

AutoML is a relatively new and exciting concept in the machine learning arena. The term AutoML sounds straightforward: automating the process of building a machine learning production model, given a specific input data and task. But, to date, there is no widely-accepted definition of AutoML, and the industry is using this term to refer to many different things.
The recent approach in deep learning (DL) research and practice has simplified some of the ML pipeline challenges, such as feature engineering and selection. Then again, DL has also complicated the ML pipeline by adding more hyper-parameters, such as choice of architecture and training regime, and by requiring more labeled training data.
The purpose of this article is to provide an overview of the ML pipeline in the context of DL, and propose a graded definition that will allow practitioners and researchers to use the term Deep-Learning-AutoML (DL-AutoML) with more precision. First, let’s look at the major steps in the pipeline for creating a deep learning production algorithm.
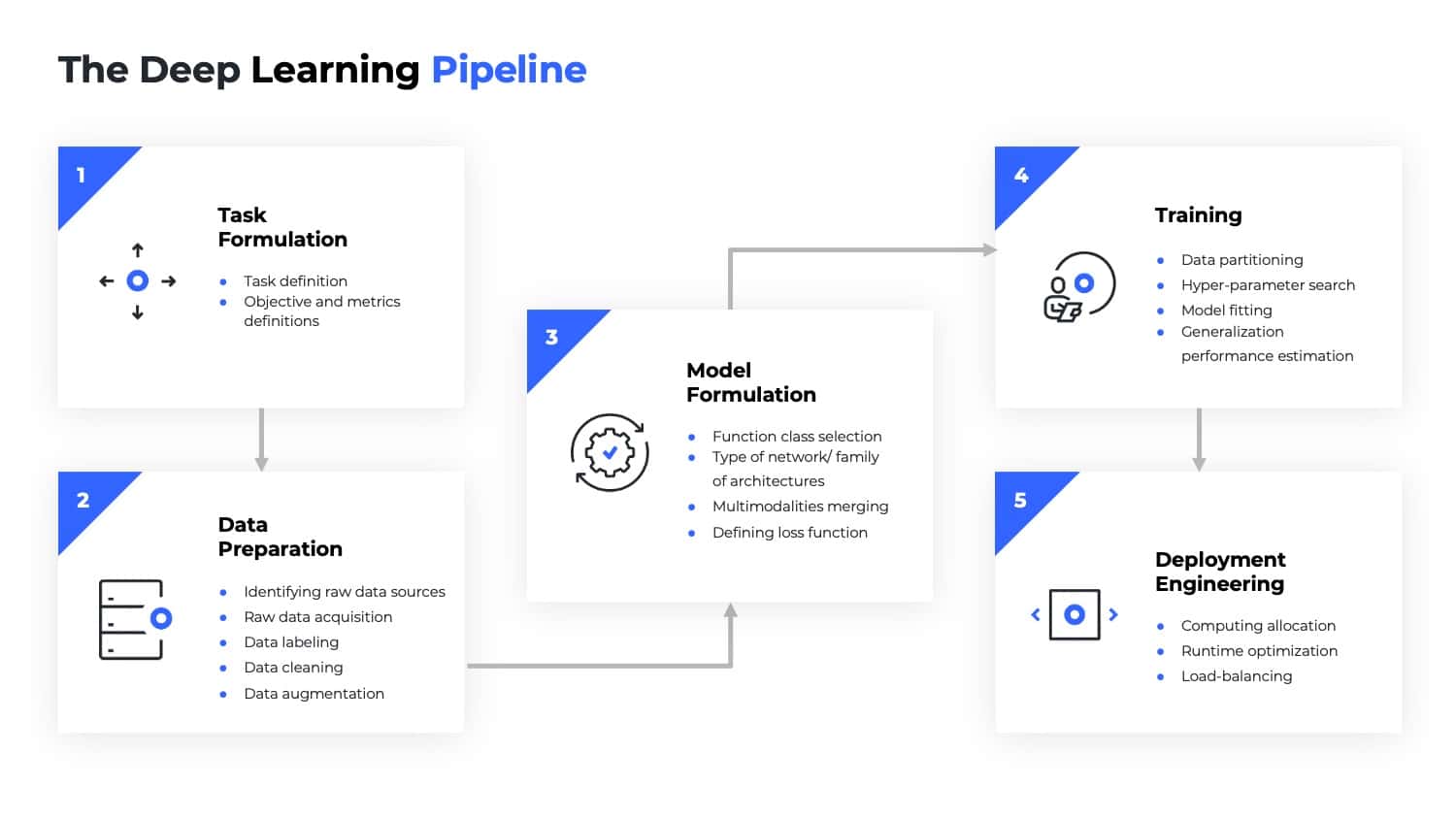
1. Task formulation
The first challenge when applying ML is to define the task and objective we would like to accomplish. For example, we might want to do classification, regression, retrieval from a database, and so on. This step also includes defining metrics and objectives that designate success and failure.
2. Data preparation
This step begins with identifying raw data sources and raw data acquisition. It then moves on to the process of data labeling. Once the data is labeled, an additional data cleaning step is applied to remove outliers and incorrect labels. Further preparations may include balancing the classes (if the data distribution is imbalanced), normalization, formation of training and test partitions, and so forth. Data augmentation is another step that can be used to enrich the dataset. Finally, a data quality analysis is used to verify that the DL pipeline gets the best input possible.
3. Model formulation
When using DL algorithms, we generally need to perform function class selection. This step includes selecting the type of neural network/ family of architectures (e.g., CNN, RNN, FC) and choosing an effective architecture (e.g., ResNet, MobileNet, EfficientNet, etc). Moreover, if we are dealing with multi-modality, we need to decide how the information will propagate from the different modalities to higher parts of the network. As part of this step, we must choose the correct loss function, a decision that can greatly impact the quality of our final results.
4. Training
This step includes the actual training phase. It starts with partitioning the data into test, validation, and train sets. Next, we apply a hyper-parameter search to select the optimal parameters for the model, including the learning rate, width, depth, and so forth. At the end of this step, we fit the model and then monitor its generalization performance on the validation and test data.
5. Deployment engineering
Given a trained model, our ultimate goal is to incorporate it into a production environment. This includes the process of allocating computing resources for both loading and preprocessing data, as well as the inference itself. In many instances, this step also requires designing and implementing load-balancing between the computation performed for data processing and inference. In real-time applications, this step should include the optimization of inference running time to adjust various parameters for the existing hardware, such as batch size, operation types, and memory usage.
6. Performance monitoring
Once our model is deployed in a production environment, it is essential to monitor its operation, utilization, and performance. In many applications, an essential part of this monitoring is an online assessment of the pointwise uncertainty of the model, and the ability to detect distributional shifts.
Having outlined the essential components of the DL pipeline, it becomes easier to define the levels of automation for DL-AutoML.
The main goal of DL-AutoML is to make deep learning accessible to all, from individuals to small startups and large corporations. The word accessible is pivotal in this context. Ideally, the DL-AutoML pipeline should (1) Be affordable (2) Have no requirement for high-level expertise (3) Be robust and accurate. This approach gives us a coarse division of the automation levels in the pipeline. Each sub-step will be prioritized according to the level of expertise it requires, provided that the step can be replaced with a robust automatic solution.
For example, choosing the correct architectural hyperparameters for a task requires a high level of expertise. However, this step can be replaced with a neural architecture search (NAS) that potentially offers a robust solution; therefore, it gets high priority for automation. Another example is data labeling, which in most applications is not very expensive and doesn’t require a high level of expertise. That said, we aren’t aware of a solution that can automate data labeling in a way that is robust enough for a wide range of tasks. In this spirit, we now define the DL-AutoML levels of automation and offer typical examples for each level.
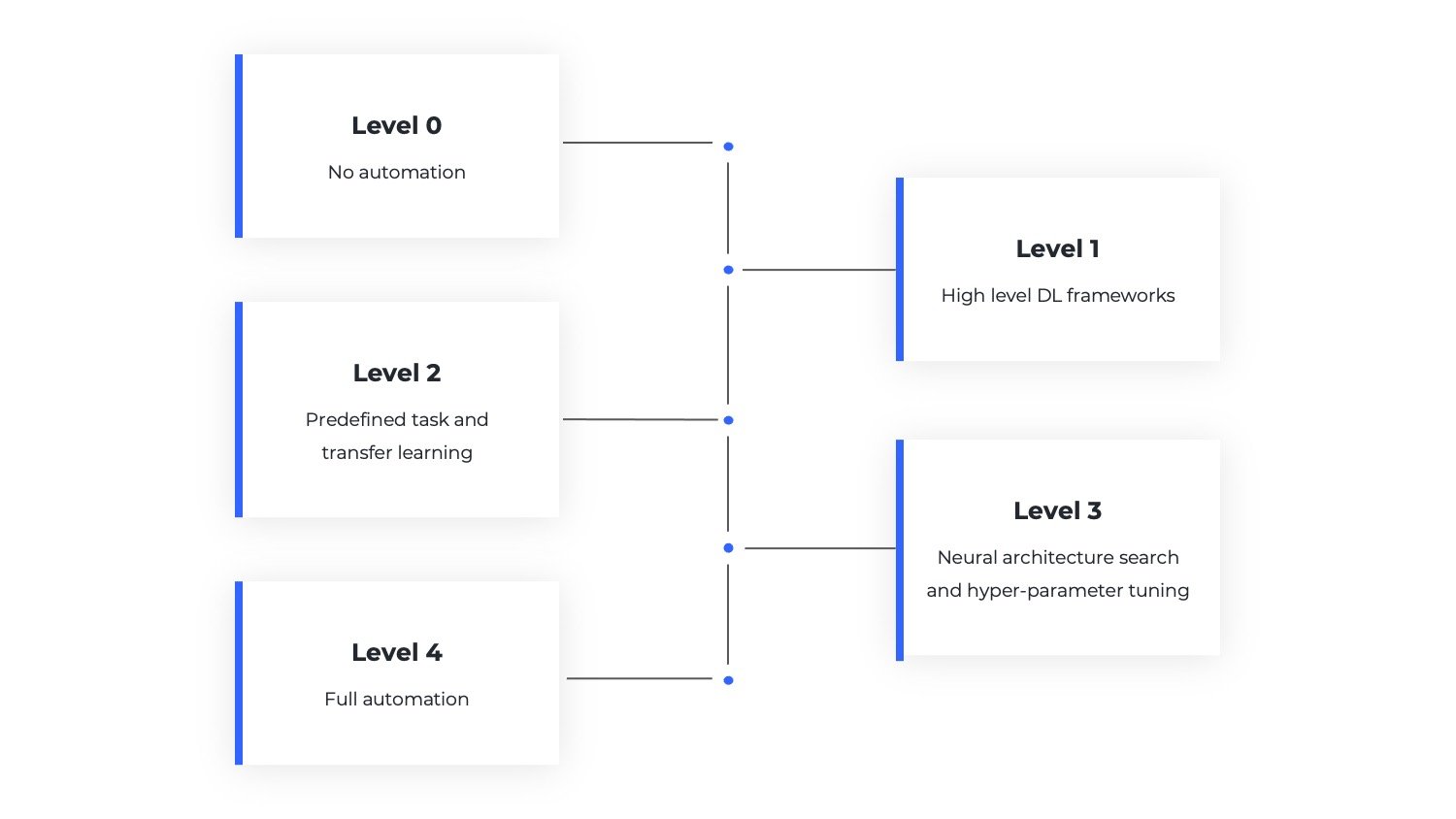
Level 0 – No automation, custom implementation of the deep learning pipeline
To a large extent, this automation level is historic and refers to the beginning of the deep learning era, before the advent of high-level frameworks such as Caffe, TensorFlow, and PyTorch. At that time, practitioners needed to implement the deep learning pipeline by themselves, usually relying on low-level languages such as C++. At this automation level, users program their neural networks, optimizers, loss functions, data loaders, and so on. Other elements in the ML pipeline such as data handling, architecture search, and hyper-parameter tuning are done manually with human foresight. The process of coding a neural network from scratch is error prone and requires a solid background in mathematics, programming, and algorithms. The profound mastery required at this level, and the success of deep learning, led to the emergence of high-level libraries, which is next in our levels of automation. Although it is within the context of familiar tasks, this automation level is indeed “historic”. Level 0 automation is not available when we look at completely new types of networks and hardware (and data) that are not supported in available frameworks.
Typical example: Suppose we would like to implement a binary neural network in which each weight and activation is binary, namely, either minus one or one. The advantage is that such networks have the potential to use much less energy for operation. This scenario requires a custom implementation, which is best done using a logic gate such as Not-Xor (Xnor) and a population count operation. Such logic gates and operations are not widely used in neural networks and therefore not available in high-level frameworks such as PyTorch, TensorFlow, Caffe, etc. The most efficient implementation will be a custom program that runs the procedure described above in a low-level programming language.
Level 1 – High level DL frameworks
This is the most widely used level of automation. Rather than using low-level programming languages, the user implements DL models and pipelines using higher level frameworks (e.g., Caffe, TensorFlow, PyTorch, etc.), which abstract the neural networks and work flows in terms of layers, connectivity, and optimization. Such frameworks give users the flexibility to write custom networks, optimizers, loss functions, and more, all of which are formulated to run efficiently on common hardware devices such as GPUs. These libraries greatly reduce the level of expertise required to construct and deploy reliable DL models. Today, most DL developers rely on this level of automation. However, this level still requires sufficient proficiency in programming and in DL, which usually requires at least a master’s (or equivalent) degree in the field to develop non-standard models.
Typical example: Let’s say we have a sensor that provides a new kind of data, unlike any existing kind. An off-the-shelf solution will typically not work if our goal is to generate a prediction for this new kind of data. For high quality predictions, we might decide to build a custom network with a new architecture or even a new family of architectures. To this end, assuming the custom network uses general operations, the best solution will be to program the neural network using high-level frameworks.
Level 2 – Solving predefined tasks and transfer learning
There are many tasks in supervised machine learning that are considered solved. For example, classification in the context of vision, object detection, sentiment analysis, semantic segmentation, and more. In this level, it is assumed that the task of interest, or a similar one, has been solved in the past. Therefore, it is possible to use pre-trained models together with transfer learning to achieve an accurate solution for the comparable task. In such cases, we can take a trained model (e.g., from an open source repository) that is programmed within one of the high-level frameworks described in Level 1 (e.g., PyTorch). Then, some labeled data for the new task is gathered and the trained model is “fine-tuned” with additional training on the new data. Operating at this level still requires an engineer to preprocess the data and correctly perform the fine-tuning. Nevertheless, the required level of expertise is basic and can be accomplished entirely by non-experts. The limitation at this level of automation is the restriction to use known models. If the model doesn’t work well, the user needs to go back to Level 1, which requires an in-depth knowledge in programming and DL as explained above.
Typical example: Let’s assume we would like to detect pedestrians in a stream of images, and draw a bounding box around every person in the image. This task was solved in the past and the YOLO framework provides highly accurate results for such tasks. To build a model that fits the new data, all we have to do is take a pre-trained YOLO model and fine-tune it using a dataset, such as the Caltech pedestrian detection benchmark. In most cases, this approach yields results that are satisfactory in terms of accuracy.
Level 3 – DL-AutoML with neural architecture search and hyper-parameter tuning
The goal of this level is to make the predefined solutions mentioned in Level 2 available for a wider range of tasks. Here, users define their tasks and provide labeled data. When possible, the data preprocessing is done automatically by predefined algorithms. Given the cleansed data, a function class is automatically selected based on the kind of data input. The type of neural architecture is automatically chosen based on the task formulation. Then, the final architecture is also automatically determined by a neural architecture search (NAS); here, many possible architectures are considered and tested to select the most effective architecture for the task at hand (e.g., achieving the highest accuracy). After the architecture is established, an additional step is carried out for hyper-parameter tuning. NAS is not a magic bullet, but will deliver a decent solution—provided it has the prior knowledge needed to reduce the size of the search space. Due to this limitation, there are tasks that NAS is incapable of solving, a fact that is aligned with the ‘no free lunch’ theorem. If the desired accuracy was not achieved, a human must intervene to determine whether there is a problem in the data, in the learning algorithm, or in the learnability of the problem. In most cases, any data issues can be solved by providing additional data. However, model issues require the user to go back to Level 1.
Typical example: Let’s assume we are given a classification task on medical images. In this case, there is no off-the-shelf model we can use. Nevertheless, this kind of data was analyzed in the literature so we have some prior knowledge about the family of architectures required and weak prior knowledge about the desired network architecture. Leveraging this, we can use a NAS to search within a large set of candidate networks, and automatically return an effective one. It is also possible to use a grid search, or better yet Bayesian optimization, to optimize other hyper-parameters of the model.
Level 4 – Full automation, DL-AutoML on any give task
At this level, the entire deep learning pipeline is carried out automatically. The user delivers task formulation and data, and there exists a meta-model that can define the prior knowledge needed for this data and task. Although this kind of meta-model does not yet exist, we believe such models are essential if we are to reach full automation of the DL-ML pipeline. Let’s take a closer look at why. Initially, deep learning was used only with simple architectures, such as fully connected ones. Then, AlexNet introduced the convolutional neural networks (CNNs) for image classification, which achieved state-of-the-art results on image classification. These CNNs achieved superior results over fully connected networks because they encoded some prior knowledge that was needed to analyze the images. Based on research and a high level of understanding of the kind of data, similar prior knowledge has been found for text in LSTM, for sound in CNN, and for temporal data in RNN.
At Level 4 of DL-AutoML, the prior knowledge required for a specific data and task is encoded by some meta-model. Given training data, this meta-model is capable of inventing the family of architectures needed for the task at hand, and can offer prior knowledge on the architecture hyper-parameters. Using this knowledge, a NAS procedure can be applied to automatically find the best model for the problem.
Conclusion
The goal of DL-AutoML is to simplify the use of deep learning and to make the incredible power of DL accessible to everyone. In recent years, certain automation levels of DL-AutoML have become widely used and are offered by many tech companies.
This article provides a tiered definition of the term Deep Learning-AutoML. We first defined the various stages needed to bring a DL algorithm from idea to production. Then we used these steps to define the different levels of automation for DL-AutoML. We believe that this field will continue to grow. Eventually, deploying deep learning will be done in the press of a button. To read about Deci’s developments in the field of Deep Learning-AutoML, download our whitepaper, or book a demo with us.









