands. Infery supports all major deep learning frameworks with a unified and simple API.
Start by importing your Whisper model and tokenizer, set your optimization parameters, initiate optimization, and let Infery do the heavy lifting for you:
from ffm.models.whisper.model import OnnxEncDecModel # Initialize model_name = "models/whisper-large-v3" model = OnnxEncDecModel(model_name) processor = WhisperProcessor.from_pretrained(model_name) # Transcribe input_features = processor(audio, sampling_rate=sampling_rate, return_tensors="pt").input_features predicted_ids: List[Tensor] = model.generate(input_features) transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
Conclusion
OpenAI’s Whisper, enhanced by Deci’s Infery, offers a formidable combination for anyone looking to harness the power of advanced speech recognition in their applications. Whether it’s for creating more efficient customer service platforms, developing assistive technologies, or improving the functionality of smart devices, Whisper, optimized with Infery, stands ready to revolutionize the way we interact with and process spoken language.
For those interested in experiencing the full potential of OpenAI’s Whisper in their applications, we invite you to book a demo of Infery. Discover how this innovative technology can elevate your operations, streamline your processes, and bring your voice recognition capabilities to the next level.